

Storicamente, nelle architetture legacy di analisi dei dati, le componenti di compute e quelle di storage sono sempre state profondamente accoppiate.
Il compute esegue le istruzioni per l’elaborazione dei dati e svolge anche funzioni di controllo gestendo la logica di un’applicazione, lo storage è responsabile di mantenere i dati sempre disponibili quando richiesto dalla componente di compute.
Abbiamo già esplorato in un post precedente le dinamiche di evoluzione delle applicazioni moderne di analytics e come queste siano evolute in modo significativo nell’ultimo decennio: oggi i sistemi devono gestire ordini di magnitudine superiore di dati rispetto solo a pochi anni fa e la frequenza di trattamento, così come la varietà del dato sono cambiate radicalmente.
Con le possibilità offerte dalle tecnologie attuali e il cloud – sia esso pubblico o ibrido – disaccoppiare e avere la possibilità di scalare in modo indipendente il compute dallo storage si traduce in un migliore utilizzo delle risorse e conseguente capacità d’analisi più profonda e performante, maggiore flessibilità e grande risparmio sui costi.
Nel post analizzeremo i vantaggi di questa scelta architetturale verso cui molte piattaforme di analisi dei dati stanno convergendo velocemente: sto pensando a Splunk con Smartstore, Vertica in modalità EON, oltre a tutte le possibilità offerte dagli applicativi di modern analytics che possono interagire con storage remoto S3 o NFS.
Background
Negli anni abbiamo assistito ad un fiorire di numerose tecnologie hardware e software che hanno supportato le differenti forme di Big Data e Analytics. Dai primi sistemi di supporto alle decisioni (BI e DWH) fino ai Big Data / Data Lake e poi analytics moderni.
L’approccio originale (sulla sinistra) era guidato dalla necessità di tenere traccia di cose che già conosciamo: strutturiamo i contenitori dei dati a seconda del tema e della finalità e poi li popoliamo attraverso procedure di estrazione, trasformazione e caricamento di dati.
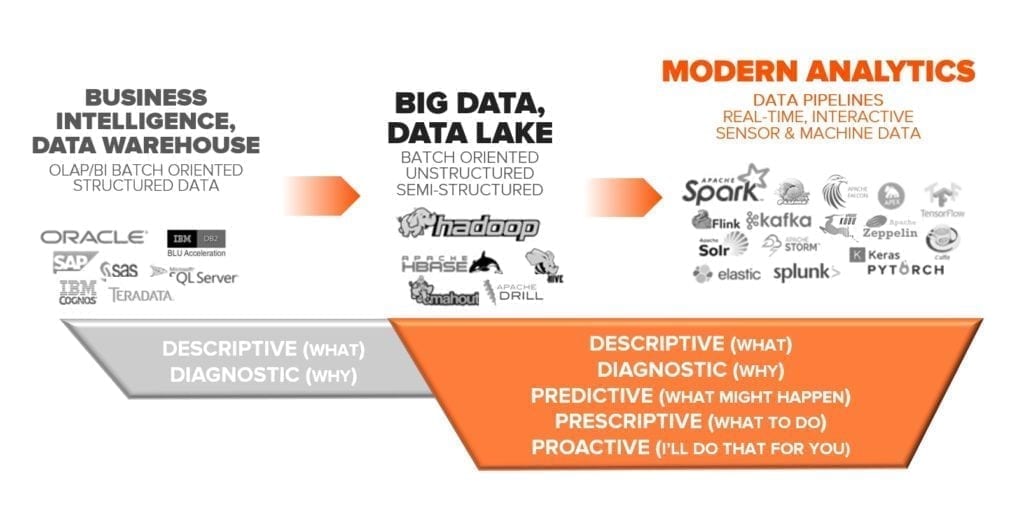
Tipicamente, in un contesto aziendale, il perimetro della raccolta si fermava ai sistemi informativi interni, gestendo operazioni minimali di innesto di dati strutturati esterni. Raccogliamo e valorizziamo i dati per rispondere a domande che in realtà già conosciamo.
L’approccio della fase storica successiva, quello dei Big Data è: non solo teniamo traccia dei dati, ma li utilizziamo per la scoperta di nuove forme di conoscenza perché non conosciamo a priori le domande da porre ai dati raccolti. Prima raccogliamo i dati, poi li gestiamo e analizziamo, siano essi strutturati o non strutturati. Il perimetro può essere esteso a fonti provenienti dall’Internet: raccogliamo dati anche al di fuori del perimetro dei miei sistemi informativi interni.
In questo passaggio, come già anticipato, ci sono tre grossi cambiamenti: la velocità e varietà del dato e il suo volume.
Quello che non è cambiato per nulla è nell’infrastruttura: storicamente, le grandi implementazioni di Data Warehouse e Big Data, specie con Hadoop, hanno sempre imposto la co-locazione di compute e storage all’interno dello stesso server fisico.
Il contesto in cui è nato Hadoop
All’inizio degli anni 2000, proprio con l’introduzione di Hadoop, il tipico data center aveva connessioni di rete da 100 Mbps a 1 Gbps: la movimentazione massiva di dati da un server fisico a un altro è sempre stata particolarmente lenta, anche per i parametri dell’epoca.Le architetture software erano monolitiche e qualsiasi applicativo con necessità di eseguire simultaneamente numerosi processi di elaborazione doveva necessariamente condividere le risorse d’infrastruttura.
Tutte queste realtà ambientali hanno influenzato lo sviluppo di Google File System (GFS), che, a partire dal 2003, divenne il progetto per l’architettura Hadoop 0.1: un file system distribuito a basso costo (HDFS) e un framework di calcolo distribuito (MapReduce).
Hadoop sfrutta commodity server a basso costo con storage locale accoppiato: unità Hard Disk locali dei server come storage e MapReduce per l’elaborazione parallela di grandi volumi di dati.

Sebbene ci siano stati miglioramenti con l’introduzione di Hadoop 3.0, come si legge tuttora nella documentazione Hadoop, i principi di design sono basati su presupposti del contesto di quasi 17 anni fa: i guasti hardware sono frequenti (se non la norma), la rete è lenta, i dati sono acceduti sequenzialmente e in batch massivi.
Le complicazioni di Hadoop nel contesto attuale
Di fatto nell’architettura Hadoop è necessario spostare l’elaborazione vicino ai dati, per sfruttare la disk locality ed ottimizzarne le prestazioni di lettura e scrittura.
Per una questione di resilienza, il file system è obbligato a replicare ogni dato più volte e distribuisce le copie ai singoli nodi, posizionando almeno una copia su un server diverso rispetto agli altri.
Di conseguenza, i dati sui nodi che si arrestano in modo anomalo possono essere ricercati altrove all’interno di un cluster. Con più copie di ogni unità di dati su più server, possiamo portare il compute vicino allo storage e questo riduce anche i requisiti di banda.
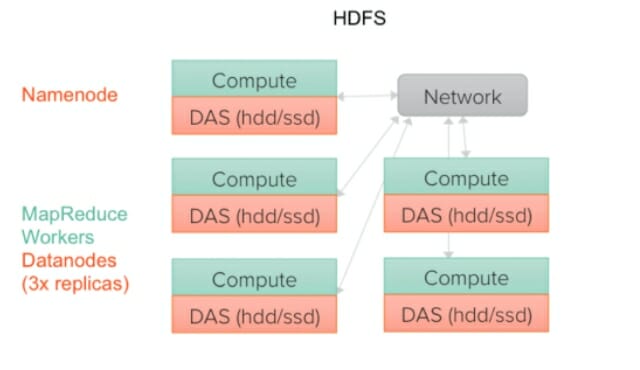
Una grande svolta per il momento storico della nascita di Hadoop e sicuramente una implementazione efficiente per le risorse (e relativi limiti) disponibili all’epoca.
Sicuramente una delle complicazioni nel tempo è che è sempre stata necessaria molta cura per massimizzare il paradigma della co-localizzazione per garantire la “data locality”.
Tuttavia, l’effetto collaterale più importante di questa impostazione è che il compute e lo storage non possono essere ridimensionati in modo indipendente.
Di fatto si genera una situazione di estrema rigidità: compute e storage possono essere aggiunti come unità inseparabili e non indipendenti. Ma come ben sappiamo oggi, la flessibilità di poter disporre di queste risorse in modo indipendente è fondamentale.
In questo modello, per scalare, è necessario approvvigionarsi di nuovi server, installare software, testare e convalidare che il sistema sia pronto per l’uso, esercizio che spesso richiede giorni o settimane per essere completato.
L’evoluzione degli ambienti e dei requisiti verso Modern Analytics
Molto è cambiato dai tempi iniziali di Hadoop.
Il mondo di oggi si muove più velocemente che mai: il modo in cui le persone acquistano beni di consumo sta cambiando, il modo con cui le aziende comunicano si sta trasformando, così come le modalità con cui le aziende raggiungono i propri clienti.
Il dato ha conquistato una centralità fondamentale in tutti i processi di trasformazione digitale (DX): opportunamente trattato consente di convertirsi in “actionable insight” che permettono alle organizzazioni di innovare e muoversi più agilmente rispetto ai competitor offrendo prodotti differenzianti e servizi di valore ai propri clienti.
Sebbene anni fa Hadoop fosse l’unico strumento ampiamente disponibile, oggi le organizzazioni hanno una pletora di strumenti a loro disposizione.
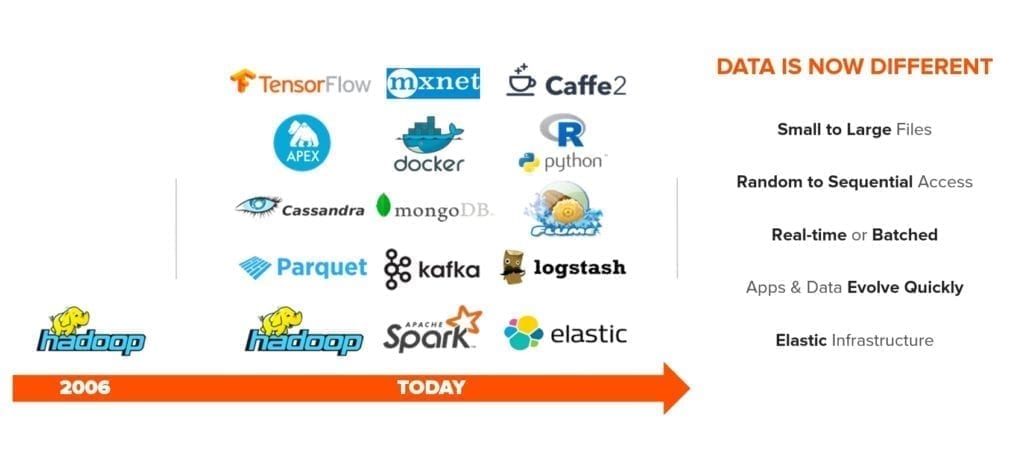
Il dato, nei suoi attributi, è cambiato e continua a cambiare.
I volumi sono diventati enormi, petabyte ed exabyte. Il dato ora è veramente dinamico e a differente velocità: vogliamo gestire dati in streaming in tempo reale, così come continuare a lavorare batch, vogliamo trattare file molto piccoli (e.g. log) oppure molto grandi (e.g. video), e la lista continua.
Una nuova classe di strumenti sono nati e si sono affacciati sul mercato, così come le tecnologie di base e d’infrastruttura hanno subito una fortissima accelerazione.
Come è cambiata l’infrastruttura
Sia le prestazioni delle CPU sia della rete sono cresciute molto rapidamente: oggi i Data Center hanno una velocità media della rete di 200 Gbps e latenze da/verso lo storage estremamente basse.
Le densità degli storage centralizzati sono aumentate notevolmente, così come la semplicità – viceversa i costi dello storage all-flash ad alte prestazioni tendono a diminuire.
Dal punto di vista applicativo e dei modelli di I/O, HBase, Hive, Pig, Impala e Spark stanno sostituendo MapReduce nella maggior parte delle distribuzioni. A differenza di MapReduce, infatti, che era orientato al batch, le applicazioni più recenti sono più interattive. I dati non sono più statici. Tutto ciò ha portato a nuovi schemi I/O e requisiti di archiviazione.
Inoltre, nell’ultimo decennio, le aziende si sono abituate ai vantaggi di agilità, flessibilità e riduzione dei costi della virtualizzazione. Il bare metal sta perdendo trazione e i container sono emersi come una opzione di virtualizzazione praticabile e concreta. Il paradigma del pay-as-you-go tipico dei modelli a consumo e del cloud computing, sta guadagnando terreno.
I data analyst e i team di data science vogliono sperimentare agilità e flessibilità del cloud, insieme al risparmio sui costi generali e in particolare di infrastruttura.
Il paradigma di replicare i dati su più nodi in un cluster e consentire la co-location per carenza di valide alternative non sta più in piedi, così come il costo e la manutenibilità di più repliche di dati.
Insomma, non è più pratico “avvicinare” o accoppiare il compute allo storage.
Possiamo pensare, in maniera molto efficiente, di non spostare più dati da una posizione fisica a un’altra. Possiamo condividere il dato e le tecnologie ci consentono di ottenere lo stesso tipo di resilienza senza dover pagare il pegno delle repliche del dato.
Stanno emergendo nuove generazione di database che disaccoppiano il calcolo e l’archiviazione: Vertica, Splunk nel modello SmartStore, Apache Drill, Hive, Spark, Pivotal HAWQ, Snowflake, AWS Athena e Redshift sono alcuni esempi di questo nuova generazione di motori di query disaccoppiati.
Anche la comunità open source ha abbracciato il disaccoppiamento di compute e storage e la stessa comunità Hadoop, con Hadoop 3.0, ricerca modalità alternative per superare il paradigma della replica dei dati (sebben questo ponga ulteriore domanda di CPU e rete).
I 4 vantaggi di disaccoppiare compute da storage
Oggi il dato deve essere messo al centro e condiviso, deve essere reso disponibile affinché possa essere usato da più divisioni aziendali e da più processi. Il valore del dato sta soprattutto nella capacità di essere condiviso e interpretato da più attori allo stesso modo.
Disaccoppiare compute da storage offre almeno quattro vantaggi.
Scalare in maniera indipendente compute e storage
L’accoppiamento stretto di compute e storage impone di ridimensionare entrambi allo stesso momento, essendo di fatto unità inscindibili: questo generalmente porta a spreco di risorse.
Il disaccoppiamento, invece, garantisce la libertà di poter aggiungere maggiore capacità di archiviazione, senza essere costretti ad aggiungere compute. Questo si traduce in grande risparmio di costi d’infrastruttura e una manutenzione più economica.
Pensate ad esempio ad una situazione classica che si può presentare in una architettura di log analytics: se devo passare da una retention dei log da 12 mesi a 24 mesi, posso aumentare la capacità senza necessariamente aggiungere nodi di compute.
Copia singola dei dati, pur mantenendo (o addirittura migliorando) il grado di affidabilità
Disaccoppiando compute e storage, più cluster di calcolo che eseguono Spark, Kafka, MongoDB, Cassandra o strumenti di data science come TensorFlow possono condividere l’accesso a repository di dati comune. Anche questo porta a un notevole risparmio sui costi storage e al contempo mantiene o eleva, come nel caso di FlashBlade, il grado di affidabilità.
Abilitare lo sviluppo di applicazioni agili
Con l’utilizzo di uno storage condiviso di livello enterprise, disaccoppiato dalle risorse di compute, è possibile sfruttare funzionalità di clonazione dei dati oppure servizi di snapshot per proteggere il dato in maniera rapida ed efficiente.
Ma ancor più interessante è la possibilità di adottare più rapidamente le nuove tecnologie nei layer di compute e storage disaccoppiando anche i relativi cicli di vita, elemento fondante dei contesti di analytics con Kubernetes.
Kubernetes si è evoluto per supportare un’interfaccia di storage flessibile chiamata Container Storage Interface (CSI), che consente a qualsiasi storage di offrire servizi attraverso un’interfaccia ben definita. Kubernetes offre le funzionalità di scalabilità e orchestrazione per distribuire applicazioni di analisi dei dati ad alte prestazioni. Il modello a container è molto più adatto per applicazioni di analisi dei dati con scalabilità orizzontale ad alte prestazioni rispetto all’approccio tradizionale VM.
In questo contesto Pure offre una perfetta integrazione con i framework di orchestrazione dei container, come Kubernetes, con funzionalità di provisioning intelligente dello storage, ridimensionamento elastico e ripristino trasparente. Con Pure Storage Service Orchestrator (PSO) gli sviluppatori possono consumare risorse storage attraverso una semplice API di Storage-as-a-Service e possono fruire dell’agilità del cloud pubblico con l’affidabilità e la sicurezza dell’infrastruttura locale.
Distribuzioni cloud ibride
Compute e storage disaccoppiati consentono l’utilizzo del cloud computing insieme allo storage on-premises: si possono combinare o abbinare le risorse a seconda della natura e del ciclo di vita del carico di lavoro. Ad esempio, durante la fase di esplorazione di carichi di lavoro ML, che sono ad alta intensità di calcolo, si può decidere di usare il compute del cloud insieme allo storage aziendale locale.
Oppure le organizzazioni possono generare actionable insight tramite l’integrazione di dati da systems of record o altre sorgenti autoritative di un ambiente privato con system of engagement o applicazioni customer-facing residenti su un cloud pubblico.
Il dato ha una gravità: qualsiasi organizzazione deve porsi la domanda di dove devono risiedere i dati e come questi debbano interagire con i processi di analytics, domande sulle quali è opportuno riflettere fin dalle primissime fasi di disegno architetturale. Anche i requisiti legali e normativi incidono sulla localizzazione del dato: molti paesi hanno leggi sulla sovranità del dato che impediscono lo spostamento o il trattamento di dati personali, finanziari e di proprietà intellettuale attraverso i confini nazionali.
Conclusioni
Disaccoppiare e avere la possibilità di scalare in modo indipendente il compute dallo storage si traduce in un migliore utilizzo delle risorse e conseguente capacità d’analisi più profonda e performante, maggiore flessibilità e grande risparmio sui costi.
Ulteriore grado di flessibilità nell’era moderna è avere un unico hub di dati (un “Data Hub”) per consolidare tutti i silos di dati in un’unica infrastruttura storage in grado di gestire tutte le applicazioni che fanno un uso intensivo dei dati.
Sempre più piattaforme di analytics stanno convergendo velocemente verso una modalità che prevede il disaccoppiamento dello storage dal compute: vi invito a leggere i miei due post precedenti che riguardano Splunk con Smartstore e Vertica in modalità EON.
Entrambe le architetture poggiano sul nostro storage all-flash scale-out ad alte prestazioni, FlashBlade, che vi invito ad approfondire a questa pagina.
Contattatemi per ulteriori informazioni, sarò felice di aiutarvi.
Luca Rossetti Systems Engineer
T @lucaR055



