


Using Pure Storage products, you can accelerate the data-recovery process for a Perforce database in case of disaster. My previous post details the advantages of the hybrid architecture for Perforce on Pure Storage in which:
- The version files in the Perforce depot are configured on the Pure FlashBladeTM for scalability, throughput, and manageability.
- The Perforce database is set up on FlashArrayTM for excellent low-latency performance.
Protect the Perforce depot by taking regular file-system snapshots on the FlashBlade for data recovery. The Perforce database consists of metadata information about source-code changes plus the location of version files in the different production, development, and release branches. The traditional way to protect the database is to take a Perforce checkpoint by rotating the journal logs.
Depending on your business requirements, you may not take these checkpoints frequently. The Perforce checkpoint locks the database and makes it inaccessible until the process is complete. To mitigate this, Perforce recommends that you have a standby copy of the database in another location that replicates whenever there is a change to the production copy. Perforce can then take an offline checkpoint without impacting production.
We did this test with a 500GB production volume with a Perforce database size equivalent to 350GB. Results included:
- Taking a traditional Perforce checkpoint from a standby location took 110 minutes. It required additional space to write the Perforce database for a standby copy and copy the changes from production.
- Copying the checkpoint file to a different location using “rsync” for migration took about 32 minutes.
- Restoring from the checkpoint took 90 minutes for the 350GB database. The recovery time objective (RTO) will increase as the size of the database is larger.
The information listed above is some of the reasons why Perforce checkpoints are not taken more frequently, which impacts the recovery point objective (RPO).
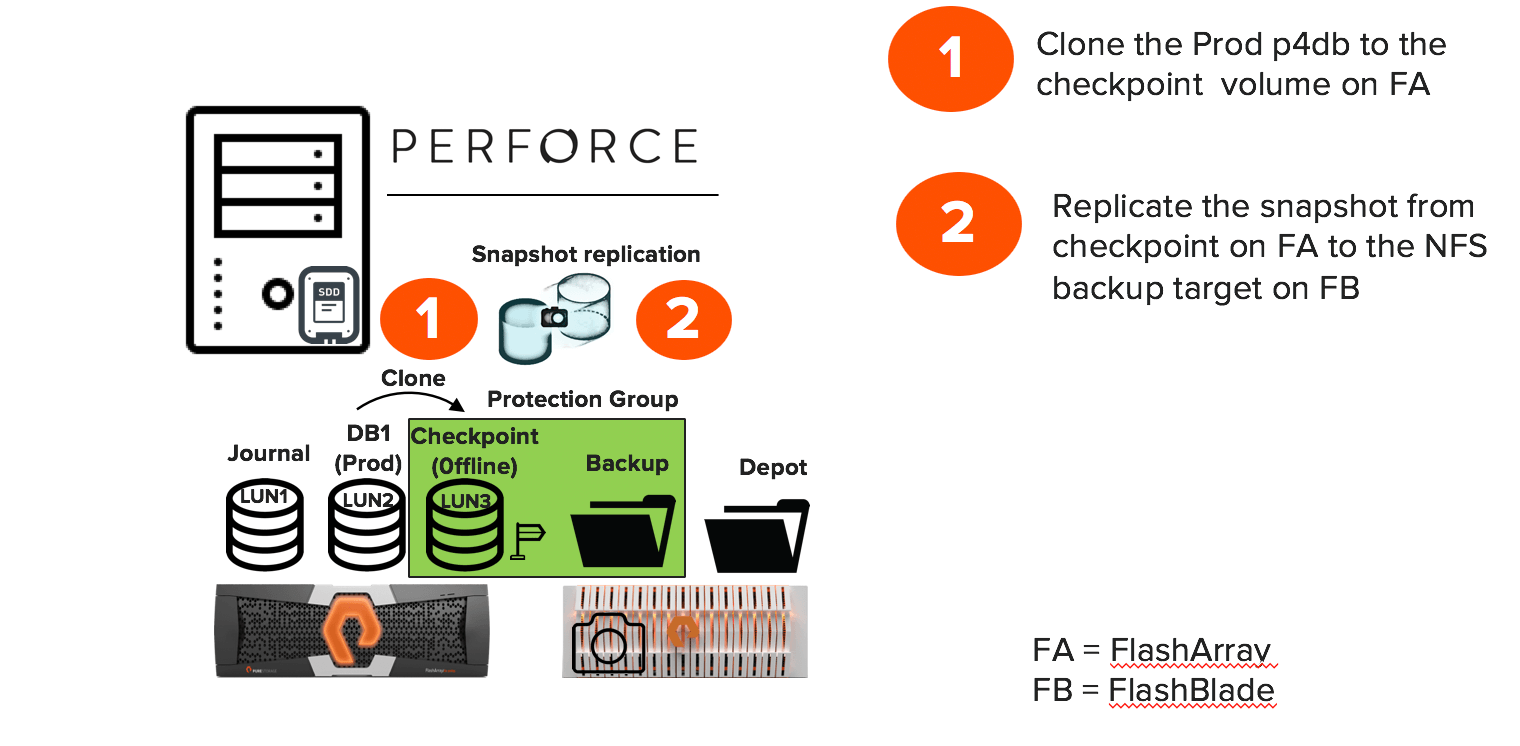
The Pure Storage Snap-to-NFS utility uses the process of snapshot mobility. You can seamlessly integrate it with the Perforce workflow using Python-based RESTful APIs on the Perforce server. This helps to take application-consistent snapshots instantly at the array level for the production volume without additional space. A “copy_volume” operation clones the read-only snapshot to another LUN on FlashArray as a read-write volume.
As illustrated in Figure 1, there is a production Perforce database volume on the FlashArray. There is also a checkpoint (stage) volume that is part of the protection group with an NFS backup target on FlashBlade. You need to configure a protection group for Snap-to-NFS to identify the source and backup target locations.
Having an application consistent copy of the production database at any given time provides the following capabilities:
- The ability to take an array snapshot of the staging volume and replicate it to an NFS backup target for archiving. The snapshot includes the metadata and all the db.* files that the production database had at the point in time the original snapshot was taken.
- There is no requirement to spend additional time for a Perforce checkpoint and you can complete the replication in under 3 minutes. You can destroy/eradicate the snapshot of the stage volume once replication is complete
- The stage volume (checkpoint volume in Figure 1) does not take too much space. There was a 9:1 data reduction reported for the 500GB volume.
- You can overwrite the staged volume every time a new snapshot is taken on the production volume. Doing so allows a higher rate of application-consistent snapshots on the production Perforce database volume to meet the RPO in case of any disaster.
If the Perforce database files get corrupted or deleted, recovering files using Snap-to-NFS accelerates reseeding of the Perforce server. Every snapshot created for the stage volume and replicated to the NFS backup target is pre-pended with the hostname along with the snapshot name. For instance, sn1-x70-d08-21:PGp4checkpoint.361 where “sn1-x70-d08-21” is the FlashArray on which the snapshot was taken and “PGp4checkpoint.361” is the name of the snapshot.
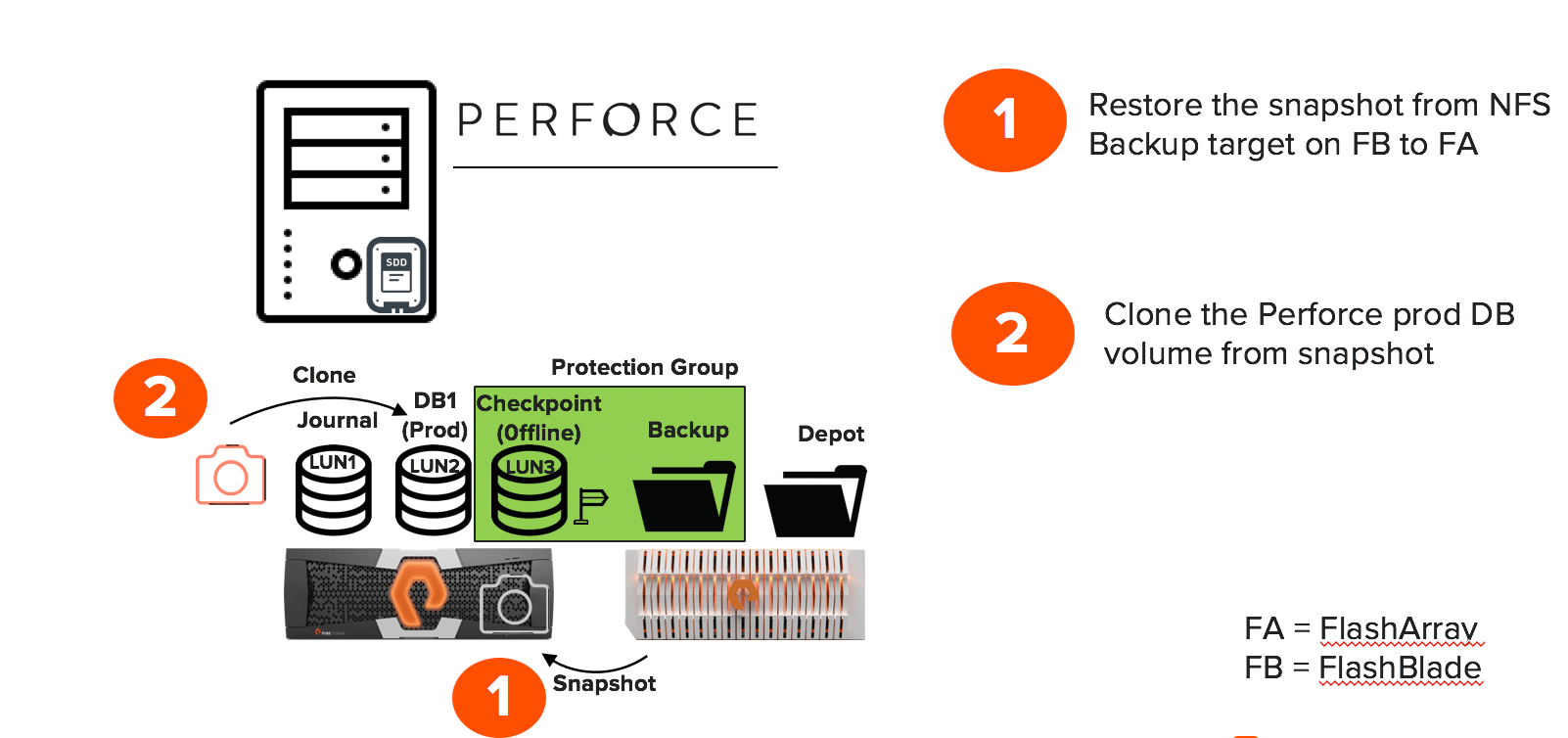
The replicated snapshot to the NFS backup is technically a volume that contains metadata and data. It is always recommended that you restore the latest snapshot from the NFS backup target to the FlashArray as preparation to recover from any database disaster. However, the most recent snapshots can still be present on the FlashArray. The older snapshots are moved to the NFS share for archival.
The most recent snapshot available on the FlashArray, can be used for recovery and high-availability operations without much run time:
- A similar “copy_volume” operation to clone the snapshot to the production Perforce database volume gets all the db.* files instantly. Stopping and restarting the Perforce database immediately brings the database online and functional in less than 5 seconds. This eliminates the 90-minute wait time to restore 350GB database from a traditional checkpoint.
- Using the snapshot, bring multiple read-only replica or edge servers to existence quickly in the Perforce setup for load-balancing and high availability.
- You can restore the snapshot to a different FlashArray if the Perforce server will be migrated to a different data center or location. Avoid the “rsync the checkpoint” and “restore from checkpoint” times and expedite reseeding the Perforce database server using Snap-to-NFS.

There are multiple ways to protect and recover a Perforce database in customer production environments. The Snap-to-NFS utility on Pure Storage hybrid architecture provides yet another efficient way to achieve faster backup and restore times for a Perforce database. Apart from the rapid data recovery process, high availability is another area that Pure provides for the Perforce database. Setting up edge servers and expediting data migrations are also a reality for a Perforce environment on Pure Storage equipment.



