

Resumen
FlashBlade//EXA is the newest member of the FlashBlade family. Optimized for AI workloads, this ultra-scale data storage platform provides massive storage throughput and operates at extreme levels of performance and scale.


¡Corredores, arranquen sus motores! Pure Storage se complace en anunciar FlashBlade//EXA™, una plataforma de almacenamiento de datos a gran escala optimizada para las cargas de trabajo de la IA, que proporciona un caudal de almacenamiento enorme y funciona a unos niveles extremos de rendimiento y escalabilidad.
¿Qué tienen en común los fabricantes de automóviles de alto rendimiento y Pure Storage? Al igual que los fabricantes de automóviles de primer nivel diseñan modelos de coches de carreras de vanguardia que superan los límites de velocidad y eficiencia, FlashBlade//EXA se ha creado para proporcionar un rendimiento de nivel superior para las cargas de trabajo de IA y HPC. FlashBlade//EXA es similar a esos ejemplos, ya que es un sistema FlashBlade® con Purity//FB altamente optimizado para proporcionar un rendimiento de siguiente nivel para las cargas de trabajo de IA más exigentes. Complementa los modelos de alto rendimiento FlashBlade//S™ y FlashBlade//E™ de alta densidad que han sido probados en el mercado empresarial y reconocidos en el Cuadrante Mágico™ de Gartner® para Plataformas de Almacenamiento de Archivos y Objetos como líderes durante cuatro años seguidos.
El reto empresarial de los avances rápidos en la IA
A medida que la innovación en IA se amplía, muchas empresas descubren rápidamente el valor de aumentar o revolucionar sus operaciones existentes con entrenamiento e inferencia de modelos. Este crecimiento acelerado ha aumentado la adopción de los flujos de trabajo de IA en el preprocesamiento, el entrenamiento, las pruebas, el ajuste fino y la implementación —cada uno de ellos se beneficia de unas GPU más potentes y de unos conjuntos de datos multimodales más grandes—.
Esta expansión también ha introducido nuevos retos en la infraestructura. La escalabilidad del almacenamiento tradicional, el checkpointing, la gestión y las limitaciones de rendimiento de los metadatos a escala están creando cuellos de botella y obstaculizando el uso completo de las costosas infraestructuras orientadas a la GPU y ralentizando el progreso y la innovación. Esto afecta en gran medida a las presiones financieras agresivas del ROI de la IA —cualquier infraestructura dedicada a ella tiene que funcionar con el máximo rendimiento para garantizar el tiempo de obtención de valor más rápido posible para el entrenamiento y la inferencia de modelos. La pérdida de tiempo es la pérdida de dinero.
Los retos empresariales se amplifican con flujos de trabajo de IA a gran escala
Este reto empresarial de las GPU inactivas, que equivale a la pérdida de tiempo y dinero, se amplifica exponencialmente a escala, por ejemplo, los proveedores de nube de GPU y los laboratorios de IA, por dos razones. En primer lugar, la eficiencia operativa masiva a escala es fundamental para su rentabilidad y va mucho más allá de lo que la mayoría de las operaciones locales/internas de los centros de datos gestionan. Un blog que publicamos el año pasado nos ofreció información sobre cómo piensan los proveedores de servicios y cómo la automatización y la estandarización brutal son críticas para sus operaciones. En segundo lugar, los proveedores de servicios se suscriben al principio fundamental de evitar cualquier recurso que funcione inactivo. Para ellos, las GPU inactivas en cualquier modelo de IA son una oportunidad de pérdida de ingresos: las ineficiencias de almacenamiento en su nivel de funcionamiento pueden ser perjudiciales.
Las arquitecturas de almacenamiento tradicionales de alto rendimiento se han desarrollado sobre sistemas de archivos paralelos y se han diseñado y optimizado para entornos informáticos de alto rendimiento (HPC) tradicionales y dedicados. Las cargas de trabajo de HPC son previsibles, por lo que los sistemas de almacenamiento paralelos pueden optimizarse para un escalamiento específico del rendimiento. Los flujos de trabajo y los modelos a gran escala basados en la IA son diferentes de los de la HPC tradicional, porque son más complejos e implican muchos más parámetros que también son multimodales, ya que incluyen archivos de texto, imágenes, vídeos y otros —todo ello tiene que ser procesado simultáneamente por decenas de miles de GPU—. Estas nuevas dinámicas están demostrando rápidamente el modo en que los enfoques tradicionales del almacenamiento basados en la HPC tienen dificultades para funcionar a gran escala. Más concretamente, el rendimiento de los sistemas de almacenamiento paralelo tradicionales se vuelve polémico al dar servicio a los metadatos y los datos asociados desde el mismo plano del controlador de almacenamiento.
Este cuello de botella emergente exige una nueva manera de pensar en la gestión de los metadatos y las optimizaciones del acceso a los datos para gestionar de manera eficiente diversos tipos de datos y una gran concurrencia de las cargas de trabajo de IA a escala de proveedor de servicios.
Requisitos extremos de escalamiento del almacenamiento con la evolución de la carga de trabajo de la IA
A medida que los volúmenes de datos aumentan, la gestión de metadatos se convierte en un cuello de botella crítico. El almacenamiento tradicional tiene dificultades para escalar los metadatos de manera eficiente, lo que provoca latencia y degradación del rendimiento, especialmente para las cargas de trabajo de IA y HPC que exigen un paralelismo extremo. Las arquitecturas tradicionales, creadas para el acceso secuencial, no pueden seguir el ritmo. A menudo sufren rigidez y complejidad, lo que limita la escalabilidad. Para superar estos retos se necesita una arquitectura que priorice los metadatos y que se escale sin problemas, admita el paralelismo masivo y elimine los cuellos de botella. A medida que la oportunidad de IA y HPC evoluciona, los retos solo se agravan.

El núcleo de metadatos probado disponible en FlashBlade//S ha ayudado a los clientes empresariales a abordar los exigentes requisitos de formación, ajuste e inferencia de la IA al superar los retos de los metadatos, como:
- Gestión de la simultaneidad: Manejar volúmenes enormes de solicitudes de metadatos en múltiples nodos de manera eficiente
- Prevención de puntos calientes: Evitar los cuellos de botella de los servidores de metadatos únicos que pueden degradar el rendimiento y que requieren ajustes y optimizaciones constantes.
- Coherencia a escala: Garantizar la sincronización entre copias de metadatos distribuidas
- Gestión eficiente de la jerarquía: Optimización del funcionamiento complejo del sistema de archivos manteniendo el rendimiento
- Escalabilidad y resiliencia: Mantener un alto rendimiento a medida que los volúmenes de datos crecen exponencialmente
- Eficiencia operativa: Garantizar que la gestión y los gastos generales se minimizan y automatizan para respaldar la eficiencia a escala.
FlashBlade//EXA aborda los retos de rendimiento de la IA a escala
Pure Storage tiene un historial demostrado de asistencia a los clientes en una amplia gama de casos de uso de alto rendimiento y en cada etapa de su proceso de IA. Desde que presentamos AIRI® (infraestructura preparada para la IA) en 2018, hemos seguido liderando con innovaciones como las certificaciones para NVIDIA DGX SuperPOD™ y NVIDIA DGX BasePOD™, así como soluciones llave en mano como GenAI Pods. FlashBlade se ha ganado la confianza en el mercado empresarial de la IA y la HPC, ayudando a organizaciones como Meta a escalar sus cargas de trabajo de IA de manera eficiente. Nuestro núcleo de metadatos se basa en una base de datos transaccional masivamente distribuida y la tecnología de almacenamiento de valor clave ha garantizado una alta disponibilidad de metadatos y un escalamiento eficiente. Al aplicar información de los hiperescaladores y aprovechar nuestro núcleo de metadatos avanzado probado con FlashBlade//S, Pure Storage tiene la capacidad única de proporcionar un almacenamiento de rendimiento extremo que supera los retos de los metadatos de la IA y la HPC a gran escala.
Introduzca FlashBlade//EXA.
A medida que los flujos de trabajo extremos de la IA de extremo a extremo amplían los límites de la infraestructura, la necesidad de una plataforma de almacenamiento de datos que coincida con esta escala nunca ha sido mayor. FlashBlade//EXA amplía la familia FlashBlade, lo que garantiza que los entornos de IA y HPC a gran escala ya no estén limitados por las limitaciones del almacenamiento tradicional.
FlashBlade//EXA está diseñado para las fábricas de IA y proporciona una arquitectura de procesamiento masivamente paralela que desagrega los datos y los metadatos, eliminando los cuellos de botella y las complejidades asociadas con los sistemas de archivos paralelos tradicionales. Basado en las fortalezas demostradas de FlashBlade y con la tecnología de la arquitectura avanzada de metadatos de Purity//FB, proporciona un rendimiento, una escalabilidad y una simplicidad sin igual a cualquier escala.
Tanto si admite nativos de IA, titanos tecnológicos, empresas impulsadas por IA, proveedores de nube impulsados por GPU, laboratorios de HPC o centros de investigación, FlashBlade//EXA satisface las demandas de los entornos con un uso más intensivo de datos. Su diseño de última generación permite una producción, una inferencia y un entrenamiento perfectos, ofreciendo una plataforma de almacenamiento de datos completa incluso para las cargas de trabajo de IA más exigentes.
Nuestro enfoque innovador de cómo modificamos Purity//FB, que consistía en dividir las I/O basadas en la red de alto rendimiento de velocidad en dos elementos discretos:
- La cabina FlashBlade almacena y gestiona los metadatos con su base de datos de clave/valor distribuida escalable horizontalmente líder en el sector.
- Un clúster de nodos de datos de terceros es donde los bloques de datos se almacenan y se accede a muy alta velocidad desde el GPU clúster de GPU a través del Acceso Directo a Memoria Remoto (RDMA) usando protocolos de red estándar del sector.
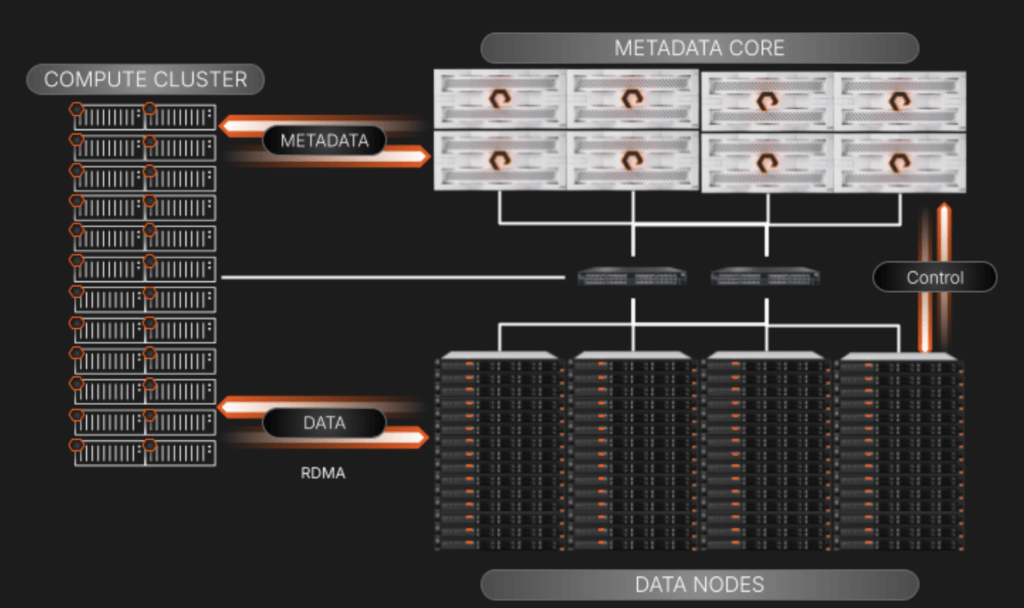
Esta segregación proporciona un acceso a los datos sin bloqueo que aumenta exponencialmente en escenarios informáticos de alto rendimiento en los que las solicitudes de metadatos pueden igualar, si no superar, las operaciones I/O de datos.
¿Por qué los servidores y las SSD listos para usar para los nodos de datos?
Los entornos de IA a gran escala pueden tener una inversión establecida de servidores de 1U y 2U con SSD como componentes básicos de la infraestructura. FlashBlade//EXA utiliza servidores listos para usar para el plano de datos, lo que facilita el ajuste en la arquitectura del cliente objetivo (en este caso, entornos a gran escala). Esto pone de relieve un punto importante de nuestra plataforma de almacenamiento de datos:
*Purity de Pure, como centro de nuestra plataforma, reside en su capacidad para ser modificada para abordar nuevos casos de uso, incluso si significa estirarse para operar fuera de nuestro propio hardware. Resolver los retos con nuestro software es un principio fundamental para nosotros, porque es un enfoque más elegante y proporciona un tiempo de obtención de valor más rápido a los clientes.
Estos nodos de datos listos para usar proporcionan a los clientes la flexibilidad de adaptarse con el tiempo y pueden estar impulsados por la evolución de los clientes en cuanto a cómo utilizan el flash NAND en sus centros de datos.
Una vista de alto nivel de los componentes y I/O de FlashBlade//EXA
Al separar los planos de metadatos y de servicio de datos, nos hemos centrado en mantener los elementos del diagrama anterior fáciles de escalar y gestionar:
- Núcleo Metadata: Esto atiende todas las consultas de metadatos del clúster de computación. Cuando se repara una consulta, el nodo de computación solicitante se dirige al nodo de datos específico para realizar su trabajo. La cabina también supervisa la relación de los nodos de datos con los metadatos a través de una conexión de plano de control que está entre bastidores en su propio segmento de red.
- Nodos de datos de terceros: Se trata de servidores estándar listos para usar, para garantizar una amplia compatibilidad y flexibilidad. Los bloques de datos residen en las unidades NVMe de estos servidores. Ejecutarán un OS y un núcleo “delgados” basados en Linux, con administración de volúmenes y servicios de destino RDMA que están personalizados para trabajar con metadatos que residen en la cabina FlashBlade//EXA. Incluiremos un manual de estrategias de Ansible para gestionar el despliegue y las actualizaciones de los nodos, con el fin de eliminar cualquier preocupación sobre la complejidad a escala.
- Acceso paralelo a los datos usando el entorno de red existente: FlashBlade//EXA utiliza un enfoque elegante que utiliza una red de núcleo único y alta disponibilidad que utiliza BGP para enrutar y gestionar el tráfico entre los clientes de metadatos, datos y cargas de trabajo. Este diseño permite una integración perfecta en las redes de clientes existentes, lo que simplifica el despliegue de entornos de almacenamiento muy paralelos. Es importante destacar que todos los protocolos de red utilizados son estándar del sector; la pila de comunicación no contiene elementos propios.
Cómo desatar los retos del almacenamiento de alto rendimiento tradicional con sistemas de archivos paralelos y modelos desagregados
Muchos proveedores de almacenamiento que se centran en la naturaleza de alto rendimiento de las grandes cargas de trabajo de IA solo resuelven la mitad del problema del paralelismo, ofreciendo el ancho de banda de red más amplio posible para que los clientes alcancen los objetivos de datos. No abordan el modo en que los metadatos y los datos se atienden a un caudal enorme, que es donde surgen los cuellos de botella a gran escala. Esto tiene sentido, ya que la intención del diseño de NFS cuando Sun Microsystems lo creó en 1984 era simplemente salvar la brecha entre el acceso local y remoto a los archivos, donde el enfoque del diseño era la funcionalidad y la velocidad.
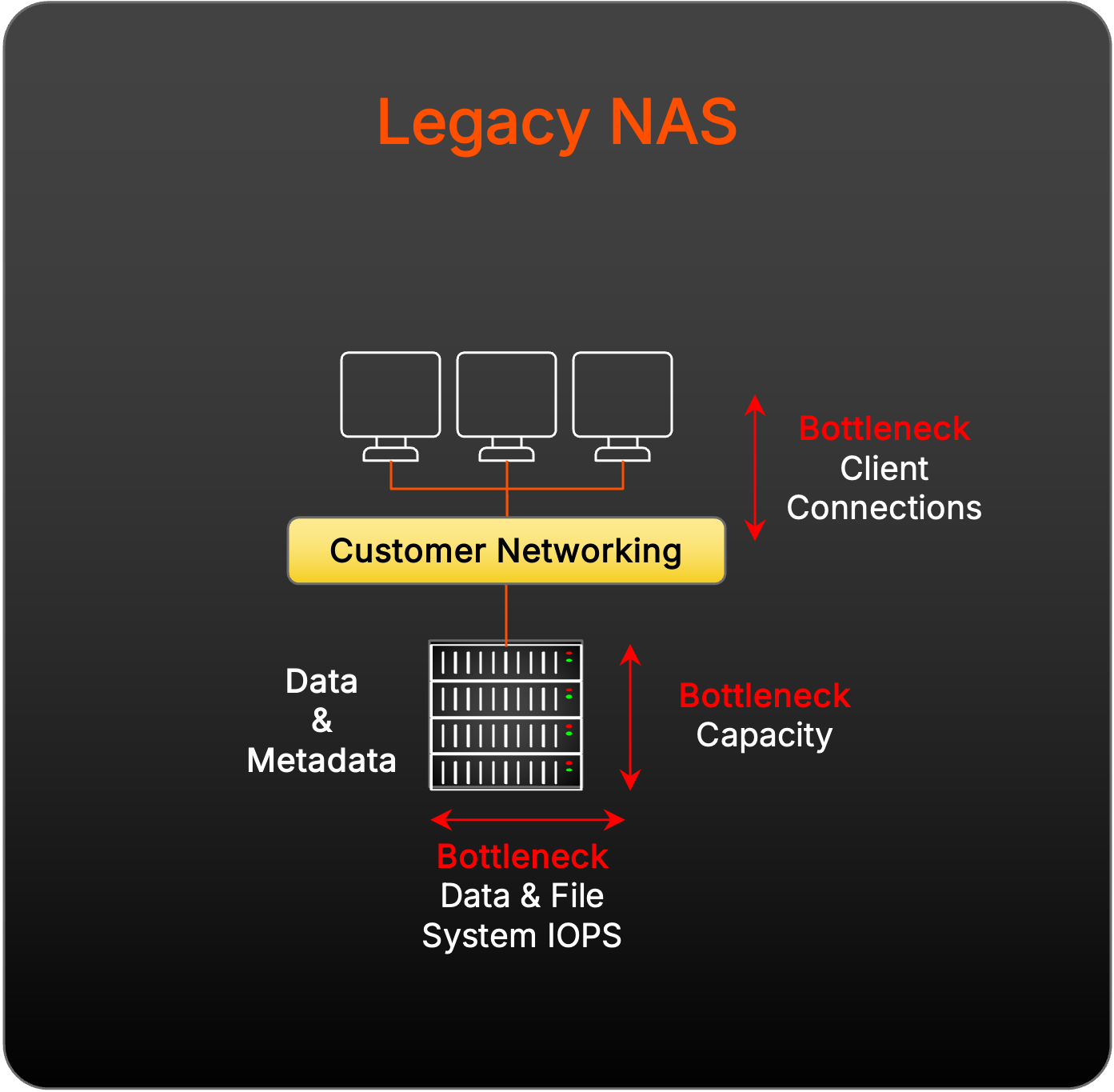
Retos de escalamiento con NAS tradicional
El diseño y la escalabilidad del NAS tradicional prohíben admitir el almacenamiento paralelo debido a su diseño de un solo propósito para dar servicio a los archivos compartidos operativos y a la incapacidad para escalar I/O linealmente a medida que se añaden más controladores.
Retos de escalamiento con los sistemas de archivos paralelos tradicionales
Incluso antes del auge actual de la IA, algunos proveedores de almacenamiento tradicional utilizaban sistemas de archivos paralelos especializados como Lustre para proporcionar un paralelismo de alto rendimiento para las necesidades informáticas de alto rendimiento. Si bien esto funcionó para varios entornos grandes y pequeños, es propenso a la latencia de metadatos, las redes extremadamente complicadas y la complejidad de la gestión, que a menudo se relegan a los doctores que supervisan sus arquitecturas HPC y los costes indirectos asociados cuando se escalan a necesidades más grandes.
Retos de las soluciones de datos y computación desagregados
Otros proveedores de almacenamiento han desarrollado sus soluciones no solo para confiar en un sistema de archivos paralelos creado específicamente, sino también para añadir una capa de agregación de computación entre los clientes de cargas de trabajo y los metadatos y los objetivos de datos:
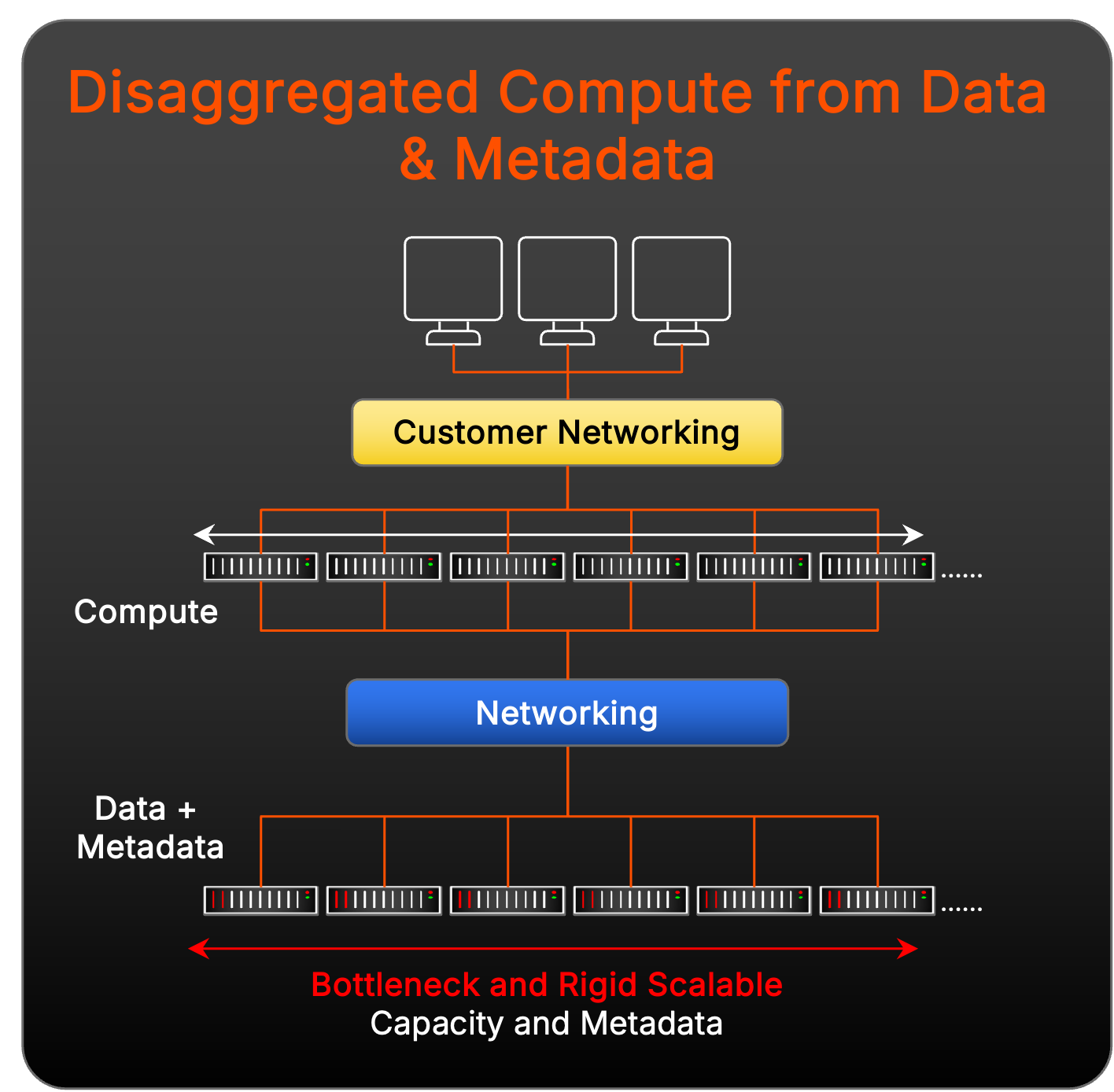
Este modelo sufre de rigidez de expansión y de más problemas de complejidad de gestión que el pNFS cuando se escala para lograr un rendimiento masivo, porque implica añadir más partes móviles con nodos de agregación de computación. Hay otro posible reto: el despliegue de funciones de acceso a datos desagregados en este modelo corre el riesgo de una latencia inesperada en la pila, porque su red se complica mucho más en la gestión del direccionamiento, el cableado y la conectividad con tres capas discretas en comparación con lo que se necesita para pNFS.
Además, a cada nodo de datos y metadatos se le asigna una cantidad fija de caché en la que los metadatos siempre se almacenan. Esta rigidez obliga a los datos y los metadatos a escalarse a gran velocidad, creando ineficiencias para las cargas de trabajo multimodales y dinámicas. Y, a medida que cambian las demandas de las cargas de trabajo, este enfoque de escalamiento lineal puede provocar cuellos de botella en el rendimiento y un sobreaprovisionamiento innecesario de la infraestructura, lo que complica aún más la gestión de recursos y limita la flexibilidad.
También estamos empezando
Nuestro anuncio de FlashBlade//EXA revoluciona el rendimiento, la escalabilidad y la simplicidad de las cargas de trabajo de IA a gran escala. Y acabamos de empezar.
Contacte con su equipo de Pure Storage para obtener más información sobre cómo estamos, una vez más, revolucionando el pensamiento convencional en uno de los segmentos de rápido crecimiento del sector.
Reúnase con nosotros en NVIDIA GTC 2025, del 17 al 21 de marzo. Reserve una reunión.
Explore pure.ai y nuestra página de soluciones de IA para obtener más información.

FlashBlade//EXA
Experience the World’s Most Powerful Data Storage Platform for AI
Join the Webinar
Discover the power of FlashBlade//EXA for AI workloads. April 24, 2005.



