

In my last blog I shared the journey of how issue detection has evolved at Pure. We also recently announced that FlashArray//M has achieved 99.9999% availability, inclusive of upgrades and maintenance, across the installed base in its first year of shipment. Pure1 Global Insight is a key ingredient in delivering this Always-On experience for our customers. In this blog I will share in more detail the architecture and operational aspects of Pure1 Global Insight, the capability behind Pure1 predictive support.
Global Insight Foundation
The main idea behind Pure1 predictive support is the fingerprinting of every issue we have previously identified. We constantly scan the live telemetry data from all Pure arrays to see if a fingerprint is matched. Finding a match results in a proactive alert to Pure Support and/or the customer to resolve the potential issue before it has any impact on the customer.
Fingerprints started as signatures for specific issues but have grown to be so much more. Some fingerprints monitor issues with the storage network or workloads on the array. Recently, we began “crowd-sourcing” anomalies: using the vast amount of telemetry data arriving from customer arrays to build models for normal operations and to identify deviations. These deviations can trigger investigations and resolutions before a single array is affected. I will discuss fingerprints in more detail in the next section. For now, let’s look at the big picture.
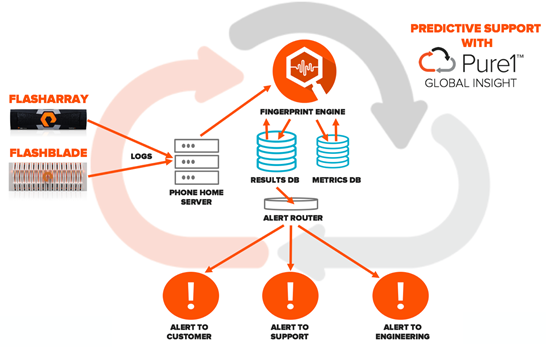
Above is a rough sketch of how Pure1 predictive support is delivered with Pure1 Global Insight:
- Logs are phoned home from customer arrays as frequently as every 30 seconds
- The logs are run against Pure’s Fingerprint Library
- The results of the fingerprints are put into the results database
- Extracted telemetry data is added to the metrics database
- The alert router determines if the newly arrived results warrant an alert and which kind:
- Alert shown to the customer
- Alert shown to Pure Support
- Alert shown to Pure Engineering
Let’s drill into the fingerprint engine itself as shown in the diagram below.
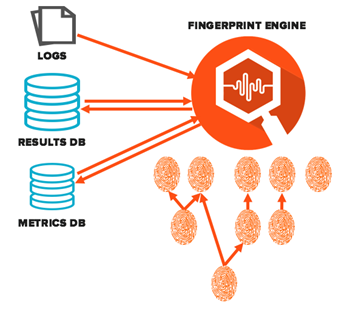
For each array, we run one instance of the fingerprint engine, processing the logs that arrived that hour for that array as well as accessing the results and metrics databases. Fingerprints are arranged as a directed acyclic graph (DAG) based on dependencies among them. As many as can be executed in parallel are launched. As parent fingerprints finish satisfying a dependency the child fingerprint is launched. All the results of the fingerprints are gathered together and inserted into the results DB. The extracted metrics data is inserted in the metrics DB. The alert router logic then runs against these new results to determine if an alert or ticket needs to be generated.
An optimization called gatekeepers is used to reduce the average runtime of fingerprints by orders of magnitude. A gatekeeper is a less computationally expensive fingerprint that checks for a certain event or conditions (such as a failover). Suppose there is a fingerprint that looks for a particular cause of a failover. There is no point in running that fingerprint if the failover gatekeeper did not find a failover in the logs. Since the failover gatekeeper is much faster than the fingerprints that it makes the system skip and since the vast majority of arrays are healthy this significantly reduces the runtime of the whole set.
Fingerprint Types / Examples
Now that you have a better understanding of how Pure1 Global Insight works and how fingerprints fit in. Let’s take some time to look at the different kinds of fingerprints that we have by focusing on a few examples.
- An issue driven fingerprint (such as an unmap stall):
We have issue driven fingerprints. For example, we discovered an issue where a rare condition would cause the space reclamation process to stall the unmapping of free data. A code change that prevents this issue was released later that day.
This issue is a perfect use case for fingerprints, since there is a natural delay before a patch is broadly installed. A fingerprint detecting the issue was deployed that same day and began monitoring all customer arrays that had not yet been upgraded.
Over the next week, two customer arrays were identified as susceptible to the condition. Because the arrays were identified as soon as the issue happened, the array space usage was never at risk. The customers were contacted and the issues were resolved without any impact.
2. A trend driven fingerprint (such as predicting fullness):
We have trend driven fingerprints, such as user created issues, including unexpected or sudden space usage on the array. This can happen to any storage array. For example, an applications admin further up the stack might change a workload without informing the IT admin. These unexpected changes can be high risk if they have an impact for a long period of time before being discovered by the IT admin, such as in the evening or on a Friday afternoon as they can run all night or over the weekend.
A fingerprint that we deployed looks at the fullness and the input data for the array over a prior period. It extracts typical patterns and seasonalities and attempts to identify the true rate at which array usage is growing. Pure1 Global Insight then asks the question: if this persists when will it hit 100%. Depending on the answer this will trigger a customer alert giving the IT admin an early heads up about a potential issue in the near future.
3. Externally driven fingerprint (such as issues outside the array):
We have externally driven fingerprints, such as fingerprints that monitor the health of the storage area network (SAN) associated with an array.
As an example, let’s consider how writes happen in fibre channel (FC). The host wishing to do a write first sends a request which contains the destination address and size of the write but not the data. The array then allocates a buffer to hold this write and sends a ready-to-transfer back to the host. Upon receiving this the host will send the data payload. The array will redundantly store the data in NVRAM and acknowledge that the write is done.
A fairly common scenario is that the host will report high latency for writes, however, the array itself is perfectly healthy. This happens to storage arrays of all kinds. The root cause is that the latency comes from a delay in between the array sending the ready-to-transfer and the host sending the payload. The root cause of this is almost always an issue with the SAN which causes the delay in between the two end-points. We collect data and have corresponding fingerprints that automatically generate alerts to identify that the latency is caused by such a scenario. Pure Support has worked with many customers to drill into and proactively resolve their SAN issues after Pure1 Global Insight has identified a SAN issue.
Try out FlashBlade
Another example where we monitor the environment outside the array is to ensure that multi-pathing is set up correctly. Checks are constantly running to ensure that a host is logged into both controllers with the same number of connections. We have encountered many situations where an alert fired, and Pure Support also reached out to tell a customer that they were no longer high availability (H/A) as something had changed with their connections. The customer has often replied that they were doing some cabling or networking changes and thought everything was done correctly. Needless to say the customer was grateful that the issue was resolved before any incident occurred that would have exposed the non-H/A state of connections.
The Benefits of Global Insight:
Having discussed the Pure1 Global Insight architecture and fingerprints, let me highlight some of the benefits of this architecture and why we built it the way we did it and the advantages that gives us.
- We send logs as soon as they are available, as such we can proactively detect and diagnose issues very rapidly, even before they occur. With other storage solutions, proactive detection of an issue is often missed. And, after an issue is detected, logs need to first be requested and transferred to their support team, which can take several hours.
- We decouple fingerprint content and infrastructure. Fingerprints are independent scripts that are not dependent on the underlying infrastructure (the infrastructure takes care of all the hard stuff). This makes the development of fingerprints very quick and efficient for our engineers. This means a rapid rate of new fingerprint creation. This also means that the underlying architecture can change and evolve without needing to modifying the content of the fingerprints.
- We are able to save significant resources by using “gatekeepers” which make it feasible to do such a large number of tests on all customer arrays every hour.
- We separate the alert firing logic from the fingerprint logic, which allows us to rapidly deploy and prototype fingerprints.
- A new fingerprint will be deployed into production only after demonstrating that it does not adversely impact the infrastructure.
- That fingerprint will then begin a validation process where its hits will be scrutinized and validated before allowing it to “go live” where it can automatically file tickets via the alert router.
Pure1 Global Insight has taken over two years of development effort and many innovations so far, but the differentiated support experience delivered with predictive support makes the journey well worth it. Pure1 Global Insight will continue to evolve and push forward harder than ever, as we move towards “zero-impacted-customers” fingerprints that are driven by data mining fleet-wide data as well as other new features to discover and start protecting against an issue before a single customer array is affected.
We hope this peek inside at one our more exciting and innovative technologies was interesting. We will keep you updated of future developments and success.



