


“People who are really serious about software should make their own hardware.”
Almost 50 years ago, Alan Kay, one of the foremost computer scientists of our age, spoke these words. Since then, some of the most innovative companies globally have followed his advice. It’s inspired some of the greatest products we have today. At Pure Storage®, we’ve followed this approach from the beginning in our relentless pursuit of efficiency in all dimensions. It’s how we continue redefining the storage industry.
Today, we’re excited to announce the latest addition to our portfolio of cutting-edge storage solutions: FlashBlade//S.

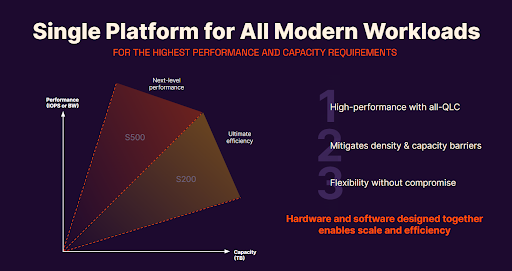
FlashBlade//S builds on the simplicity, reliability, and scalability of the original FlashBlade® platform, with a unique modular and disaggregated architecture that enables organizations to unlock new levels of power, space, and performance efficiency using an all-QLC flash design.
FlashBlade//S: A Solution for Tomorrow’s Challenges
According to most analyst estimates, unstructured data will quadruple by 2026 and account for four-fifths of all data growth over the next five years. Powered by modern, machine-generated workloads, unstructured data is a major customer challenge. The unpredictable nature of unstructured workloads, the need to simplify storage management, and the desire to end the rigidity of traditional inflexible platforms have necessitated a new storage platform. This is where FlashBlade//S comes in.
Overview
FlashBlade//S gives organizations an expandable, scalable platform with cutting-edge data capabilities—without growing complexity. It’s a seamless solution that brings together fast file and object data with co-designed hardware and software. This unique design means:
- Capacity and performance can be updated independently and scaled flexibly and non-disruptively as business needs change.
- It provides future-proof upgradability and investment protection. Customers maintain availability, reduce waste, and keep data secure through unprecedented change.
- It can be consumed as a service to match customers’ growth ambitions.
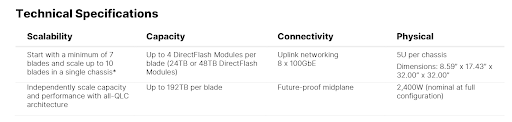
In a single 5U chassis, FlashBlade//S can store almost 2PB of raw data. This unmatched performance and environmental efficiency in contrast to any other scale-out storage solution on the market today truly set it apart. FlashBlade//S can deliver more than twice the performance, density, and power efficiency compared to the first generation of FlashBlade. FlashBlade//S is available in two models: the S200, built for ultimate efficiency, and the S500, built for extreme performance.

And, to help enterprises meet new environmental impact and sustainability goals, FlashBlade//S produces the most efficient results on the key performance, space, and power metrics, such as usable capacity per watt, throughput per watt, and usable capacity per rack unit.
Inside ‘The Box’
FlashBlade//S includes the next generation of every hardware component, from flash and CPU to networking and more. The disaggregation of storage and performance, the modularity of the architecture enabling customers to leverage the latest innovations in the industry, and co-innovation of hardware and software is unique to Pure Storage.
DirectFlash®—Pure’s pioneering flash management engine—comes to FlashBlade in full force. It’s the first time all of Pure’s hardware platforms share a common set of DirectFlash Modules. In many cases, these components of FlashBlade//S will be future-proof and able to be independently and non-disruptively upgraded, thanks to the modularity of the architecture.
But it’s not just hardware; FlashBlade//S leverages Purity//FB, our scale-out storage software OS. Purity//FB 4.0 continues to provide all of the rich data services protocols that our customers have come to love and expect from the original FlashBlade platform, now supercharged for the next generation of modern data applications. Purity//FB 4.0 unlocks the power of the new FlashBlade//S, enabling unmatched levels of density, performance, and exabyte-level scale.
Bigger Bets, Better Science
When FlashBlade launched a little more than five years ago, it was considered way ahead of its time. We’d made some bold bets—the growing scale and performance demands of unstructured data, the rise of fast object, and the ubiquity of artificial intelligence (AI), to name a few.
The success of FlashBlade has only validated those bets.
Now, FlashBlade//S builds on the capabilities of the first-generation FlashBlade and goes even further. It’s a platform for exabyte scale that will support the needs of modern data and applications for the next decade and beyond. It merges two distinct, unstructured, scale-out storage worlds which haven’t co-existed until now: disk-based, capacity-oriented storage and flash-based performance storage.
This updated architecture disaggregates storage and compute to deliver a highly configurable, customizable file and object storage platform to target any workload profile. FlashBlade//S handles it all—from workloads that require the highest levels of flash performance to capacity-optimized disk-based ones that call for hybrid density and efficiency. Our all-QLC flash architecture avoids the need for expensive caching solutions and storage class memory (SCM).
FlashBlade//S also delivers:
- A metadata structure that can scale to support hundreds of billions of objects in a single system.
- Improved performance, resiliency, and system efficiency by eliminating the overhead associated with managing off-the-shelf solid-state drives (SSDs).
- A software architecture designed to leverage the hardware’s innovation well into the future.
- Integrated networking capabilities that eliminate the complexities associated with unstructured data.
A Storage System That Improves over Time with Pure Evergreen
A typical storage platform degrades over time, forcing customers through disruptive migrations and upgrades. FlashBlade//S is different. This storage system can evolve with our customers and get better over time. We’ve already proven this, with 97% of the FlashArray devices purchased six years ago still in service today.
Combined with our expanded Pure Evergreen™ portfolio, it’s unlike anything in the file and object storage industry:
- Evergreen//Forever (formerly known as Evergreen Gold): Provides all-inclusive software, blade upgrades, trade-in credit on model upgrades, capacity consolidation, non-disruptive upgrades, flat and fair renewals, and more.
- Evergreen//One (formerly known as Pure as-a-Service™): Offers flexible consumption choices.
- Evergreen//Flex: Is the latest addition to the portfolio.
Powerful Next-gen AI Solutions
FlashBlade//S powers some of the most advanced workloads so customers can achieve unmatched outcomes with modern analytics, rapid restore, ransomware recovery, high-performance and technical computing, and many more. One area that FlashBlade//S takes to the next level is AI and machine learning (ML) with our AIRI® solution.
Since its introduction, AIRI has established itself as the industry-leading solution trusted by hundreds of customers at different stages of their AI journeys. AIRI//S is our latest AI-ready infrastructure, which leverages FlashBlade//S, NVIDIA DGX systems, and NVIDIA networking. It’s fast and simple for enterprises to deploy a pre-validated AI platform and scale it into a general-purpose AI infrastructure that supports multiple, disparate data science efforts.
FlashBlade//S is the platform built to accelerate the pace of future innovation. It enables us to bring even denser, more power-efficient, and performant systems to market faster to address the growing dynamic data and ESG requirements of enterprises.
![]()



