


This blog originally appeared in 2017. Get the latest on FlashBlade Unified Fast File and Object Storage.
The world is witnessing a massive unstructured data explosion with a multitude of devices generating 10s of zettabytes (that is 1 followed by 21 zeros or 10^21). An IDC study on data explosion projects 50 zettabytes of data being generated annually by 2020.
The main contributors to this data growth include new IoT devices, wearable devices, self-driving cars, satellite data, casino cameras/machines, building management data, transportation logistics data, manufacturing factory data, billboard data, credit card transaction data, surveillance cameras, smart meters, and so on [see picture below]. In case you are wondering why a Pure Storage FlashArray is in the mix (see picture below), we have several thousand arrays that are in deployment and they call home periodically. The arrays have generated several petabytes worth of log data that we use for predictive support.

Challenges with data growth
Dealing with massive unstructured data poses a huge challenge.
- First and foremost manageability, scalability, and simplicity have to be an integral part of storage solution.
- Some of the data may be crucial to business operation, there is a huge need to do real-time data analytics to separate the signal from noise.
- Traditional file systems or NAS solutions are not built to handle billions of small/big unstructured data files.
- Lastly, a top concern of CIOs is recruiting qualified and trained storage professionals to manage zettabytes of data.
A new approach for solving data growth problems: Object Storage
Instead of exposing data in terms of blocks and files, Object Storage introduces the concept of objects or blobs of data stored in containers called buckets. Object Storage was designed for scale and for large unstructured datasets i.e billions of objects.
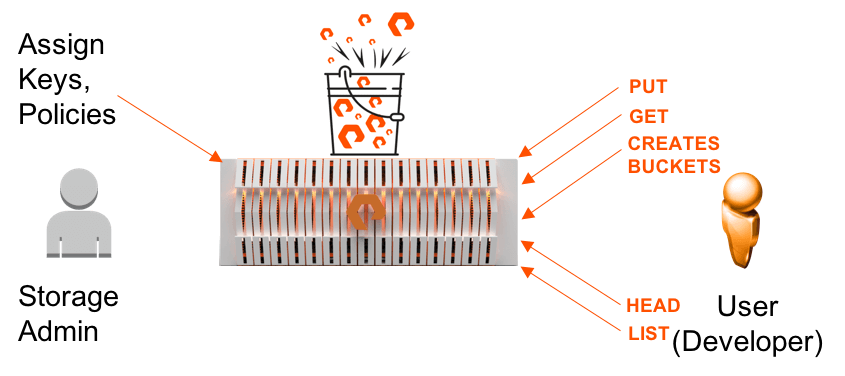
Object Storage has no dependency on the operating systems and are not like hierarchical filesystems (provides a flat namespace). There is no need to do LUN provisioning, creating or mounting filesystems on a server and exposing it to user applications. The administrator creates user access key/secret key and set user/bucket level policies, the users can then create buckets and access objects in the buckets. Users access the objects via a simple web interface using RESTful HTTP APIs from their applications. The most popular API models are Amazon Simple Storage Service™ (S3) and OpenStack® Swift with Amazon S3 APIs being the most popular in terms of adoption. Lots of cloud native applications have made Object Storage and S3 as their primary model for their data consumption. As there is little or no manageability overhead most Object Storage systems are very simple to manage. Scalability on the other hand could get out of hand when you are dealing with traditional spinning media.
Object Storage and Pure Storage FlashBlade
During the Pure Storage annual technology event //Accelerate 2017 in June 2017 we announced our biggest software launch in Pure’s history. A detailed blog on all the 25+ features can be found here. A quick abstract of the software release for both FlashArray and FlashBlade is summarized below.

From the FlashBlade Purity//FB perspective, Object Storage with S3 compatible APIs was one of the major notable feature. Here are the key points on the Object Storage implementation:
- Ground up native implementation to maximize scale and performance (not a gateway or a shim layer on top of nfs)
- Scales to Unlimited objects (limited by FlashBlade capacity)
- 10+GB/s of performance with low latency
- Different namespace from Filesystems (NFS / SMB / HTTP)
- 100% S3 Compatible APIs to start with a future proof design to add support for others
- Buckets, Objects are sharded across various FlashBlade blades
- Pure Simplicity
Purity //FB version 2.0.5 supports the following S3 APIs:
- Bucket CREATE, DELETE, LIST, HEAD
- Object PUT, GET, DELETE, LIST, HEAD
- Multipart upload
- Access to ObjectStore via AccessKey/SecretKey for users
- R/W Bandwidth, Latency and IOPS
- Metadata ops and Space reporting
We have tested with various AWS S3 SDK including Java, Python, GO, C#, and .NET. In future blogs we will talk in detail on how to use FlashBlade S3 compatible APIs.
We will explore the inner workings of the Object Storage implementations on FlashBlade and provide example code demonstrating the supported APIs in future blogs.



