アジア太平洋データサイエンス部門 ソリューションアーキテクトの蒋 逸峰(Yifeng Jiang)です。ビッグデータや AI の活用を、シンプルな使い勝手でパワフルに支える FlashBlade™ について、数回に分けてご紹介していきたいと思います。
FlashBlade をデータハブに
データハブは、構造化、半構造化、非構造化など多様なタイプのデータの中枢を担います。少ないノードの小さな Apache Nifi、Apache Spark クラスタでデータハブを構築して、複数のソースからデータを取り込み、リアルタイム分析を行うためのビッグデータパイプラインを作成します。
TensorFlow や GPU のような深層学習・AI ソリューションを利用することもあるでしょう。異なるタイプのワークロードを処理するためには、クラスタのサイズを変更する必要があります。また、ビジネスニーズに対応する新たなアプリケーションを試すことも必要です。したがって、変更をより迅速に、シンプルに行える環境を構築する機敏性が重要になります。データストレージをデータ処理リソースから分離して、コンピューティングとストレージを別々に管理し、データ量増大にあわせて効率よく拡張できる共有型ストレージシステムに統合することが理想的です。
このブログシリーズでは、ピュア・ストレージの FlashBlade をデータハブとして使用した場合の具体例を用いて、ストレージとコンピューティングの分離、分析ツールとの容易な統合、ベストプラクティスについて解説します。 Apache Nifi、Apache Spark、TensorFlow と FlashBlade の組み合わせにより、シンプルかつ柔軟な実装で、高いパフォーマンスと可用性をもつ次世代データ分析・AI のソリューションを実現します。
FlashBlade の概要
ピュア・ストレージの革新的なスケールアウト型オールフラッシュストレージシステムである FlashBlade は、エンタープライズデータ分析におけるデータハブが抱える課題に簡単に対処します。FlashBlade は、データの保存とアクセスをリアルタイムに行うことで、データ分析を効率化します。最新の分析アプリケーションを高速化するとともに、IOPS、スループット、遅延率、容量効率などのさまざまな面において、最高のパフォーマンスを引き出すように設計されています。
また、FlashBlade は、パワーとともにシンプルさも追求しています。グローバルなフラッシュ管理を可能にする DirectFlash 技術、ならびに、あらゆるレイヤーに対応する弾性スケールアウト型のストレージサービスを提供しています。
ビッグデータ分析には、従来、Hadoop HDFS をはじめとしたハードディスクの DAS(Direct Attached Storage)を使用した分散ストレージシステムが利用されていました。しかし、リアルタイム分析や AI を中心とする次世代分析アプリケーションでは、DAS を共有型ストレージデータハブに置き換えることがトレンドになっています。
これを実現するために、FlashBlade は S3 と NFS プロトコルをサポートしています。
- Apache Spark や Apache Hive といったアプリケーションのビッグデータを格納するため、S3 名前空間とバケットを提供
- Apache Solr のようなリアルタイム処理や、TensorFlow のような AI フレームワークのために、NFS ボリュームを提供
愛犬家のための画像認識 AI を作ってみよう!
愛犬家のための AI を作ってみましょう。犬に関するデータを収集し、リアルタイム分析、ディープ分析を行います。
大まかな手順は次のようになります。
- Twitter API を介して愛犬家のユーザー情報や犬関連のツイートを取得して、ダッシュボードにリアルタイムに表示する
- 全てのデータを保存し、蓄積されたビッグデータをより詳細に分析
- 写真付きのツイートの場合は、その写真もダウンロード
- AI モデルをトレーニングしたうえで、ダウンロードした写真に犬が写っているかどうか、写真のどこに写っているかを AI に検出させる
下の図は、このアプリケーションを FlashBlade 上に実装する場合のアーキテクチャの例です。

図 1:FlashBlade で AI –アーキテクチャの例
ここでのポイント:
- 分析と AI のパイプラインが、シンプルに FlashBlade に統合
- リアルタイム、ビッグデータ、更に AI モデルを含め、全てのデータが FlashBlade に集約
- ストレージとコンピューティングリソースは、必要に応じてそれぞれ独立したスケーリングが可能
データサイロはなく、FlashBlade はまさにデータハブとなっています。
なぜ FlashBlade が必要なのか?
次世代データ分析や AI に、なぜ FlashBlade が必要なのだろうかと思われるかもしれません。従来のストレージでも、なんとか対応できるかもしれません。しかし、ビジネスニーズの変化に対してより迅速に、シンプルに対応するためには、それは最適な方法と言えるのでしょうか。
上述のアプリケーションを、従来のストレージと方法で実装する場合のアーキテクチャは、以下のようになります。
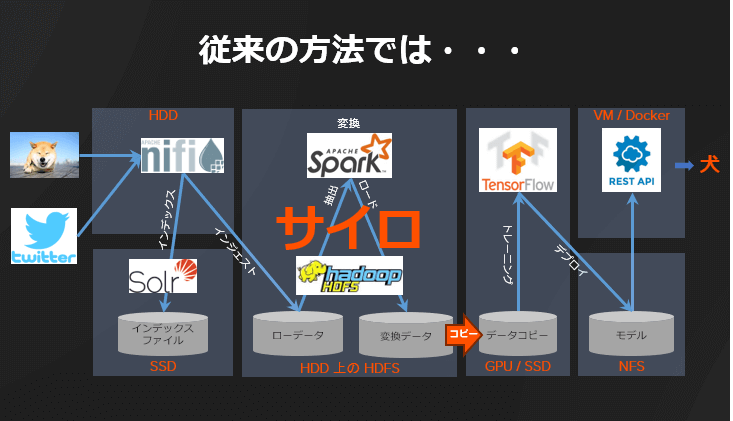
図 2:従来の方法でアプリケーションを実装
データの所在に注目してください。HDD、SSD、Hadoop HDFS、NFS があちこちに散在しています。更に異なるストレージ間のデータコピーも発生しています。これはまさにデータサイロです。従来の方法では、サイロ化されたストレージとシステム、それに伴う大量のハードウェアとソフトウェアを管理するといった複雑さが生じてしまいます。
本来は、管理の複雑さに煩わされるのではなく、ビジネス価値を生み出すデータ分析や AI アプリケーションそのものに時間とリソースをかけるべきです。その課題を解決するのが FlashBlade です。FlasBlade を使った綺麗なデータハブを構築し、ビッグデータ分析と AI をシンプルにすることをお薦めします。
次回は、実際のデータを使ったリアルタイム分析とビッグデータ分析の具体的な構築方法について解説します。お楽しみに!