

At Pure we’re often asked our perspective on how data center and application architectures will change over the next decade. We believe the future lies in Data-Centric Architecture. The concept is simple: Tomorrow’s architecture will be centered around a broadly-shared set of data services, which enable data to be freely shared by traditional and new web scale applications.
We believe it’s the most exciting time to be in the infrastructure space in our careers: web scale application architectures and the cloud are in the early innings of causing a nearly complete re-wiring of the data center. In this blog we’ll lay-out Pure’s vision for how you should evolve your data strategy to prepare for these changes, and how Pure’s products can help you get there.
Why Data-Centric Matters
It’s always about the data. Much has been written about digital business transformation, and how across every industry, every business is becoming a software-driven business. Much has also been written about big data, real-time data, log/machine data, and how 44+ ZBs of data will be created in 2020, now mostly by machines instead of people. Data is now expected to be always available – “cold” data will no longer exist. AI and machine learning technologies are just beginning to help us extract value and insight from this mountain of data, and businesses are rapidly re-tooling to view data as the “oil” of the new economy, and to build people, processes, and technology to make the most of data.
You may notice that we don’t run IT out of “Server Centers” or “Networking Centers” — they’re called Data Centers for a reason. Data is the valuable resource. It’s the part that must be protected, shared, accessed and mined as fast as possible for the business. But very few organizations take the time to step-back and truly establish an architecture for their most strategic asset – data!
Instead, so often the architecture is developed over time, project by project, and you end-up with something like this:
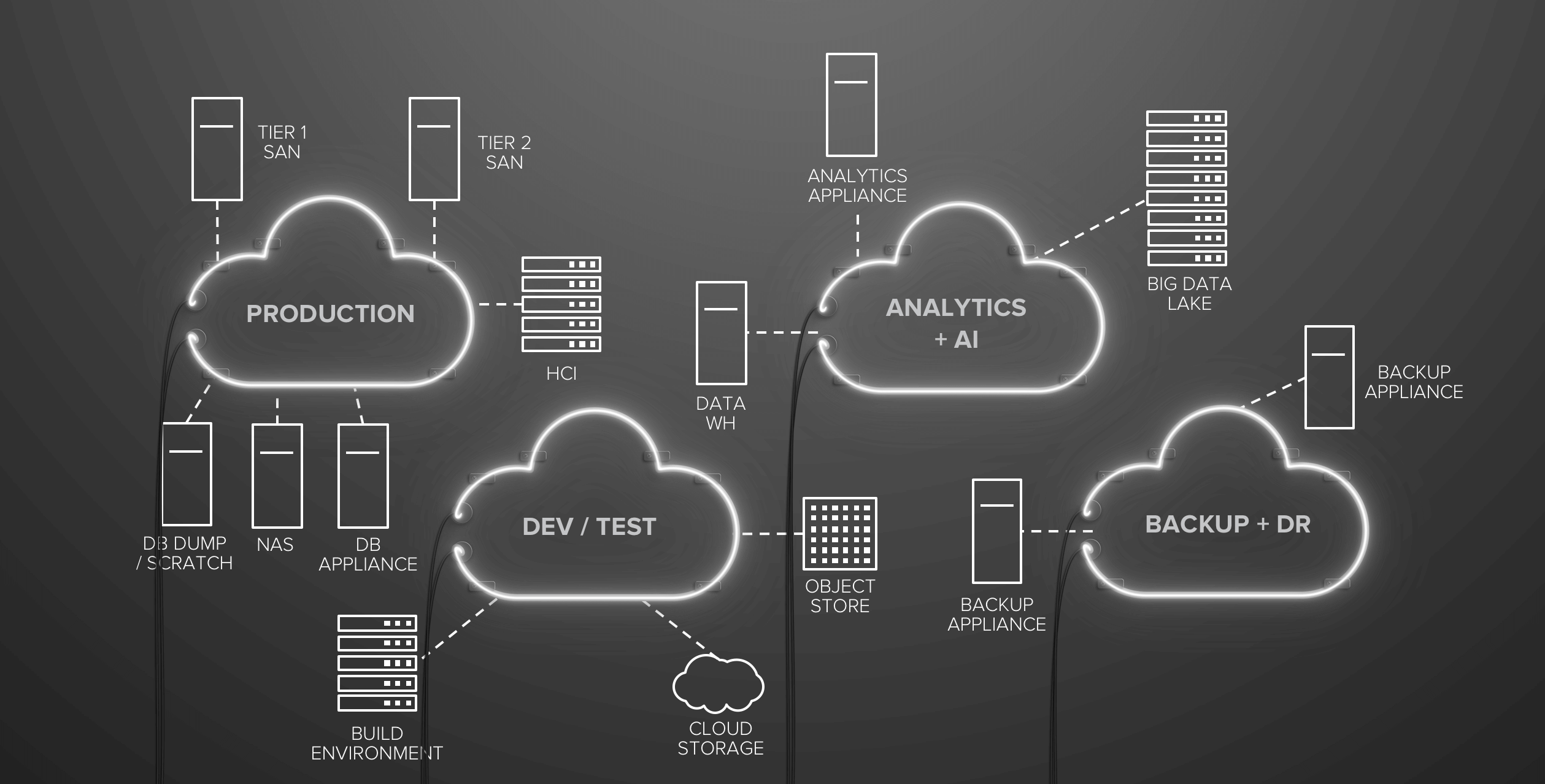
A myriad of application, development, and analytics islands, each supported by data silos of SANs, NAS, analytics appliances, scale-out applications, and more. If you truly step back and contemplate your infrastructure today – can you spot your data strategy?

Building in a time of Application Evolution
To complicate matters – everything is changing. Monolithic, scale-up “big iron” applications of the 90s were virtualized in the 2000s, but fundamentally the application architecture didn’t change much. Now applications are being built as scale-out, distributed applications, and this changes everything from the data perspective.

While the virtualization era saw the rise of big shared storage pools (often all-flash), the new application world expects something very different – applications are being written to expect simple shared access to data as a service – think about building a web application in AWS and storing data in S3. In this new application architecture – applications are thin and data is where all the persistence and state is – data matters even more.
We’ve gone from a world where big, thick compute stacks each had little dedicated storage islands, to a world where lots of little, stateless compute expects to have shared access to a vast pool of data delivered as a service. It’s a whole new (data) world.
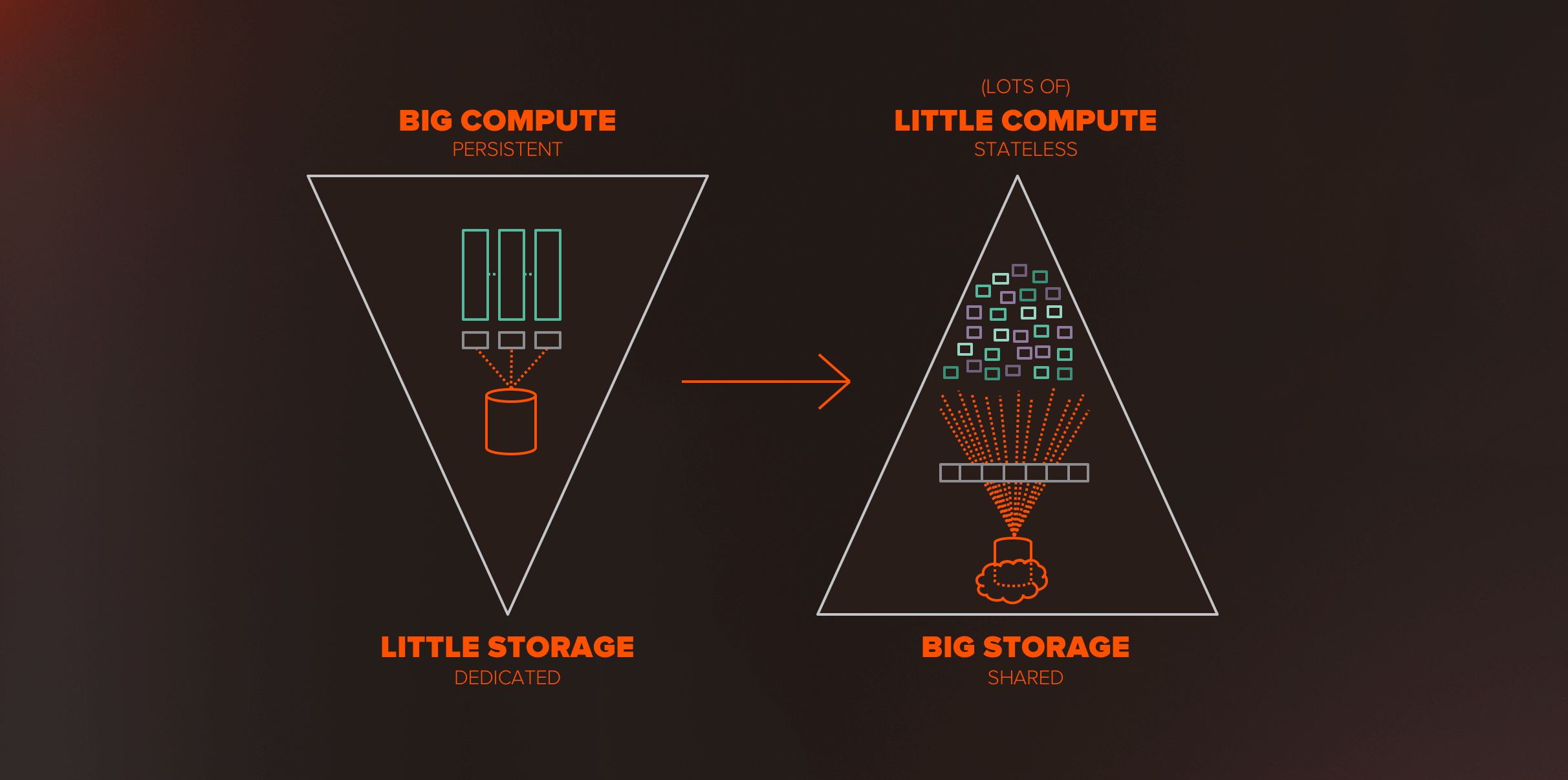
But the trouble is we still have all three of these application generations. Organizations must find ways to build a data strategy that continues to improve the classic applications that run your business, while enabling developers to build new web scale applications quickly.
Technology is Changing What’s Possible
Amidst all this application change, the fundamental architecture of computing is being pushed forward as well. New technologies are enabling us to potentially re-wire the infrastructure completely.

As Moore’s Law has slowed, compute is actually proliferating, with GPUs and FPGAs rising to solve specific computing tasks. Fast networks, powered by Ethernet, are exploding, with 25 Gb/s Ethernet being commodity today, 100 Gb/s becoming very affordable, and 400 Gb/s just around the corner. On top of these fast networks, new storage protocols like NVMe and NVMe-oF are enabling fast connectivity between storage and compute, and the world of solid state continues to diversify, with faster storage-class memories, as well as 3D TLC and QLC flash to drive flash down in to more and more use cases.
With massive east-west bandwidth, and low-latency storage protocols, data services and compute services can be easily-connected, on-demand, as required by applications. Silos can be broken-down and infrastructure can be standardized and truly shared. Data can be made broadly accessible, so modern scale-out applications can freely interact with it.
One of the reasons we’re so confident in this vision is that, it’s exactly how the public cloud is architected. While the major public cloud vendors started-out ~15 years ago with architecture that looked a little something like hyper-converged, they’ve moved far, far beyond that. Today that have a rich portfolio of shared data services, that are connected on-demand, via fast networks, to a diverse set of compute services:

This shared data architecture enables each application to get the storage it needs on-demand, applications to easily share data, and both the data and compute services to be architected for ultimate efficiency, and continuously improved and updated over time. All this is, of course, tied together with rich orchestration tools. It’s time to take these lessons into everyone’s architecture.
Today your infrastructure might look like this, a myriad of storage islands supporting your different application environments:

Tomorrow, it can be standardized to look like this, a truly-consolidated architecture that’s made possible by massive sharing of data:

A well-formed set of block, file, and object services, that are architected to be broadly shared. A diskless, stateless compute tier, that can run all your applications, in containers, VMs, and as bare metal as required. All tied together with fast converged networking and full-stack open orchestration. Data can be served from dedicated “end of row” racks, or a standard rack can be defined that you may print-out 10s or 100s of times to build your infrastructure – either way – the broadly-shared data services enable the ultimate consolidation, standardization, and agility in the infrastructure.
Pure’s Data-Centric Architecture
Data-Centric Architecture should be built to provide shared data services for the wide range of data customers in the organization: mission-critical production applications, new web scale applications, the development team implementing a modern CI/CD pipeline, and the data science teams driving analytics and AI initiatives.

Data-Centric Architecture should have the following tenants:
- Consolidated and shared: It’s built to share data at its core, removing the need to endlessly copy data between applications and enabling broader insights by giving the organization access to data.
- Built for real-time: The architecture must deliver the data speed to enable the organization to leverage data in the moment.
- Built to be on-demand and self-driving: Data should be requested and accessed by APIs and delivered via automation, not typing.
- Multi-cloud from the start: You want to be able to utilize the public cloud alongside your owned infrastructure, and the architecture should facilitate easily moving data and applications between the two.
- Built to stand the test of time: Given the pace of change of everything, the architecture must be built to be able to scale and evolve in-place.
Inherent in this move to establishing a Data-Centric Architecture is a new mindset for the storage team. The storage team needs to challenge itself to go from a storage operations team, to becoming a true storage service provider to the organization.
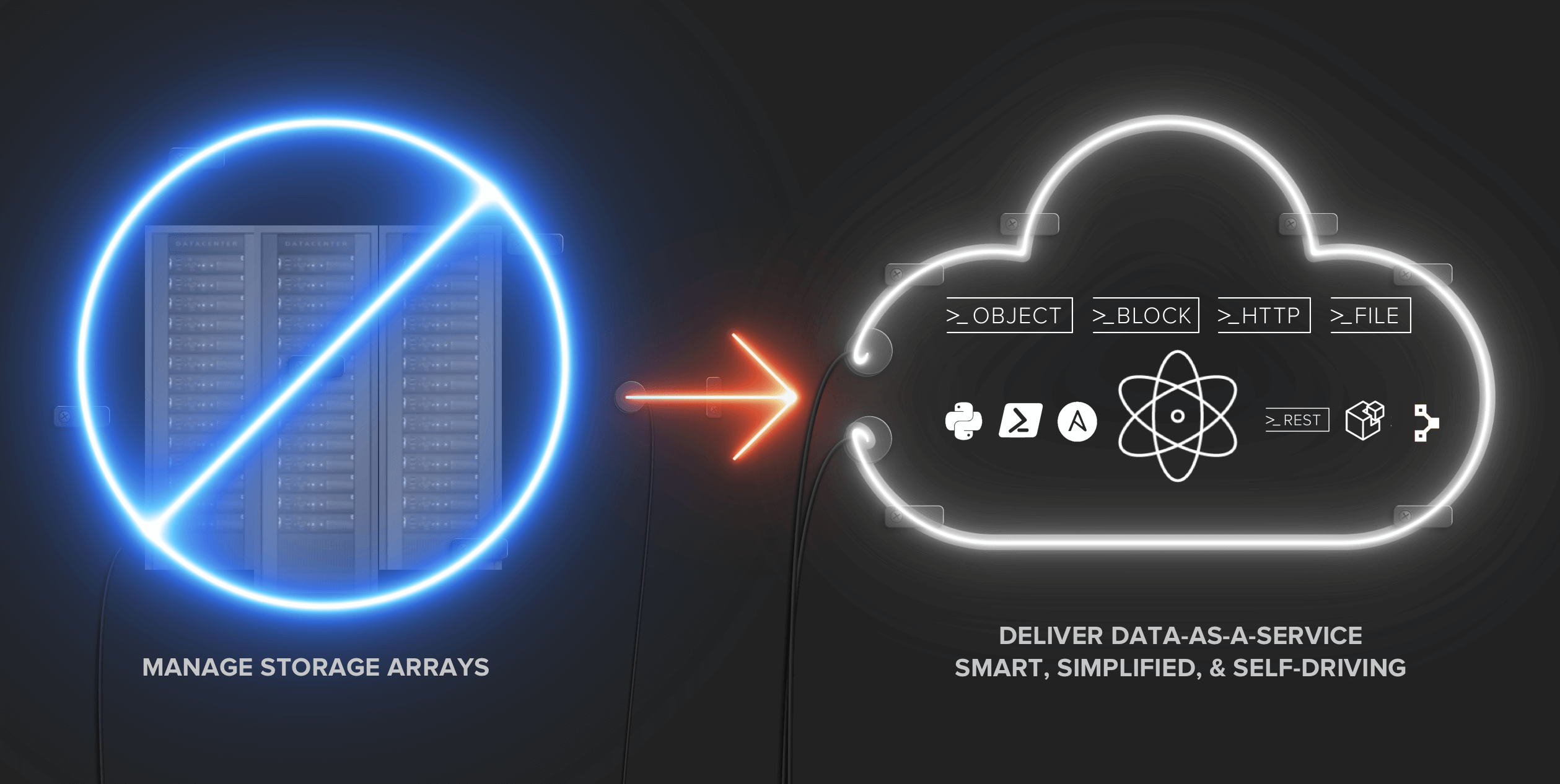
Instead of replying to ad-hoc requests and troubleshooting siloed infrastructure, time must be spent architecting and delivering a well-formed set of storage services, delivering the block, file, and object storage the organization requires, and making it fully-accessible by API. Think about it this way: you’ll know you’re on the right track when no one in the organization knows who the storage admin is – they just know their applications run on a reliable storage service that “just works”….just like the cloud! It’s a big change in thinking, but one that creates an exciting vision for how a storage team evolves – to becoming the data service provider for the organization!
How Pure’s can help you get there
At Pure, we’re doing the hard work to make this new Data-Centric Architecture accessible to all. You can’t buy a Data-Centric Architecture, you have to build one, as it requires both technology, process, and organizational change. It’s an evolution – not an overnight transformation. But our job is to facilitate it with our technology stack, and that’s exactly what we’re doing with the Pure Data-Centric Architecture.
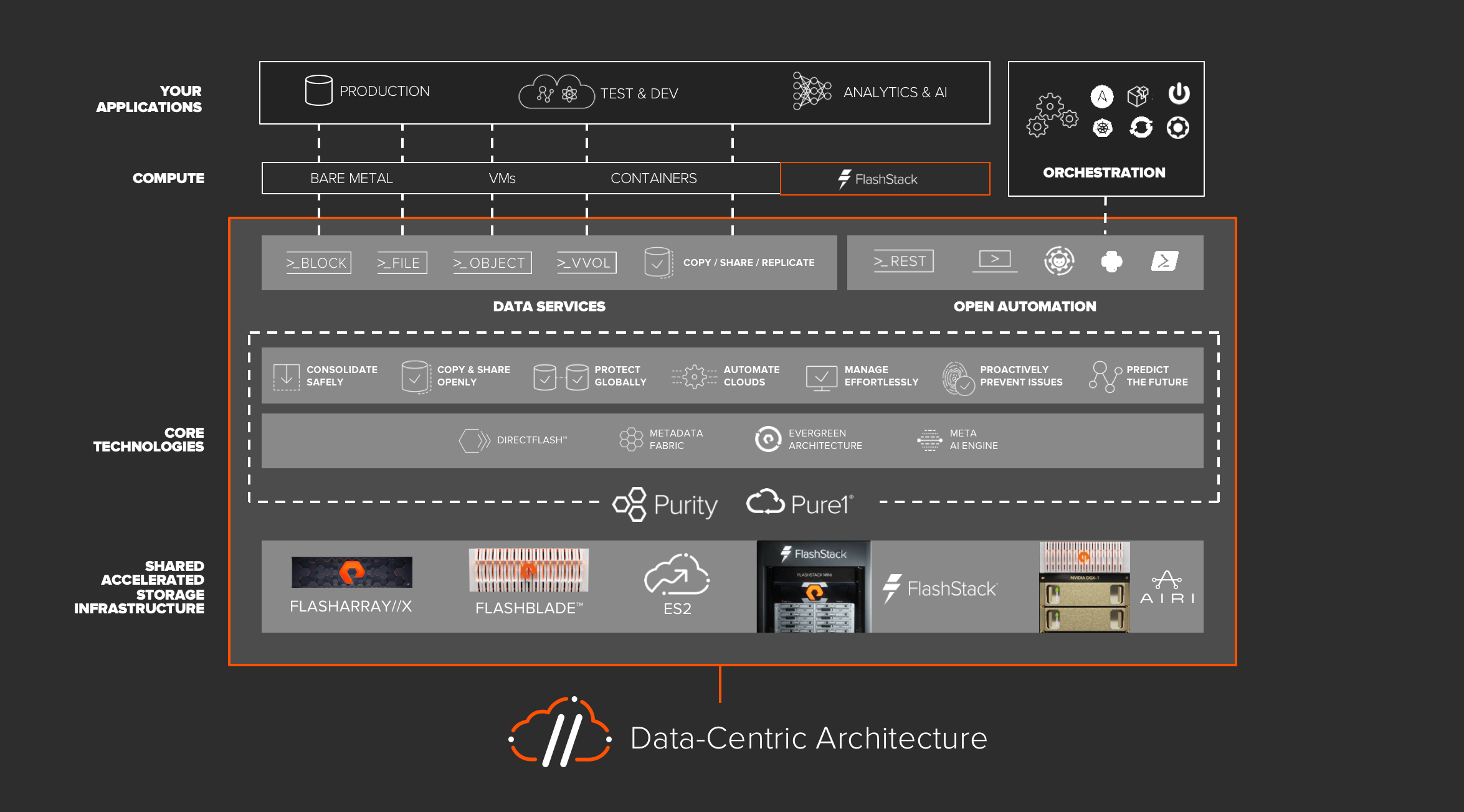
Pure’s DCA is built on the solid foundation of our Shared Accelerated Storage arrays, FlashArray//X and FlashBlade™, and our converged solutions FlashStack™ and AIRI™. These solutions come together to deliver the scalable block, file, and object storage services that your production, test/dev, and analytics teams require. This architecture is API-first and has a rich set of REST APIs and pre-build automation connectors, making it easy to automate storage delivery at scale. And, of course, the heart of the architecture is software, our Purity storage software and Pure1® support & management platform, which make rich storage services directly-accessible to applications.
Ultimately, the opportunity here is to truly enable IT to deliver value to the business through a data-centric architecture. With one strategy IT can dramatically cost-reduce, standardize, and simplify everything production, can meaningfully accelerate development so engineering can get code to the business and to market faster, and can partner with the data science team to deliver the infrastructure required for the business to consume data insights in real time.
At Pure, we look forward to partnering with you on this journey. Today, at our //Accelerate conference, you’ll see a host of new product and service announcements that help us deliver this Data-Centric Architecture. Dive in, learn, and most importantly make today the day that you decide to embark upon building the data-centric architecture that your business needs! We’re here to help, it’s going to be an awesome journey.
For more on our exciting announcements at Pure//Accelerate, read the blogs below:
- Introducing the New FlashArray//X Family: Shared Accelerated Storage for Every Workload
- Non-Disruptive Upgrades: FlashArray//M to //X with NVMe
- A New Era of Storage with NVMe & NVMe-oF
- FlashArray//X Sets New Bar for Oracle Performance
- New FlashArray//X Drives Application Acceleration for SAP HANA
- FlashArray//X Drives Application Performance for Epic
- Make Your Resume Even More Compelling with FlashStack™
- True Opex Storage for private, hybrid, and multi-cloud
- Pure’s Evergreen Delivers Right-Size Guarantee, again, and again and again
- How to Cross the AI Chasm: From Vision to an AI-First Business
- Pure1 Expands AI Capabilities and Adds Full-Stack Analytics
- All-Flash Platform-as-a-Service: Pure Storage and Red Hat OpenShift Reference Architecture
- Delivering Container Storage-as-a-Service
- How to Empower Developers and Accelerate Time to Market



