

4차 산업혁명
4차 산업혁명으로 인한 변화가 AI(인공지능) 및 머신러닝 기술 발전에 힘입어 다양한 산업분야와 실생활 속으로 빠르게 확대되고 있습니다. 1차 산업혁명을 거치며 농경사회가 산업사회로 바뀌었고, 2차 산업혁명으로 산업사회는 대량생산의 시대에 접어 들었으며, 이어진 3차 산업혁명에서는 디지털 시대로의 전환이 이루어졌습니다. 지능형 기계 및 서비스를 중심으로 한 4차 산업혁명은 여러 기술들의 통합으로 새로운 비즈니스와 산업을 주도하며 다시 한번 사회를 대대적으로 변화시킬 전망입니다.
모든 산업이 데이터 분석을 통한 통찰력으로부터 혜택을 얻고 있습니다.
데이터를 통찰력으로 전환하는 역량이 이제 기업 경쟁력을 가늠하는 척도가 되고 있습니다. 헬스케어 분야를 예로 들면, 미국의 대형 병원 사업자 마요 클리닉(Mayo Clinic)의 신경 방사선의들은 MRI 스캔을 통해 질병과 관련된 특정한 유전자 패턴을 알아내는데 AI를 사용하고 있습니다. 이를 통해 종양 조직 샘플 및 유전자 데이터 채취를 위한 뇌 수술의 필요성을 없애고 있습니다. 소비재 분야에선 아마존이 자율주행차에서 사용되는 센서와 AI 기술을 활용해 계산대가 필요 없는 오프라인 자동화 식료품 매장인 아마존 고(Amazon Go)를 운영하고 있습니다. 농업 분야에선 미국의 스마트 농기계 제공 기업인 블루 리버 테크놀로지(Blue River Technolog)가 AI 엔진을 장착한 레터스봇(LettuceBot)을 개발하고 미국 총 상추 생산량의 10%를 수확하고 있습니다. 이 로봇은 밭에서 상추를 식별하고 실시간으로 수확량을 측정 및 최적화할 수 있습니다.

블루 리버 테크놀로지의 레터스봇은 머신러닝 기술을 적용하여 농약 사용량을
감소시키고 수확량을 극대화합니다.
AI의 3가지 핵심기술은
- 딥러닝,
- 그래픽처리장치(GPU),
- 빅데이터 입니다.
딥러닝
딥러닝은 인간의 뇌를 형상화한 방대한 병렬 신경망에 기반한 새로운 컴퓨팅 모델입니다. 딥러닝은 전문가들이 소프트웨어를 만드는 것이 아니라, 딥러닝 모델 자체가 다양한 예시들을 학습하여 스스로 소프트웨어를 개발하고 향상시킵니다. GPU는 수천 개의 코어로 구성된 최신 프로세서로, 인간 뇌의 병렬적인 특성을 본 딴 알고리즘을 실행하는데 필요한 강력하고도 높은 성능을 제공합니다. 이러한 딥러닝 및 GPU는 AI에 대한 접근방식을 혁신적으로 변화시키고 있습니다.
딥러닝과 데이터 처리능력
업계 전문가들에 따르면, 향후 2년 안에 주요 딥러닝 알고리즘을 실행하는데 요구되는 처리능력은 15배 증가하며, GPU가 제공하는 처리성능은 10배 향상될 것으로 예상됩니다. 이는 AI의 세 번째 중요 기술인 빅데이터와도 연결됩니다. 현재 비정형 데이터의 양이 폭증하고 있는 반면, 이러한 데이터를 보관하고 있는 기존의 스토리지는 수십 년 전에 개발된 프로토콜 및 소프트웨어를 사용하고 있습니다. 딥러닝 및 GPU는 대규모 병렬 처리를 이용하지만, 레거시 스토리지 아키텍처는 직렬 연결 방식에 맞춰 설계됐습니다. 이로 인해 CPU와 레거시 스토리지 간의 성능 격차가 점점 더 벌어지고 있습니다.

2015년 마이크로소프트(Microsoft)의 레스넷(Resnet)과 2017년 구글(Google) NMT간의
딥러닝 학습에 필요한 연산 성능 비교 Tesla M40 피크 FLOPS vs Tesla V100 피크 FLOPS 컴퓨트 비교
자산으로서의 데이터
데이터는 4차 산업혁명 시대 기업들의 비즈니스에 가장 중요한 자산이 되고 있으며, 이에 대규모 데이터를 빠르게 전송 및 분석하도록 지원하는 최신 기술에 대한 수요가 점차 증가하고 있습니다. 하지만 시장에는 아직 수십 년 전에 개발된 시스템이 존재하며, 기업들이 이러한 오래된 시스템으로 최신 데이터를 공유 및 분석한다는 것은 우려할 만한 일입니다. 레거시 스토리지는 기업들의 데이터를 매우 느리게 전송하고 분석하여 기업들이 최신 머신러닝의 성능을 활용하는데 장애요소가 되고 있습니다. 레거시 스토리지의 직렬 방식은 방대한 양의 데이터를 가느다란 빨대와 같은 매우 좁은 연결 통로로 전송하는 것과 같으며, 이로 인해 빅데이터 분석을 통한 인사이트 도출이 불가능해질 수도 있습니다. 지능형 분석을 위한 현대적인 데이터 플랫폼은 기존 스토리지와 다르게 처음부터 재구성되어야 합니다. 4차 산업혁명 시대에 적합한 스토리지 플랫폼은 빅데이터 분석을 위해 앞서 언급한 모든 요소들을 충족시켜야 합니다.
AI를 위한 모든 요구사항을 충족시키는 플래시블레이드(FlashBlade)
플래시블레이드는 세계 최고의 퓨어스토리지 엔지니어들이 AI의 방대한 병렬처리 요구를 충족시킬 목적으로 설계한 혁신적인 스케일-아웃 데이터 플랫폼입니다. 엔지니어들은 페타바이트(PB)급 용량은 물론, 가장 쉬운 구축 및 운영을 제공하면서 레거시 스토리지의 한계를 벗어난 초고속 성능을 갖춘 스토리지 아키텍처를 고안하고자 했습니다. 이를 통해 퓨어스토리지는 딥러닝에 필요한 모든 요소를 충족시키도록 설계됐습니다.
대규모 병렬처리 모델
딥 뉴럴 네트워크(Deep Neural Network)는 하나의 문제를 해결하기 위해 수백에서 수십 억개의 신경 세포들이 상호 연결 될 수 있도록 지원하는 대규모 병렬 처리 모델입니다. 기존의 CPU와 비교해, GPU는 방대한 병렬 프로세서로 수천 개의 컴퓨트 코어가 느슨하게 연결되어 CPU 대비 10배에서 100배 높은 성능을 제공합니다. 플래시블레이드는 높은 가용성과 성능을 동시에 보장하는 단일한 운영체제인 퓨리티(Purity) 소프트웨어로 가동되며, 방대한 병렬 처리가 가능한 플랫폼입니다. 수만 대의 클라이언트에 수십 억 개의 오브젝트 및 파일에 대한 액세스를 동시에 고성능으로 제공합니다.

모든 AI 플랫폼 설계에는 방대한 병렬 처리가 핵심이 되어야 합니다.
최대 75개의 블레이드
15개의 블레이드로 구성된 플래시블레이드의 4U 랙 공간에는 120개 제온(Xeon) D CPU 코어 및 45개 FPGA가 최첨단 엘라스틱 패브릭 모듈(Elastic Fabric Module)에 연결돼 있습니다. 이를 통해 3밀리초 미만의 레이턴시, 초당 17GB의 읽기 성능 및 150만 IOPS를 제공합니다. 또한 플래시블레이드는 최대 75개의 블레이드까지 확장 가능하며, 8PB 용량에서 최대 초당 75GB의 읽기, 초당 25GB의 쓰기 및 750만 IOPS까지 성능을 선형적으로 확장시킬 수 있습니다. 또한 3:1의 데이터 압축 기술을 적용하여 이러한 모든 성능을 ½ 랙에 구현 가능합니다.
75개의 블레이드로 구성된 플래시블레이드를 어떻게 확장시킬 수 있는지, 그리고 사용자 애플리케이션은 이러한 확장성을 어떻게 인식하는지를 잘 보여줍니다. 그러나 실제 데이터센터에서 플래시블레이드는 표준 랙 마운트를 사용해 5개의 섀시에 각 15개 블레이드씩 구현되고 있습니다.

8PB 플래시블레이드
퓨리티
플래시블레이드를 구동하는 엔진은 퓨리티 소프트웨어입니다. 방대한 분산 시스템을 위해 설계된 퓨리티는 효율적으로 확장 가능한 스케일-아웃 아키텍처에 기반하고 있습니다. 플래시블레이드의 데이터는 키-값 스토어 아키텍처로 저장되어 수천 개의 병렬 에이전트를 가능하게 합니다. 각 에이전트는 글로벌 네임스페이스(Global Namespace)를 보유하고 있으며, 대규모 파일 및 오브젝트를 처리할 수 있도록 최적화되어 성능을 대폭 향상시킬 수 있습니다.

플래시블레이드의 퓨리티 운영체제는
현대적인 키-값 페어 아키텍처를 기반으로 진정한스케일-아웃 성능을 제공합니다.
플래시블레이드의 핵심, 병렬성
현대적인 스토리지 시스템에 있어 병렬 아키텍처는 매우 중요한 요입니다. 글로벌 파티션 파일 시스템(GPFS), 러스터(Lustre) 파일 시스템에 및 다른 기존의 고성능컴퓨팅(HPC) 스토리지를 구현하는 작업은 마치 딥러닝 학습을 위해 수백 대의 상용 서버를 구축하는 과정에 비유할 수 있습니다. 이렇게 힘든 과정을 거쳐 구축된 환경은 엔비디아 DGX-1 (NVIDIA® DGX-1)만큼의 고성능을 제공하기도 합니다. 수백 개의 부품과 케이블로 구성된 복잡한 데이터센터 인프라는 시스템 장애가 발생할 가능성이 높으며, 어떠한 데이터 과학자들도 이러한 시스템을 원하지 않을 것입니다.
퓨어스토리지만의 병렬처리 아키텍처
플래시블레이드는 DGX-1과 같이 전례 없는 성능 및 효율성을 제공하며, 하드디스크드라이브(HDD) 5,000개에 달하는 IOPS 성능 및 10개의 랙으로 구성된 스토리지에 준하는 성능을 제공합니다. 다른 공급업체들은 수 많은 상용 솔리드스테이트드라이브(SSD)와 HDD를 사용해 자사의 스토리지를 개조하고 있습니다. 퓨어스토리지는 스케일-아웃 스토리지를 처음으로 개발하진 않았지만 플래시블레이드 출시로 스토리지 확장의 효율성 및 단순성을 획기적으로 향상시켰습니다. 플래시블레이드의 중심엔 퓨어스토리지의 다이렉트플래시(DirectFlash) 기술로 조율되는 원시 낸드 플래시들이 다수 존재합니다. 모든 플래시는 퓨어스토리지만의 방대한 병렬처리 아키텍처 상의 하드웨어 및 소프트웨어와 함께 작동합니다. 또한, 이러한 혁신적인 아키텍처를 통해 현대적인 분석 작업의 처리를 가속화합니다.
합리적인 비용의 데이터 분석
테슬라 모델 S(Tesla® Model S)는 전기를 사용할 목적으로 특별히 제작된 차량입니다. 페라리 812(Ferrari® 812)는 초고속 주행을 목적으로 제작됐습니다. 이러한 전기차 및 고속 주행 차량들과 같이 시스템이 특정 사용 목적을 위해 구축된 경우, 놀라운 결과를 낼 수 있습니다. 플래시블레이드는 딥러닝 또는 하둡(Hadoop)과 같은 현대의 데이터 분석 워크로드를 지원하기 위해 특별히 설계됐습니다. 선도적인 정보 서비스 및 시장 데이터 분석 기업들은 과거에 20개 랙으로 구성된 하드디스크 환경에서 워크로드를 처리했습니다. 하지만 이제 4U 크기의 플래시블레이드 한 대로 모든 랙을 대체하여 전력, 냉각, 상면 공간, 가동 시간 및 스토리지 관리 비용을 획기적으로 절감시킬 수 있게 됐습니다. 또한, 플래시블레이드는 모든 규모의 기업들이 보다 합리적인 비용으로 데이터 분석을 수행하고 비즈니스에 AI를 활용할 수 있도록 지원합니다.
 퓨어스토리지 고객은 랙 20개 규모의 기계식 디스크를
퓨어스토리지 고객은 랙 20개 규모의 기계식 디스크를
매우 작은 4U 크기의 단일한 플래시블레이드로 교체했습니다.
현대적인 스토리지의 필요성
사용자들은 보통 엔비디아 DGX-1과 같은 강력한 성능을 제공하는 슈퍼컴퓨터로 자사의 AI 여정을 시작하며, 보통 모든 데이터를 로컬 SSD스토리지에 저장합니다. 이러한 구성은 다양한 프레임워크와 네트워크를 테스트하고 딥러닝을 실험하는 사용자들에게 적합합니다. 그러나 보다 많은 양의 데이터를 기반으로 했을 때 딥러닝의 무한한 잠재력을 보다 잘 실현할 수 있습니다. 뿐만 아니라 딥러닝에 기반한 데이터 세트의 분석은 컴퓨터 용량에 의해 제한되지 않아야 합니다. 스탠포드 대학의 앤드류 응(Andrew Ng) 교수가 진행한 연구 결과에 따르면, 딥러닝 모델의 정확성 및 성능은 방대한 규모의 학습 데이터 세트를 통해 지속적으로 향상될 수 있다는 점에서 다른 학습 알고리즘과 차이가 있는 것으로 조사됐습니다.

방대한 규모의 데이터가 기반이 되어야 딥러닝의 무한한 가능성을 실현 할 수 있습니다.
(출처: 앤드류 응 교수)
넓은 데이터 전송 대역폭
100TB의 데이터 세트로 학습한 모델이 1TB의 데이터 세트로 학습한 모델보다 훨씬 높은 정확도를 보입니다. 차세대 스토리지는 파일의 용량 크기에 관계 없이 랜덤 액세스 패턴을 감안해 GPU 시스템에 매우 넓은 데이터 전송 대역폭을 제공해야 합니다. 여러 처리 장치들에 걸쳐 분산된 스토리지는 방대한 데이터 세트 처리에 적합하지 않습니다.
세계에서 가장 강력한 AI 슈퍼컴퓨터 지원
AI를 도입해 활용하고자 하는 고객들은 플래시블레이드에 많은 관심을 보이고 있습니다. 퓨어스토리지의 주요 고객인 업계 선두적인 글로벌 웹 스케일 기업을 예로 들 수 있습니다. 이 기업은 엔비디아 DGX-1 및 플래시블레이드 시스템을 기반으로 세계에서 가장 빠른 시스템으로 꼽히는 대규모 슈퍼컴퓨터를 구축했습니다. 이 슈퍼컴퓨터 시스템은 플래시블레이드부터 GPU로 구성된 딥러닝 트레이닝 프로세서까지 매우 빠른 데이터 전달을 통해 딥러닝 학습을 가속화시켜 줍니다.
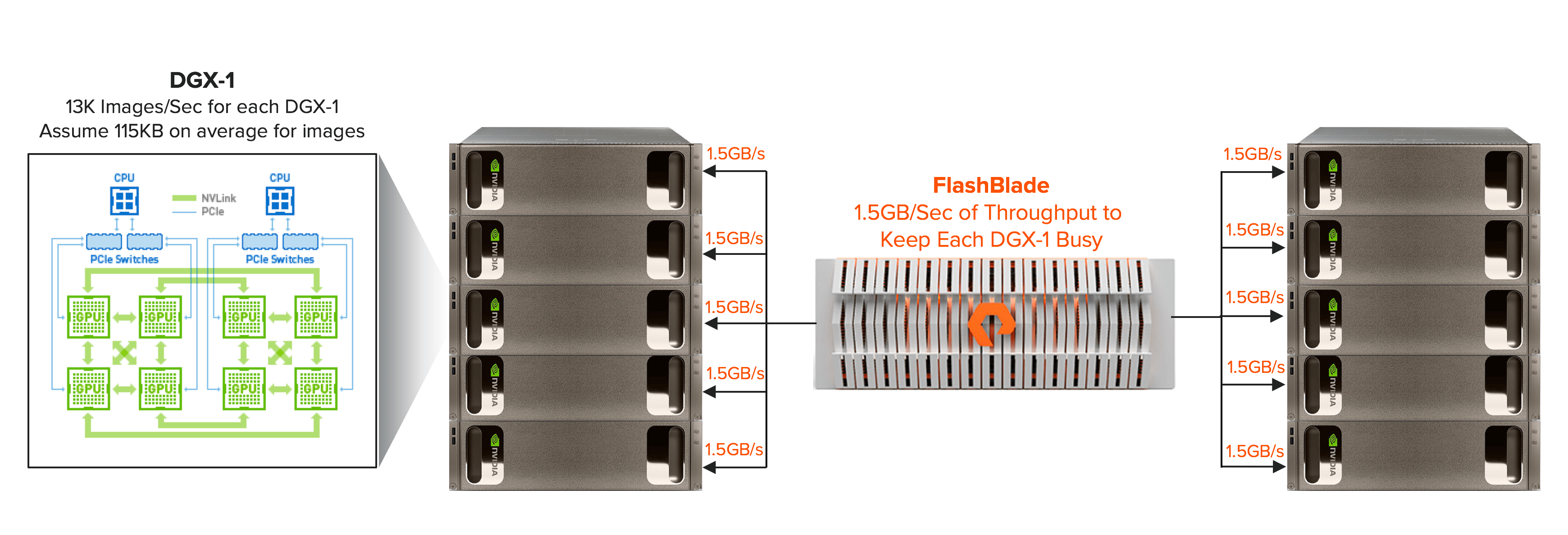
플래시블레이드가 효율적인 딥러닝을 위해
DGX-1 와 같은 GPU 시스템에 데이터를 전송하는 구조
균형잡힌 솔루션
딥러닝 트레이닝 클러스터 구현 시 전체 시스템을 고려하여 균형 잡힌 솔루션을 도입하는 것이 중요합니다. 알렉스넷(AlexNet)을 사용하여 마이크로소프트의 코그니티브 툴킷(Cognitive Toolkit; CNTK) 프레임워크를 구동하는 DGX-1 시스템의 예를 살펴보면, 엔비디아는 DGX-1가 초당 13,000개의 이미지를 처리할 수 있도록 딥러닝 모델을 학습시킬 수 있다고 발표한 바 있습니다. 평균 이미지 사이즈를 115KB라고 가정했을 때 10개의 DGX-1은 지속적인 학습을 위해 초당 15GB의 데이터 처리 성능을 제공해야 합니다. 또한, 작은 용량의 파일에 대한 읽기 성능 및 IOPS도 문제 해결 속도에 중대한 영향을 미칩니다. 스토리지 시스템의 처리량이 데이터 처리를 위해 필요한 성능의 절반밖에 제공해 주지 못할 경우 데이터 과학자는 작업이 완료될 때까지 두 배의 시간을 기다려야 합니다. 이는 데이터 과학자들이 해당 딥러닝 과제를 해결할 수 있느냐 없느냐를 판가름할 수도 있습니다. 만약 딥러닝을 통해 주요 과제를 해결하지 못한다면 인사이트 확보를 통해 잠재적인 혁신을 이룰 수 있는 기회를 놓칠 수도 있습니다.
마치며
AI의 혜택을 극대화하기 위해 필요한 기술 요소는 딥러닝, GPU 및 빅데이터입니다. GPU와 빅데이터는 각각 딥러닝 모델 향상에 핵심적인 처리능력 및 다양한 대규모 데이터 세트를 지원합니다. 플래시블레이드는 딥러닝 워크로드를 위한 이상적인 데이터 플랫폼입니다. 현대 딥러닝 신경망 또는 GPU로 가속되는 시스템들과 마찬가지로, 플래시블레이드는 방대한 병렬 아키텍처로 이루어져 확장이 가능하고, 사용이 매우 간단하며, 속도가 빠릅니다. 또한 고도의 모듈형 설계를 기반으로 학습 데이터 세트가 증가함에 따라 용량 및 성능을 동시에 확장시킬 수 있습니다.
이제 AI를 활용하고자 하는 기업들은 플래시블레이드를 통해 새로운 가능성을 광범위하게 모색해야할 때입니다.



