Resumen
Storage is the backbone of AI, but as model complexity and data intensity increase, traditional storage systems can’t keep pace. Agile, high-performance storage platforms are critical to support AI’s unique and evolving demands.


En la carrera por la inteligencia general artificial (AGI), la tecnología de almacenamiento está marcando el ritmo. Si bien los algoritmos y la computación son el centro de atención, el almacenamiento impulsa los avances de la IA. Durante la revolución del flash, los discos de 15K00 se estancaron a medida que el rendimiento computacional se duplicaba cada dos años, pero la virtualización habilitada por el flash y, actualmente, las cargas de trabajo impulsadas por GPU impulsan una mayor innovación en el almacenamiento, además de las demandas de eficiencia, sostenibilidad y fiabilidad.
Los primeros esfuerzos de la IA estaban limitados por la complejidad algorítmica y la escasez de datos, pero a medida que los algoritmos avanzaban, surgían cuellos de botella en la memoria y el almacenamiento. El almacenamiento de alto rendimiento ha desbloqueado avances como ImageNet, que alimentaba los modelos de visión, y GPT-3, que requería petabytes de almacenamiento. Con 400 millones de terabytes de datos generados diariamente, el almacenamiento debe gestionar cargas de trabajo a escala de exabytes con una latencia de submilisegundos para impulsar la AGI y el aprendizaje automático cuántico. A medida que la IA avanzaba, cada oleada de innovación planteaba nuevas demandas de almacenamiento, impulsando avances en la capacidad, la velocidad y la escalabilidad para adaptarse a modelos cada vez más complejos y conjuntos de datos más grandes.
- Aprendizaje automático clásico (1980s-2015): El reconocimiento de voz y los modelos de aprendizaje supervisado impulsaron el crecimiento del conjunto de datos de megabytes a gigabytes, lo que hizo que la recuperación y la organización de los datos fueran cada vez más críticas.
- Revolución del aprendizaje profundo (2012-2017): Modelos como AlexNet y ResNet han impulsado las demandas de almacenamiento, mientras que Word2Vec y GloVe han avanzado en el procesamiento del lenguaje natural y han pasado al almacenamiento NVMe de alta velocidad para los conjuntos de datos a escala de terabytes.
- Modelos básicos (2018-actual): BERT introdujo conjuntos de datos a escala de petabytes, con GPT-3 y Llama 3 que requerían sistemas escalables y de baja latencia, como Tectonic de Meta, para manejar billones de tokens y mantener un rendimiento de 7TB/s.
- Leyes de escalamiento de Chinchilla (2022): Chinchilla ha hecho hincapié en el crecimiento de los conjuntos de datos sobre el tamaño del modelo LLM, que requiere un almacenamiento de acceso paralelo para optimizar el rendimiento.
El almacenamiento no solo es compatible con la IA, sino que está liderando el camino, dando forma al futuro de la innovación gestionando los datos en constante crecimiento del mundo de manera eficiente y a escala. Por ejemplo, las aplicaciones de IA en la conducción autónoma se basan en plataformas de almacenamiento capaces de procesar petabytes de datos de sensores en tiempo real, mientras que la investigación genómica requiere un acceso rápido a conjuntos de datos masivos para acelerar los descubrimientos. A medida que la IA sigue ampliando los límites de la gestión de los datos, los sistemas de almacenamiento tradicionales se enfrentan a retos cada vez mayores para seguir el ritmo de estas demandas cambiantes, lo que pone de relieve la necesidad de soluciones específicas.
Cómo las cargas de trabajo de la IA frenan los sistemas de almacenamiento tradicionales
Consolidación de datos y gestión del volumen
Las aplicaciones de IA gestionan conjuntos de datos que van de terabytes a cientos de petabytes, superando con creces las capacidades de los sistemas de almacenamiento tradicionales como NAS, SAN y el almacenamiento tradicional de conexión directa. Estos sistemas, diseñados para cargas de trabajo transaccionales precisas, como la generación de informes o la recuperación de registros específicos, tienen problemas con las exigencias de agregación de la ciencia de datos y los patrones de acceso amplios y de alta velocidad de las cargas de trabajo de IA/ML. El entrenamiento de modelos, que requiere una recuperación de datos masiva y por lotes en todos los conjuntos de datos, pone de relieve esta desalineación. Las arquitecturas rígidas, las limitaciones de capacidad y el rendimiento insuficiente de la infraestructura tradicional hacen que no sea adecuada para la escala y la velocidad de la IA, lo que pone de relieve la necesidad de plataformas de almacenamiento creadas expresamente.
Cuellos de botella en el rendimiento para un acceso a los datos de alta velocidad
Las analíticas y la toma de decisiones en tiempo real son esenciales para las cargas de trabajo de la IA, pero las arquitecturas de almacenamiento tradicionales suelen crear cuellos de botella con IOPS insuficientes, ya que se han creado para tareas transaccionales moderadas en lugar de las demandas intensivas y paralelas de lectura/escritura de la IA. Además, la alta latencia de los discos giratorios o los mecanismos de caché obsoletos retrasan el acceso a los datos, lo que aumenta el tiempo de obtención de información y reduce la eficiencia de los procesos de IA.
Gestión de diversos tipos de datos y cargas de trabajo
Los sistemas de IA manejan datos estructurados y no estructurados —incluidos texto, imágenes, audio y vídeo—, pero las soluciones de almacenamiento tradicionales luchan contra esta diversidad. A menudo se optimizan para los datos estructurados, lo que provoca una recuperación lenta y un procesamiento ineficiente de los formatos no estructurados. Además, la mala indexación y la gestión de metadatos dificultan la organización y la búsqueda efectiva de diversos conjuntos de datos. Los sistemas tradicionales también se enfrentan a problemas de rendimiento con archivos pequeños, habituales en los modelos de lenguaje de entrenamiento, ya que la sobrecarga de metadatos alta provoca retrasos y tiempos de procesamiento más largos.
Limitaciones de la arquitectura tradicional
El efecto acumulado de estos retos es que las arquitecturas de almacenamiento tradicionales no pueden seguir el ritmo de las demandas de las cargas de trabajo de IA modernas. Carecen de la agilidad, el rendimiento y la escalabilidad necesarios para soportar los diversos requisitos de datos de gran volumen de la IA. Estas limitaciones ponen de relieve la necesidad de disponer de soluciones de almacenamiento avanzadas diseñadas para hacer frente a los retos únicos de las aplicaciones de IA, como la escalabilidad rápida, el alto caudal, la baja latencia y la gestión de datos diversos.
Retos clave del almacenamiento en la IA
Las cargas de trabajo de IA imponen demandas únicas a los sistemas de almacenamiento y para abordar estos retos se necesitan capacidades avanzadas en las siguientes áreas:
- Consolidación unificada de datos: Los silos de datos fragmentan información valiosa, lo que exige la consolidación en una plataforma unificada que admita diversas cargas de trabajo de IA para un procesamiento y entrenamiento perfectos.
- Rendimiento y capacidad escalables: Una plataforma de almacenamiento robusta debe gestionar diversos perfiles I/O y escalar de terabytes a exabytes, lo que garantiza un acceso de baja latencia y alto rendimiento. Al permitir el escalamiento no disruptivo, la plataforma permite que las cargas de trabajo de IA se expandan sin problemas a medida que crecen las demandas de datos, manteniendo un funcionamiento fluido e ininterrumpido.
- Flexibilidad de escalamiento horizontal y horizontal: El manejo del acceso transaccional de baja latencia para las bases de datos vectoriales y las cargas de trabajo de alta concurrencia para el entrenamiento y la inferencia requiere una plataforma que proporcione ambas capacidades.
- Fiabilidad y disponibilidad continua: A medida que la IA se vuelve crítica para las empresas, el 99,9999% del tiempo de actividad es esencial. Una plataforma de almacenamiento debe admitir actualizaciones y actualizaciones de hardware no disruptivas, lo que garantiza un funcionamiento continuo sin tiempos de inactividad visibles para los usuarios finales.
Optimización del almacenamiento en todo el pipeline de IA
Las soluciones de almacenamiento eficaces son esenciales en cada etapa del pipeline de IA, desde la selección de datos hasta el entrenamiento y la inferencia, ya que permiten que las cargas de trabajo de IA funcionen de manera eficiente y a escala. Los pipelines de IA requieren un almacenamiento que pueda manejar sin problemas las tareas sensibles a la latencia, escalarse para satisfacer las demandas de alta concurrencia, soportar diversos tipos de datos y mantener el rendimiento en entornos distribuidos.
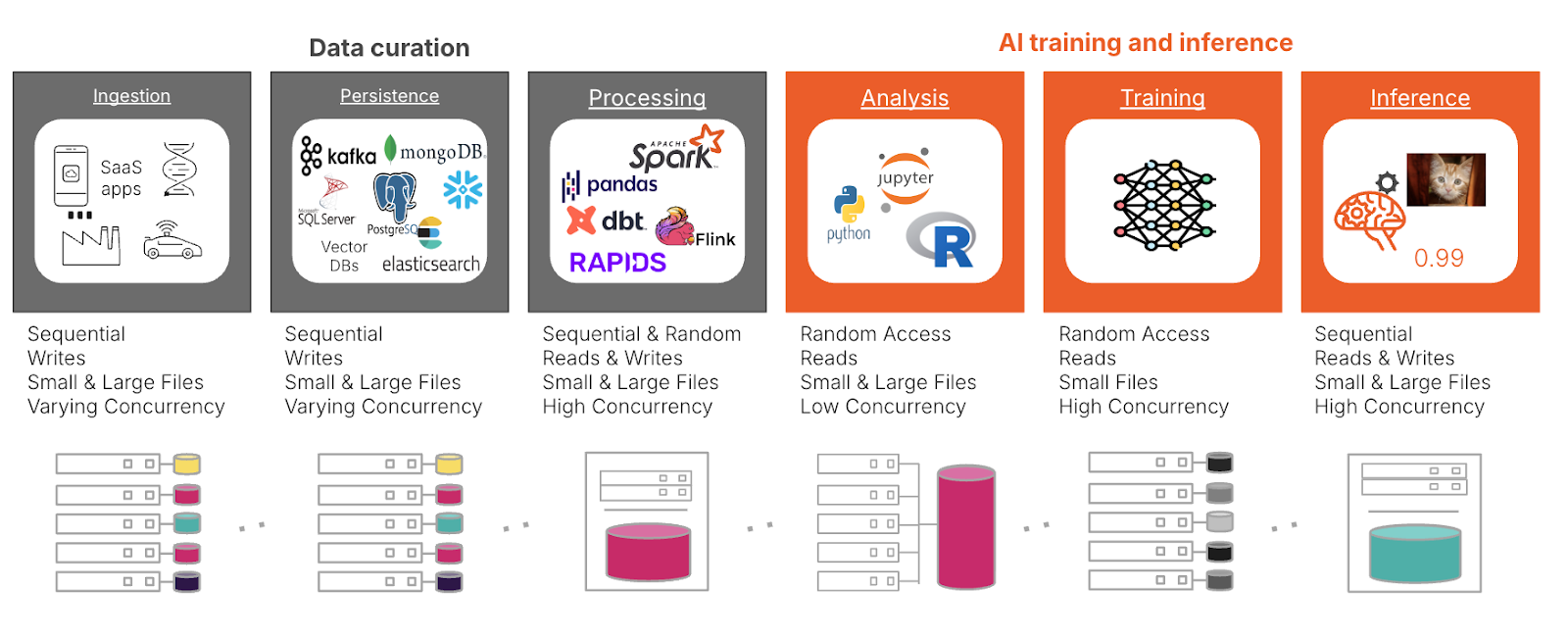
Figura 1: Los patrones de almacenamiento para la IA son variados y requieren una plataforma creada para el rendimiento multidimensional.
En la fase de selección de datos, la gestión de los conjuntos de datos a escala de petabyte a exabyte empieza con la ingestión, en la que el almacenamiento debe escalarse sin problemas para manejar volúmenes de datos masivos y garantizar un alto rendimiento. Las aplicaciones en tiempo real, como la conducción autónoma, requieren un almacenamiento de baja latencia capaz de procesar los datos entrantes al instante. Los Módulos DirectFlash® (DFM) sobresalen en estos escenarios al evitar las arquitecturas SSD tradicionales para acceder directamente al flash NAND, lo que proporciona un rendimiento más rápido y constante con una latencia significativamente reducida. En comparación con las SSD y SCM tradicionales, los DFM también ofrecen una mayor eficiencia energética, lo que permite que las organizaciones satisfagan las demandas de las cargas de trabajo de IA a gran escala, optimizando al mismo tiempo el consumo energético y manteniendo un rendimiento predecible bajo una gran concurrencia.
Durante la persistencia, las soluciones de almacenamiento de datos deben soportar la conservación a largo plazo y la accesibilidad rápida para los datos a los que se accede con frecuencia. El paso del procesamiento es clave para preparar los datos para la formación, en el que el almacenamiento debe gestionar una serie de tipos y tamaños de datos de manera eficiente, manejando los datos estructurados y no estructurados en formatos como NFS, SMB y objetos.
En la fase de entrenamiento e inferencia de la IA, el entrenamiento de modelos genera demandas intensivas de lectura/escritura, lo que requiere arquitecturas escalables horizontalmente para garantizar el rendimiento en múltiples nodos. Los sistemas eficientes de control de puntos de control y control de versiones son críticos en esta fase para evitar la pérdida de datos. Además del control, las arquitecturas emergentes, como la generación aumentada de recuperación (RAG), plantean retos únicos para los sistemas de almacenamiento. RAG se basa en la recuperación eficiente de las bases de conocimientos externas durante la inferencia, lo que exige un almacenamiento de baja latencia y alto rendimiento capaz de gestionar consultas simultáneas y paralelas. Esto ejerce una presión adicional sobre la gestión de metadatos y la indexación escalable, lo que exige que las arquitecturas de almacenamiento avanzadas optimicen el rendimiento sin cuellos de botella.
Al alinear las soluciones de almacenamiento con las necesidades específicas de cada etapa de la canalización, las organizaciones pueden optimizar el rendimiento de la IA y mantener la flexibilidad necesaria para soportar las demandas cambiantes de la IA.
Visítenos en NVIDIA GTC del 17 al 25 de marzo en el Centro de Convenciones de San José
Permitir el entrenamiento y la inferencia de IA a escala de exabytes
Conclusión
El almacenamiento es la columna vertebral de la IA, ya que la creciente complejidad del modelo y la intensidad de los datos impulsan las demandas exponenciales de la infraestructura. Las arquitecturas de almacenamiento tradicionales no pueden satisfacer estas necesidades, lo que hace que la adopción de soluciones de almacenamiento ágiles y de alto rendimiento sea esencial.
La relación simbiótica entre la IA y las plataformas de almacenamiento significa que los avances en el almacenamiento no solo admiten, sino que también aceleran el progreso de la IA. Para las empresas que acaban de empezar a explorar la IA, la flexibilidad es crucial: Necesitan un almacenamiento que pueda escalarse a medida que crecen sus necesidades de datos y computación, que admita múltiples formatos (por ejemplo, archivos, objetos) y que se integre fácilmente con las herramientas existentes.
Las organizaciones que invierten en plataformas de almacenamiento modernas se sitúan a la vanguardia de la innovación. Esto requiere:
- Evaluación de la infraestructura: Identificar las limitaciones actuales y las áreas de mejora inmediata.
- Adoptar soluciones escalables: Implemente plataformas que ofrezcan flexibilidad, alto rendimiento y crecimiento fluido.
- Planificación de las necesidades futuras: Manténgase por delante de las tendencias emergentes para garantizar que la plataforma evolucione con los desarrollos de la IA.
Al priorizar las plataformas de almacenamiento como un componente fundamental de la estrategia de IA, las organizaciones pueden desbloquear nuevas oportunidades, impulsar la innovación continua y mantener una ventaja competitiva en el futuro basado en los datos.
¿Quiere saber más?
Visite la página de soluciones de IA
Vea la repetición del seminario web: «Consideraciones para una infraestructura de IA empresarial estratégica acelerada»
Descargue el informe: «La plataforma de Pure Storage para la IA»

ANALYST REPORT,
Top Storage Recommendations
to Support Generative AI

A Game-changer for AI
Accelerate your AI initiatives with the Pure Storage platform.