

Today at Pure//Accelerate, our CEO Charlie Giancarlo laid-out Pure’s vision for the future of data center infrastructure – the Pure Data-Centric Architecture. You can read more about this vision in our launch blog. Data-Centric Architecture is going to be an exciting journey that will help your organization put data at the center of its infrastructure design, and as such the storage really matters.
Today we’re unveiling the seventh generation of our flagship FlashArray product line – the all-flash array that created the AFA category. We’ll make a case for why this new FlashArray represents a wholly new storage architecture – one that has the potential to unite the formerly disparate worlds of shared storage (SAN/NAS) and direct-attached storage (DAS), as well as the worlds of classic applications and modern scale-out applications. And we’ll make the case for why we believe that standardization on this new architecture can and will be swift – it’s a mainstream architecture you can start using today. It’s a pivotal day for storage – let’s dive in!
Remembering the Lessons from the Past
If you’ll permit me a short stroll down memory lane, take yourself back to 2009. Flash was just entering the scene, and the hottest storage company was Fusion-IO. The industry’s view of the flash opportunity looked something like this:

Flash was viewed as super-high performance, but came with a super-high price tag ($20/GB), and as such was a “niche” technology. Big Storage believed in a model of tiering/caching, where a little flash was used with a lot of disk to make it economic.
Pure was founded to up-end this picture. We believed that flash had the potential to be mainstream, but to do so we had to solve the core problems: make it economic (<$5/GB was our goal then!), make it reliable, and make it simple & adoptable. Indeed, a little company, called “Os76” at the time (with, oh gad, a MAROON logo) was born:

This recipe ultimately became the AFA category, and has since inspired many imitations. But most importantly, true positive change was unleashed in the storage industry. Storage became simpler, more efficient, and of course faster, and AFA now dominates the majority of new storage mindshare:

So what did we learn from this trip down memory lane? The magic comes not from making a technology, but from making it mainstream….that’s where the real innovation happens.
It’s Time to Re-Wire the Data Center
When we introduced our vision around Data-Centric Architecture, we talked about how the move to modern web-scale distributed applications was completely changing what’s required from storage. The net here is that storage has classically been delivered in two architectures: networked (SAN/NAS) and direct-attached (DAS):

Neither inherently good or bad, each has its own strengths. While networked storage has been the mainstay of business-critical applications for decades, DAS storage has seen a resurgence over the past few years in big data, analytics, web scale database, and HCI use cases.
At a high-level, the appeal of DAS is pretty simple: cheap commodity infrastructure, standardization, and linear scale per node addition.

What most folks have now figured out, however, is that the reality of DAS often isn’t this pretty. You don’t just run, say, Hadoop; your modern application pipeline might be 10 or 20 tools, each wanting it’s own “recipe” for the ideal scaling node. Once you standardize on a node you get locked-in, and every app suddenly has the goldilocks problem: something’s too big or too small, never the right amount of storage and compute. We won’t even mention managing node failures when you have 10s or 100s of racks – where a single bad SSD can take down a node. And if you get your sharding and node design wrong, it’s very difficult to start over. This is why we’re starting to see DAS infrastructure start to become disaggregated – HCI vendors are shipping storage-only nodes, and Hadoop vendors are starting to suggest disaggregating servers and storage. Maybe shared storage wasn’t such a bad idea after all?
And again, the reality – is that you’ve got both. You have classic scale-up apps and VMs, and you want to deploy new web scale applications that expect DAS. Are you just stuck with two different infrastructures?
Fast Networks & Protocols Change Everything
The advent of mainstream flash (fast storage with the performance to mix workloads well) is now being coupled with an onslaught of fast, cheap, pervasive networking – and this changes what’s possible. 25 Gb/s Ethernet is now commodity, 100 Gb/s doesn’t have a huge cost penalty, and 400 Gb/s is right around the corner. But more importantly, parallel storage protocols like NVMe & NVMe-oF have emerged to help us truly talk to storage over networks in an optimized way. Why is NVMe-oF, in particular, so important?

At the simplest level, it makes storage shared on a network perform almost as fast as storage “inside the box” or on the server’s PCIe bus. This enables shared storage to now take-on what use to be DAS-centric workloads in a more efficient manner. Perhaps more importantly though, today server CPUs spend lots of their actual time processing SCSI commands. In our testing, at high IO loads, this can be up to 20 or 30% of CPU time wasted! NVMe-oF is a fundamentally more efficient, offloaded protocol which eliminates this CPU tax – increasingly important in the post-Moore’s Law word where CPUs may not continue to make the advances we’ve been spoiled by for years. And finally – it’s just the missing parallel link in the puzzle – parallel apps can live on parallel servers which can now talk to storage over a parallel protocol, and storage devices can be parallel within all the way to the parallel flash. The true parallel performance of flash can be finally realized!

And so…what if? What if a single architecture could unite the worlds of SAN and DAS into a truly data-centric architecture, one that enabled fast reliable shared storage services to be delivered to stateless, diskless compute via fast parallel networks. Sounds like an entirely new kind of storage.
A New Category of Storage: Shared Accelerated Storage
The soothsayers at Gartner saw this transition happening as well, and actually coined a new term for this new type of storage – Shared Accelerated Storage. Despite the somewhat confusing acronym, we believe the name gets right at the essence of what’s new: SHARED access to ACCELERATED (fast) data for applications. This isn’t your father’s AFA.

The quote from Gartner here is pretty nice – NVMe-oF has the power to unite these two architectures. So what do we believe this new animal looks like? In a nutshell:

Shared Accelerated Storage is a new class of storage that enables diskless, stateless servers, to connect to shared storage via fast, converged networks that speak a parallel-optimized protocol (NVMe-oF). At the storage tier, then, a shared storage device with software that’s fully parallel-optimized speaks to flash over parallel NVMe protocol – a parallel, optimized architecture for flash from compute to flash chips – nothing speaking SCSI or pretending to be a legacy disk drive.
Just like the transition to flash – we believe there will be a lot of folks who try and retrofit NVMe and NVMe-oF, but to truly deliver Shared Accelerated Storage, you’ve got to design for it from scratch. At Pure, we’ve been building towards this transformation for years:

From our very first version of the Purity OS, designed for the parallelism of flash, to building software that did global flash management, we’ve designed our software for this new world. When we first shipped the FlashArray//M chassis in 2015, we built-in NVMe before the standard was even finalized, and shipped the world’s first dual-ported NVMe device as our NV-RAMs (now 25,000+ of these devices are running in production). With FlashBlade™ we then interfaced our software with raw NAND directly, removing the inefficiency of the legacy SSD form factor, giving rise to our DirectFlash™ software – which leverages NVMe to create highly-parallel communications to raw flash.
Meanwhile – we see lots of compromises from our competitors…continuing to retrofit their legacy disk arrays, leveraging NVMe flash as only a caching tier, continuing to rely on inefficient SSDs for flash, and ultimately failing to do the hard work of developing and optimizing their software for Shared Accelerated Storage. More on this later!
So is Shared Accelerated Storage for All?
Well, here’s where the wrinkle comes in – and it’s time to remember our history lesson. Today’s market approach to all-NVMe storage feels EXACTLY like flash circa 2009 – everyone in the storage industry seems to be seeing this as a new, exotic, high-performance, high-cost storage option.
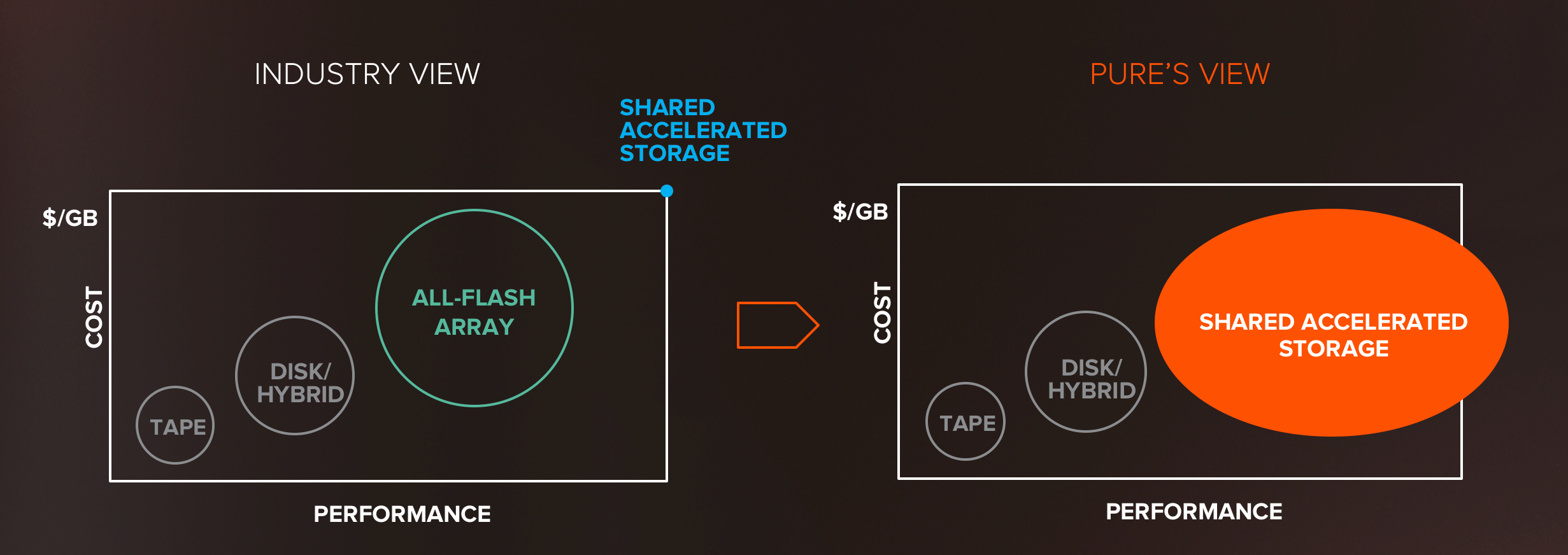
Dell-EMC went so far as to coin this new storage as “Tier 0” storage – something above classic Tier 1 arrays. Well, in Pure’s perspective, it’s again time to end the Tier 0 thinking. If we want Shared Accelerated Storage to truly impact data center architecture, it’s got to be mainstream. And we’re going to deliver on that TODAY.

When we launched FlashArray//X last year, it was the industry’s first all-NVMe array, and it begin our journey of bringing all-NVMe storage to the mainstream. Well today, we deliver on our vision with the all new FlashArray//X Family – we’re going “all in” with //X.
Today we’re introducing a new FlashArray //X10, //X20, //X50, //X70, and //X90, which deliver all-NVMe storage for every use case and price point in the data center. //X and //M now merge into a single go-forward product line that does it all:
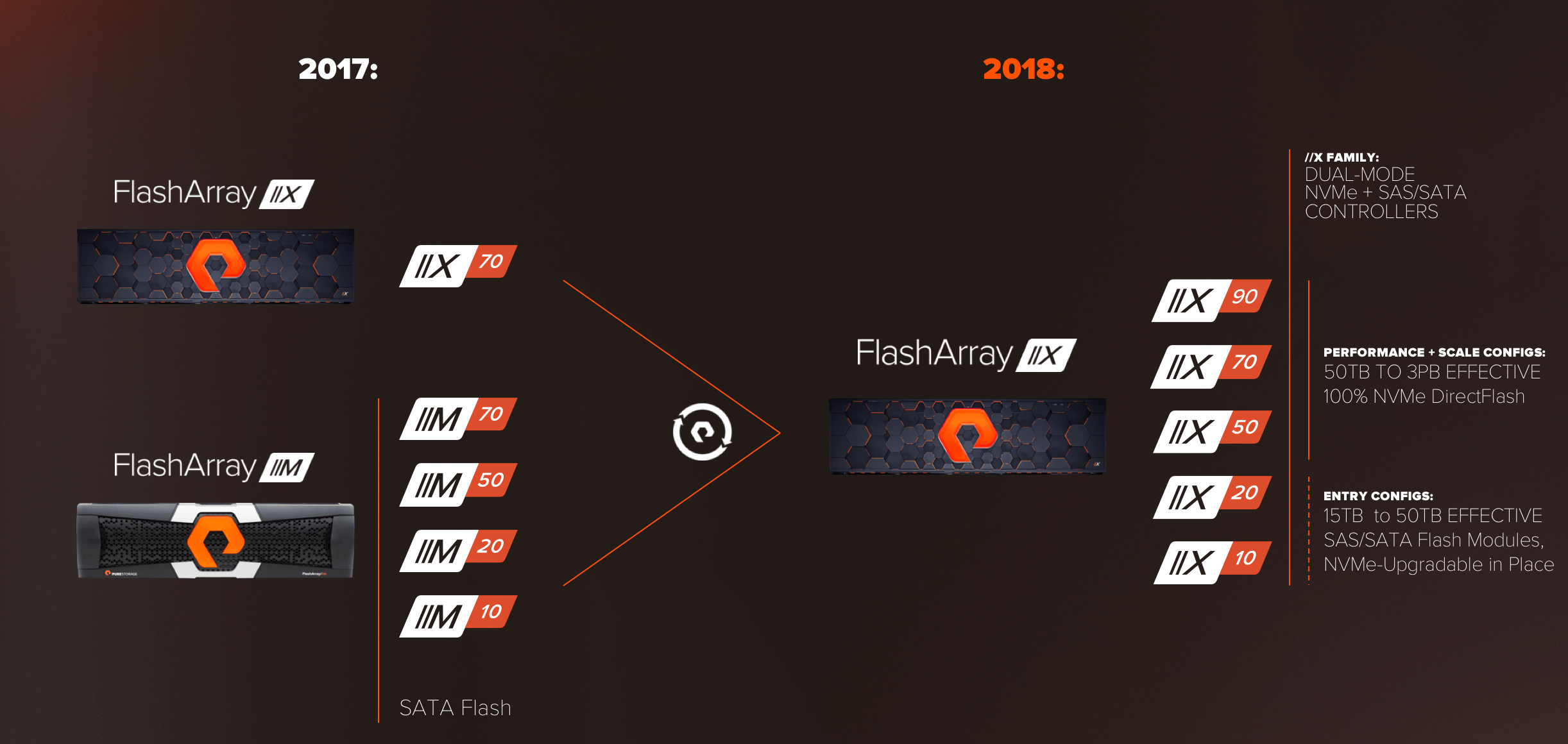
The entire //X family features our new dual-mode controllers, which can speak BOTH NVMe over PCIe AND SCSI over SAS into the //X midplane, which enables the same platform to be outfitted with our NVMe DirectFlash Modules, as well as our classic SAS/SATA Flash Modules. This makes for easy upgrades from //M (more on that later), but it also allows us to configure the product family for all use cases. Our mainstay arrays, //X50, //X70, and the new //X90 are only outfitted with all-NVMe DirectFlash modules, in 2.2 – 18.3TB capacities. This enables us to configure all-NVMe solutions from 50TBs effective up to 3PBs effective in the //X90. And for our entry-level products, the //X10 and //X20, these are configured from the factory with classic SAS/SATA Modules (we don’t make a DirectFlash Module smaller than 2.2 TBs today), but the controllers are fully-capable of supporting NVMe media for future in-place expansions.
The new FlashArray//X Family re-defines fast and dense:
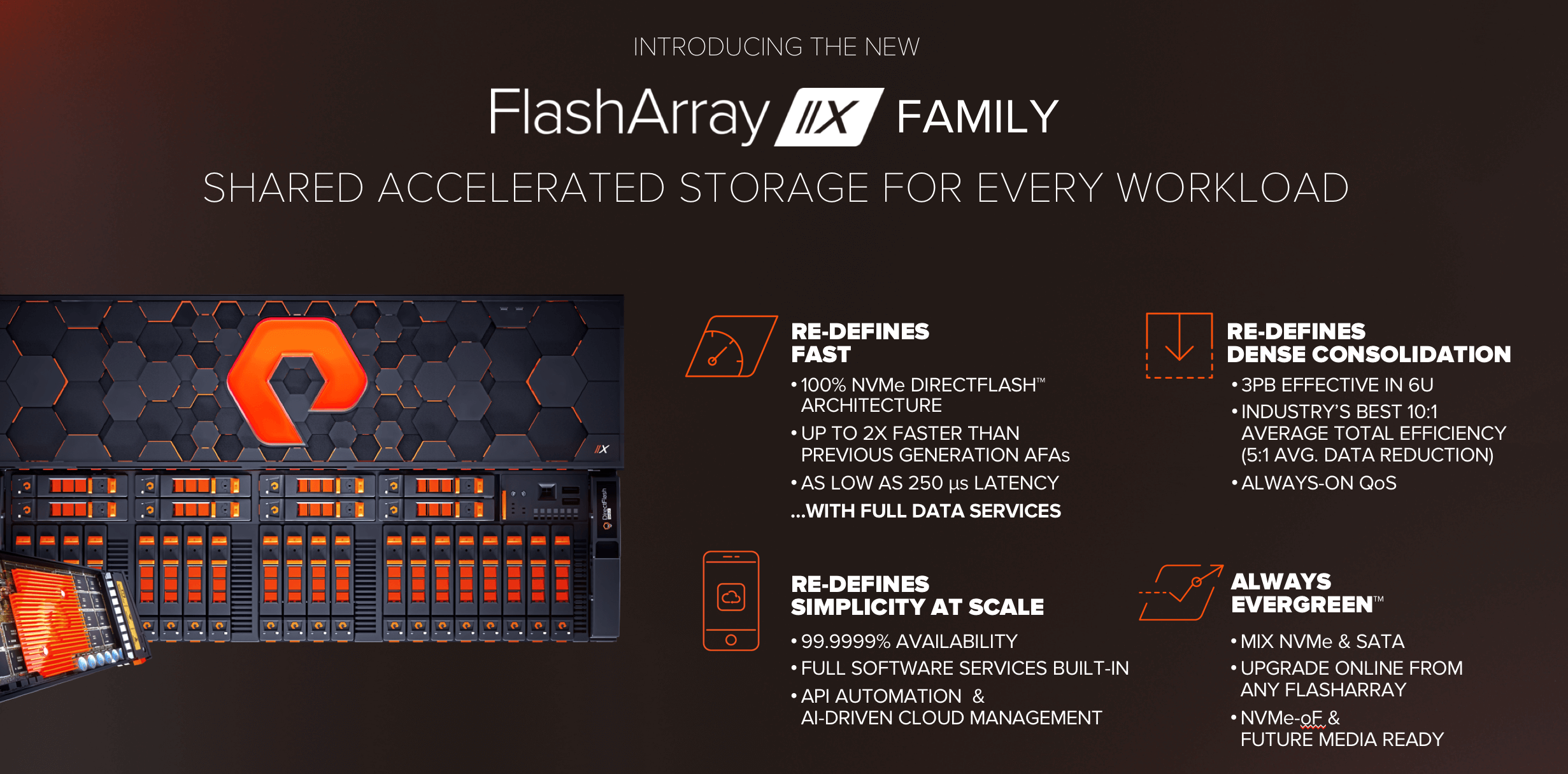
FlashArray//X is built on our DirectFlash architecture, which marries DirectFlash software for flash management with raw NAND delivered in our DirectFlash Modules. This delivers dramatically-faster performance and better efficiency than traditional SSDs – and only Pure has DirectFlash. To read more about DirectFlash – see this deep dive blog.
The 100% NVMe DirectFlash architecture delivers up to 2X the performance of our classic //M AFA, and delivers latency as low as 250 µs – all with full data services enabled (we believe in a world where far greater simplicity and data efficiency are a worthwhile compromise for a few scant µs).
All the new controllers are NVMe-oF-Ready. They come with onboard 25 Gb/s Ethernet and can be configured with NVMe-oF Ready 16/32 Gb/s Fibre Channel or 50 Gb/s Ethernet (and in the future 100 Gb/s Ethernet). We plan to ship NVMe-oF protocol support later this year via a non-disruptive upgrade (NDU) to software. But the best part – the specs you see here are using iSCSI and FC – //X will only get faster once NVMe-oF is enabled.
While the improved bandwidth and latency help all applications, the biggest benefit of the all-NVMe architecture with DirectFlash is that enables new levels of consolidation. //X90 delivers up to 3PBs effective in 6U. Purity’s market-leading data reduction (average 10:1 Total Efficiency, and 5:1 data reduction) ensure that a wide range of workloads reduce well, and our Always-on QoS ensures that mixed workloads play nice on the array for the highest performance consistency.
But best of all – //X is still a Pure FlashArray, and the simplicity, full software services, and effortless management from Pure1 that you’ve come to expect don’t change. But maybe most excitingly – the move to //X is Evergreen™. Existing customers can move from //M → //X non-disruptively, and either choose to just keep their SATA flash in-place and start adding NVMe DirectFlash, or they can use UpgradeFlex Capacity Consolidation to trade-in SATA flash for new NVMe Flash at much higher density. In a world where our competitors are shipping new products with no upgrade path – we’ve delivered now seven generations of FlashArray non-disruptive, data-in-place upgrades:

Faster + Denser – What’s Not to Like?
So what’s the real value of FlashArray//X? We’ve had the first-generation //X70 in the market for a year now, and it represents >20% of our revenue. The customer results have been astounding….here’s an example of these results from one of the earliest //X adopters, hosting company MacStadium.
At a very simple level, //X just makes everything faster, and there’s no one who doesn’t like faster. When competitors have launched all-NVMe products, we’ve seen them resort to the typical benchmarketing exercises to claim ultra-high performance specs. One competitor, for example, did their benchmarking just using small cache-hit reads, meaning the all-NVMe array wasn’t even using NVMe at all – just DRAM! We continue to feel that hero numbers don’t do customers or the industry any service, and we’d rather arm our field organization with a detailed performance sizing database they can use to best-design an //X solution for your workload.
For this launch, we’ve completed extensive performance characterization for //X comparing it to the market-defining all-flash array out there: the one and only FlashArray//M. Across a wide range of applications, //X has delivered substantially higher performance, even over classic iSCSI and FC SANs.
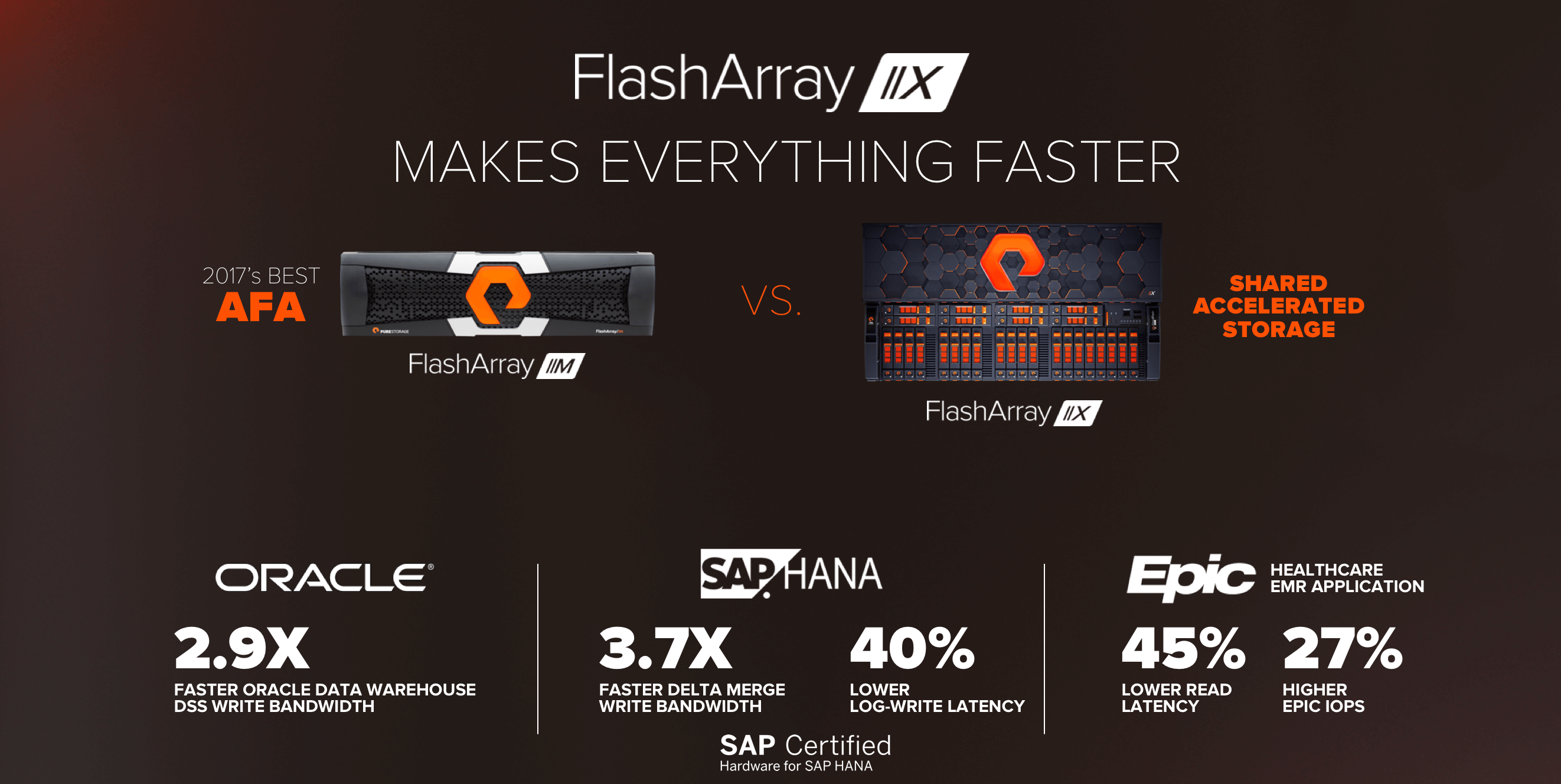
In our Oracle testing, we saw dramatic benefits in data warehouse testing, with a 2.9X improvement in DSS write bandwidth. For SAP HANA, we saw 3.7X improvement in delta merge write bandwidth, and 4consolida0% lower latency. And for Epic, the market’s leading healthcare EMR application, we saw 45% lower latency and 27% more EPIC transactions. These are high-level summaries. Read more details on these results in these blogs for Oracle, SAP, Epic, and more applications.
As great as faster application performance is, if we’re going to move to a truly Data-Centric Architecture it’s fundamentally about shared data – so consolidation matters. The true value of //X and all-NVMe is the performance to consolidate without compromise.
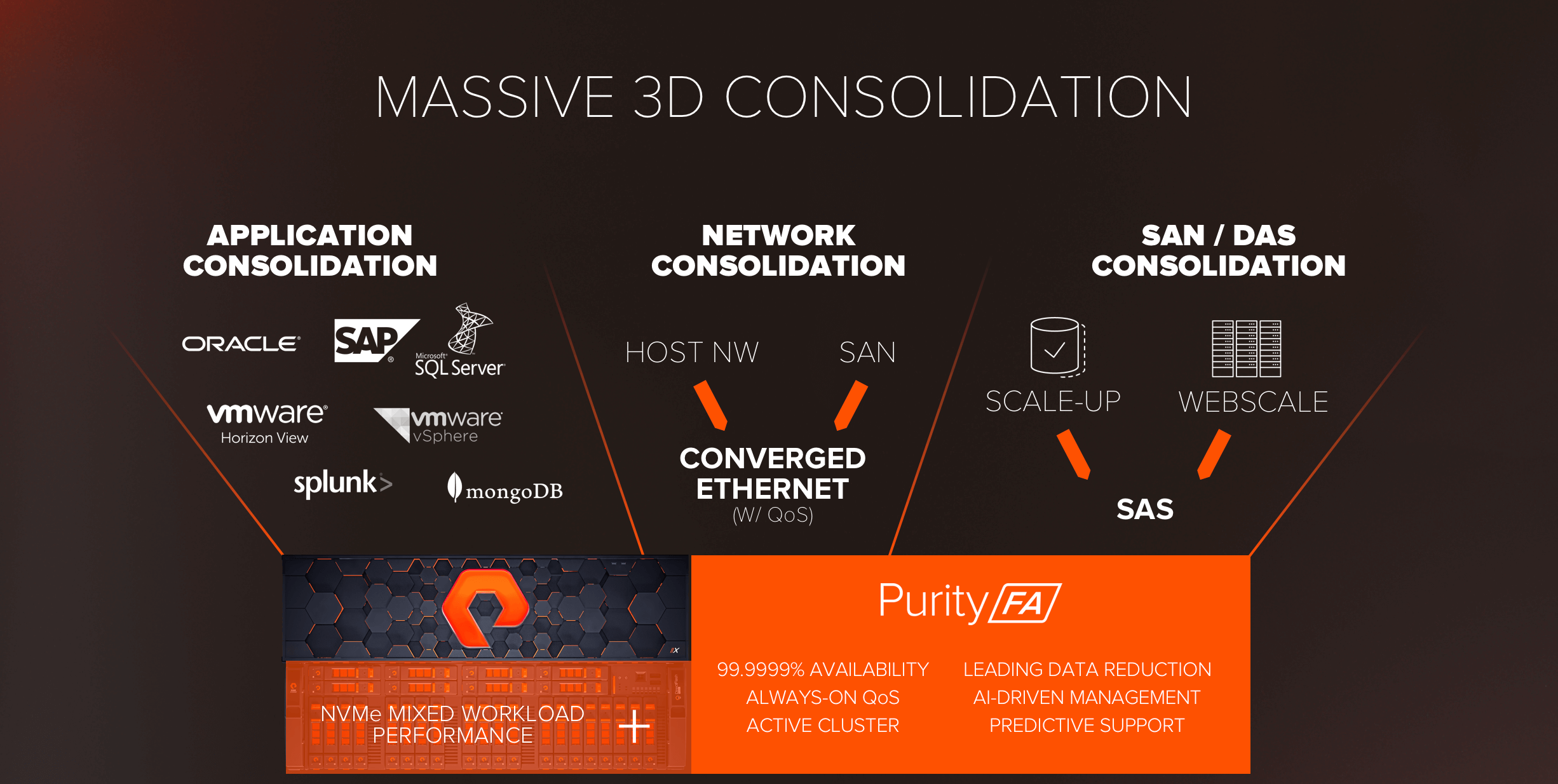
Shared Accelerated Storage and //X have the promise to deliver three dimensions of consolidation: consolidating a wide range of applications in one array, consolidating networks, and consolidating SAN and DAS infrastructure into one Shared Accelerated Storage pool.
When you are consolidating, performance density matters, and this is where our all-NVMe DirectFlash architecture really shines. While competitors ship 15 and 30TB SAS SSDs, these come with a real performance impact, and you’re far better off deploying 15 x 2TB SSDs in these retrofit arrays than a single 30TB SSD – but of course this sacrifices density. DirectFlash delivers the best of both worlds – ultimate density with our 18.3 TB DirectFlash Modules, with zero performance sacrifice – we can deliver the max performance of the array from just 10 DirectFlash Modules of ANY size.
Sometimes a picture is worth 1,000 words – here’s the density and consolidation value that DirectFlash brings compared to legacy retrofit architectures:
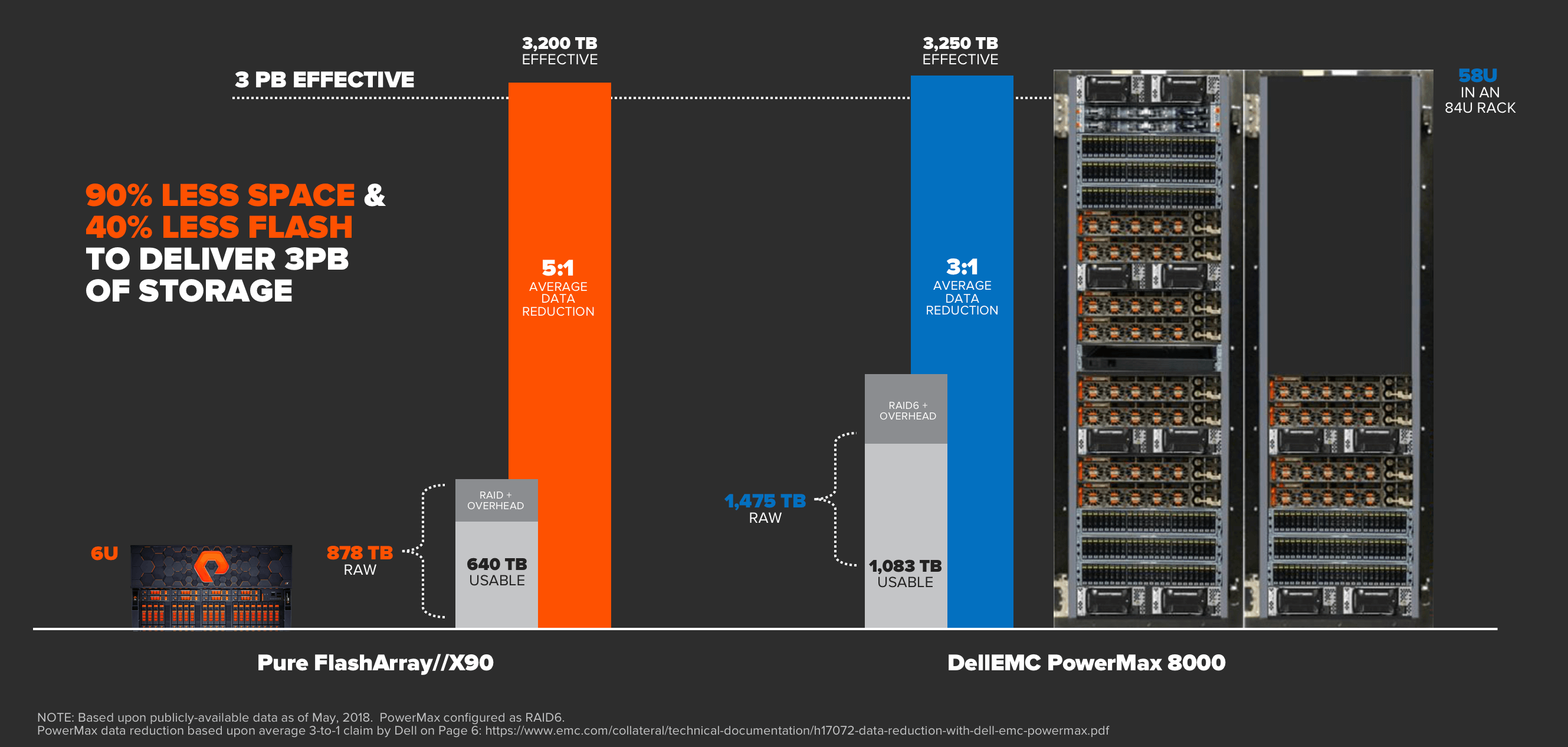
To compare a 3PB deployment, FlashArray//X can deliver 3PBs in just 3U, where one example of a competing retrofit architecture needs 1.5 racks or 58U to match this effective capacity. The difference is truly astounding, both in space savings as well as associated power and cooling cost savings.
So….What’s it Cost?
As we said earlier, our vision at Pure is to make Shared Accelerated Storage mainstream. Indeed, early attempts at all-NVMe storage were up to 10X more expensive than AFAs, and were doomed to fail. Over the last month we’ve seen several vendors introduce new products at the high-end of their portfolio, and be suspiciously quiet about cost.
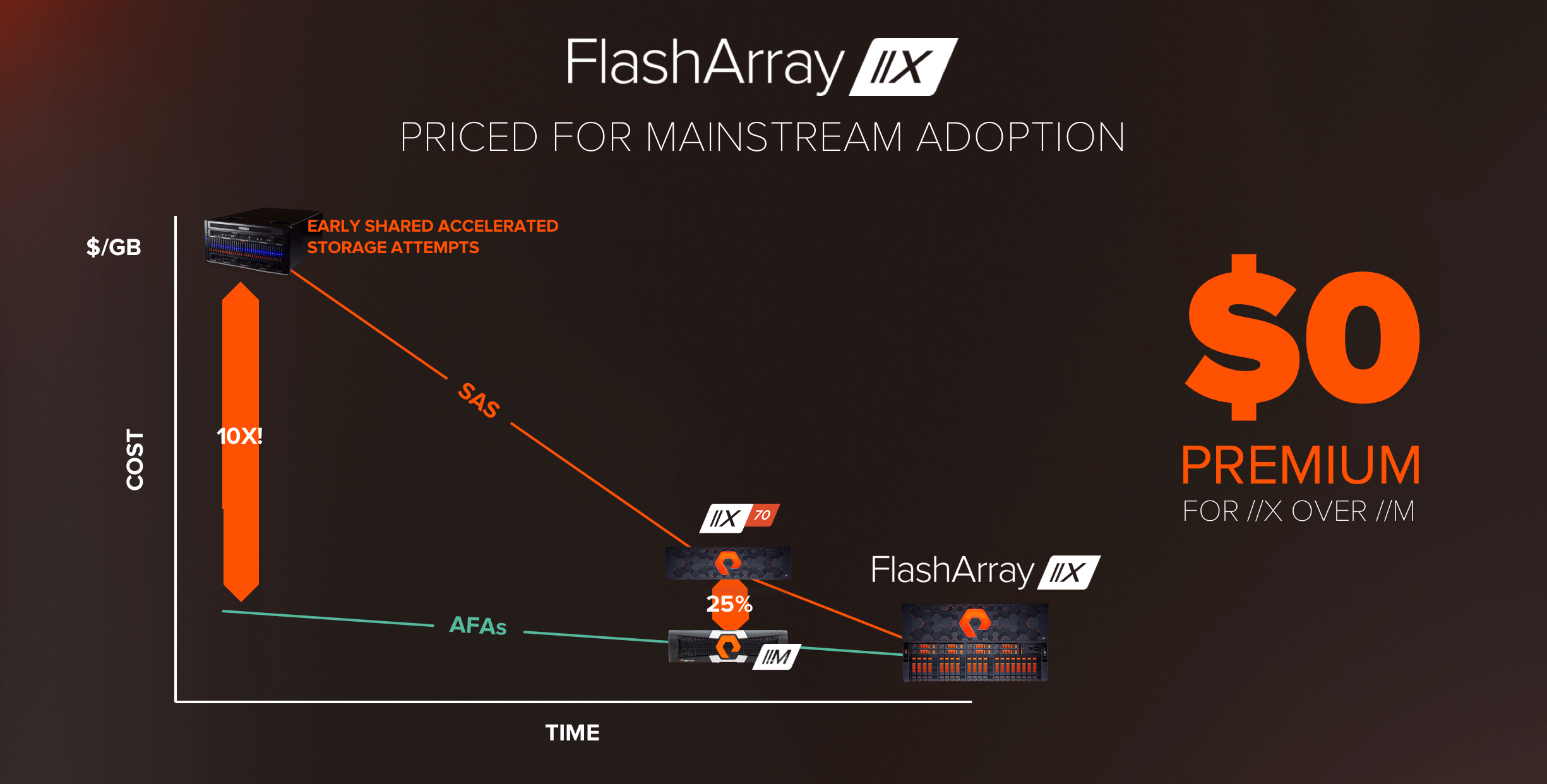
Last year when we introduced FlashArray//X we did so at a 25% premium over //M, which in 2017 was quite a feat. Dual-ported NVMe SSDs were about 2X the cost of SAS SSDs, so this really showed the value of our DirectFlash architecture. Well – it’s 2018 – and as we said we’re going all-in. We’re happy to announce that we’ve eliminated the premium, //X is being introduced at cost parity with our //M prices on a like-for-like effective capacity basis, making the move to all-NVMe Shared Accelerated Storage truly a no-brainer*.
You may ask: How can we do this? Easy – we’re the only ones with DirectFlash storage and the DirectFlash Software. DirectFlash enables us to leverage raw NAND, and deliver on the true potential of NVMe. Our retrofit competitors are stuck leveraging expensive dual-ported NVMe drives. We’ve done the hard work to optimized from software → NAND, and that allows us to drive Shared Accelerated Storage into mainstream price points.
It’s Time to Take Your Architecture Forward
Well, there you have it. An all-new FlashArray//X Family, built to deliver all-NVMe performance for every workload. It’s here, it’s affordable, and it’s available to order today (and ships June). The FlashArray//X will help you consolidate your classic SAN and your next-gen webscale DAS workloads, dramatically improve the performance and efficiency of your environment, and ultimately move down the path to a truly data-centric architecture. We look forward to helping you on the journey!
For more information on announcements this year at Pure//Accelerate, check out our overall launch blog, Data Centric Architecture Powers Digital Business.
*$0 Premium is the average across the entire //X product line, actual //M vs. //X pricing varies slightly by SKU and specific capacity configuration. Please see your Pure Storage rep or partner for specific pricing details.



