

퓨어스토리지는 다이렉트플래시 패브릭(DirectFlash™ Fabric)을 소개하게 되어 매우 기쁘게 생각합니다. 다이렉트플래시 패브릭(DirectFlash™ Fabric)은 플래시어레이(FlashArray) 내에서만 구동되던 다이렉트플래시(DirectFlash™)의 제품군을 RoCEv2 라고도 불리는 컨버지드 이더넷 기반 RDMA(이하 RoCE)을 통하여 패브릭 환경으로 확장합니다. 다이렉트플래시 패브릭(DirectFlash™ Fabric)은 애플리케이션이 플레시어레이(FlashArray)에 접근하는 방식을 혁신적으로 바꾸며, 로컬 디스크를 사용하는 스토리지 환경(이하 DAS)에서 컴퓨팅과 스토리지의 분리화(disaggregation)에 필요한 부분을 충족시켜줍니다.
다이렉트플래시 패브릭(DirectFlash™ Fabric)은2019년 1월 16일 무중단 펌웨어 업그레이드 및 스토리지 컨트롤러의 RDMA 지원 NIC(Network Interface Card)설치와 함께 공식 출시되었습니다.
더 자세한 사항은 아래를 참고하세요.

결과가 생각의 속도만큼 빨라야 하는 이유
세상이 디지털 및 모바일화 됨에 따라 사람들의 기대치는 매우 높아졌으며, 더더욱 높아지고 있습니다. 이제 “생각의 속도만큼 빠른 결과”를 내기를 바랍니다. 물론 과거에는 그렇지 못했습니다. 과거의 애플리케이션은 순차적인 성격을 띠었습니다. 데이터를 입력한 뒤 처리가 되고 보고되는 방식이었습니다. 하지만 오늘날의 애플리케이션은 병렬식이며, 머신러닝, 인공지능을 사용합니다. 즉, 병렬식 인풋으로 애플리케이션 데이터가 처리되며(구글 검색과 같은 방식) 실시간으로 결과를 냅니다. 이러한 애플리케이션의 변화와 함께 인프라 또한 동시성과 병렬성을 갖추고 매우 낮은 지연 속도와 높은 성능을 갖춰야 하는 상황이 되었습니다. 스토리지의 관점에서 보면, 1990년대에 만들어진 소형 컴퓨터 시스템 인터페이스(이하 SCSI) 디스크에서 플래시 기반의 NVMe로 넘어가는 것을 의미합니다. 이러한 변화는 데이터의 실시간 접근을 위하여 데이터와 컴퓨팅 환경, 그리고 애플리케이션과의 거리를 더욱 좁혔습니다. 하지만 유감스럽게도 지금 제공되는 대부분의 스토리지 어레이는 디스크 기술에 기반한 SCSI 솔루션입니다. 그 결과 기업들의 실시간 데이터 접근을 지원하는 것이 매우 어렵습니다.
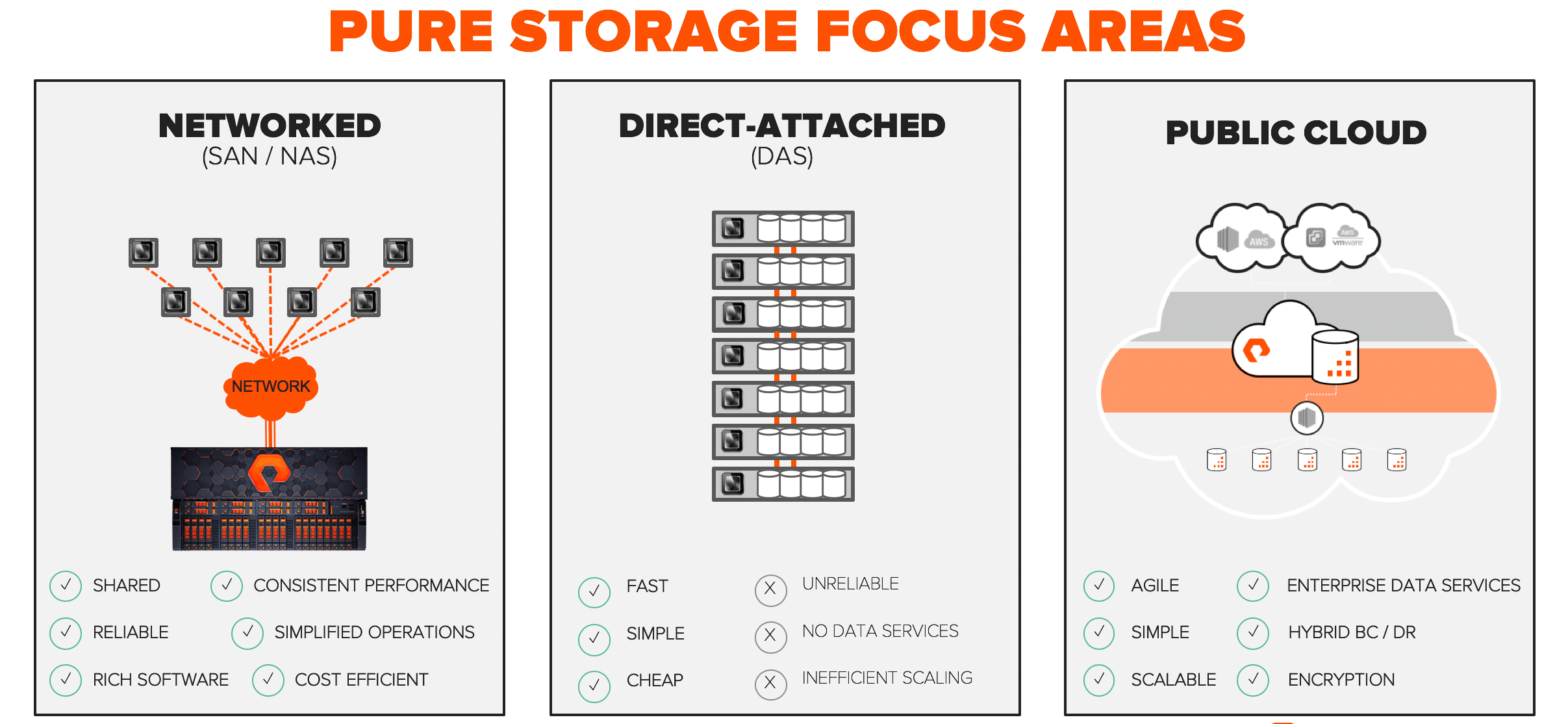
더 큰 문제는 이러한 데이터를 처리하는 애플리케이션은 애플리케이션 별 특성이 서로 달라서 사일로가 발생한다는 것입니다. 또한 이로 인해 애플리케이션은 각각 자신에게 맞는 스토리지 아키텍처가 필요하게 되었습니다. 퓨어스토리지는 플래시어레이(FlashArray)와 플래시블레이드(FlashBlade)를 통하여 처음부터 디스크가 아닌 플래시를 기반으로 제품을 설계하여 이러한 네트워크 스토리지(SAN 및 NAS)의 문제점을 완화하는 것에 집중하였습니다. 저희는 최근 퍼블릭 클라우드를 강화하기 위한 새로운 클라우드 데이터 서비스인 클라우드 블록 스토어(Cloud Block Store)를 출시하였습니다. 하지만 본 서비스는 DAS에 포커스를 크게 두고 있지 않으며, DAS는 많은 분석을 수행하고 동시성이 높은 요즘 애플리케이션을 구동하기 위해서 필요한 부분입니다.
문제점이 많은 DAS, 하이퍼스케일러의 분리화 이동

DAS는 일반적으로 웹스케일과 비슷한 방식으로 표준화된 서버에 설치됩니다. 이러한 표준화로 설치는 쉬워지지만, 안타깝게도 애플리케이션마다 컴퓨팅과 스토리지의 공간/크기가 다르기 때문에 사용되지 못하고 낭비되는 용량 및 CPU가 발생합니다. 스탠포드 대학과 페이스북은 2015년 페이스북의 인프라를 기반으로 플래시 스토리지 분리화 연구를 발표했습니다. 본 연구는 플래시 용량의 활용, 읽기 처리량 및 페이스북 인프라 전반의 CPU에 대하여 살펴본 뒤 스토리지의 효율성이 낮다는 결론을 내렸습니다. DAS 아키텍처에 스냅샷, 복제, 글로벌 중복제거, 씬 프로비저닝과 같은 데이터 서비스가 존재하지 않아서 용량 및 운영의 비효율성이 더욱 증가하였습니다.
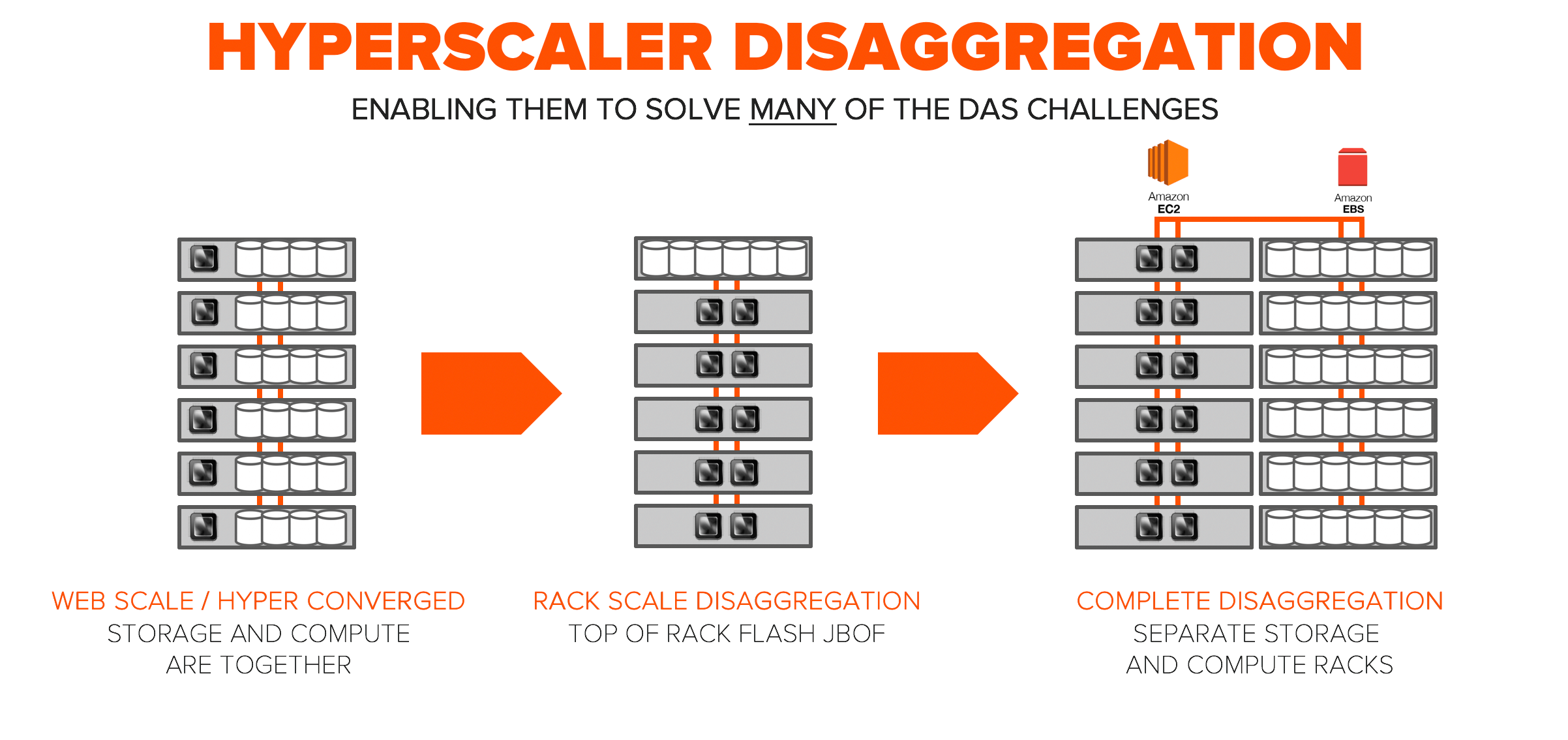
하이퍼스케일에서 효율은 필수입니다. 초반에는 “웹스케일”이 있었습니다. 심플하고 쉽게 확장할 수 있는 방법이었죠. 또한 하이퍼 컨버지드는 현재 변화의 초기 단계에 있습니다. 앞서 스탠포드 대학의 플래시 스토리지 분리화 연구에서 보았듯이, 이러한 아키텍처 종류는 미성숙하며, 확장에 있어서 높은 비효율성을 보입니다. 컴퓨팅과 스토리지의 독립적인 확장을 지원하기 위해서 많은 하이퍼스케일 환경은 “랙스케일 분리화(rack-scale disaggregation)”를 택했습니다. 이를 통해 표준 랙을 사용하지 않고 효율성을 높일 수 있었습니다. 완전한 분리화는 스토리지와 컴퓨팅을 분리된 랙에 독립적으로 두고, 최적화된 프로토콜을 통해 접근하며, 하이퍼스케일 기반의 최고의 효율성을 자랑합니다.
이제 컴퓨팅과 스토리지의 분리화 자체는 당연한 것으로 받아들일 수 있겠지만, 공유 스토리지로 나아가기 위하여 다음과 같은 장애물이 해결되어야 했습니다.
- DAS와 같은 성능 결과를 제공해야 합니다. (300 마이크로초 미만)
- 대부분의 하이퍼스케일 솔루션에서 파이버 채널 사용은 선택 가능한 옵션이 아니기 때문에, 빠른 이더넷을 통해 낮은 레이턴시를 제공해야 합니다.
애플리케이션 접근을 최적화하는 다이렉트플래시 패브릭(DIRECT FLASH FABRIC)
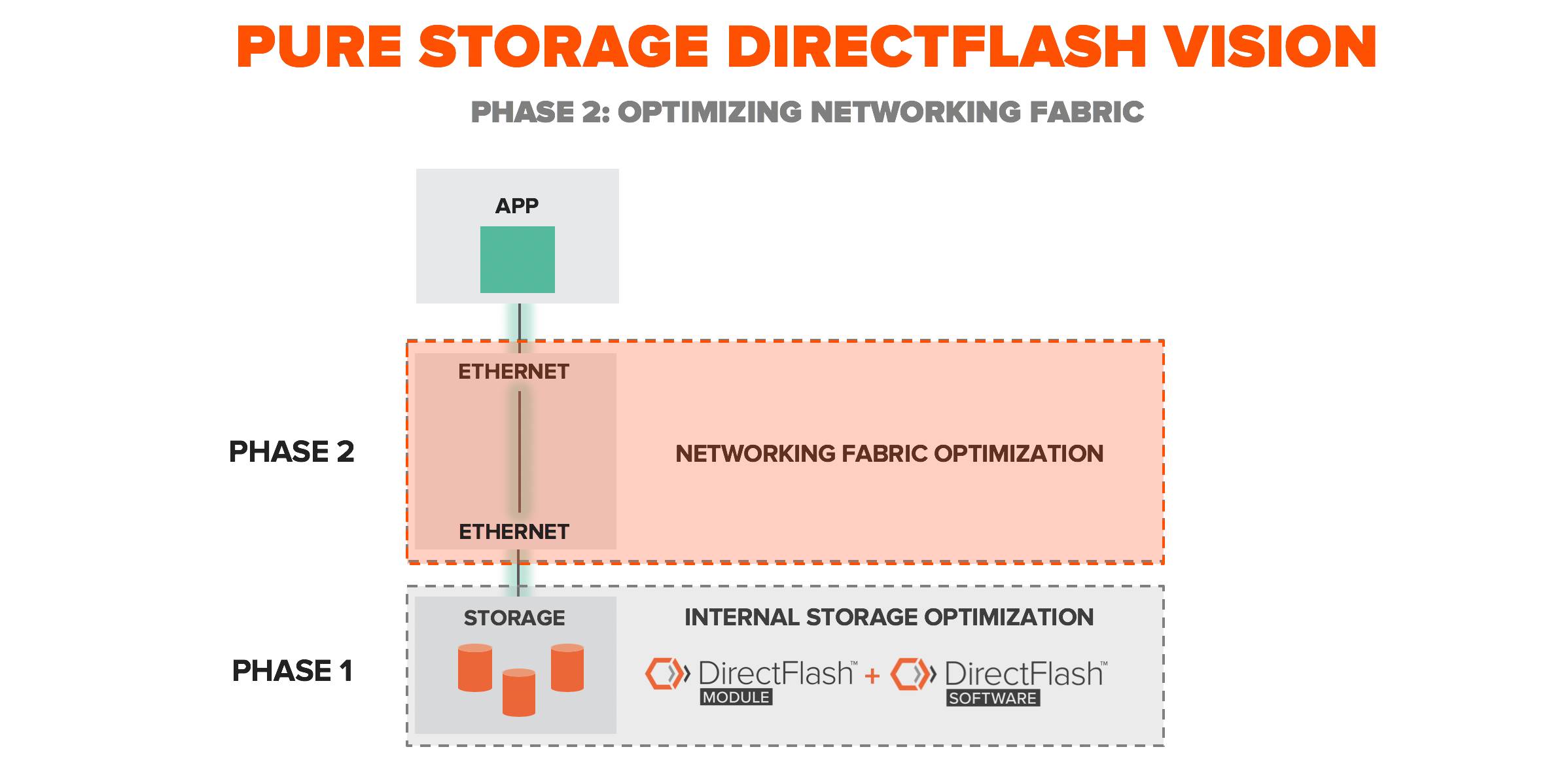
엔터프라이즈 수준의 데이터 서비스에서 지연 시간을 큰 폭으로 낮추는 것은 쉬운 일이 아닙니다. 그래서 퓨어는 가장 큰 병목현상을 보이던 기존의 구형 프로토콜을 전부 없애는 것을 비전으로 삼았습니다. 저희는 이를 구현하기 위하여 다이렉트플래시 모듈(DirectFlash™ Module, 커스텀 NVMe 기반 SSD)과 다이렉트플래시 소프트웨어(DirectFlash Software, 소프트웨어 정의 NAND와 직접적인 인터페이스를 수행하는 방식) 두 가지의 혁신을 개발하였습니다. 이를 통하여 어레이의 성능이 향상되고 애플리케이션의 운영에 크게 도움이 되었습니다. 다이렉트플래시(DirectFlash)에 대하여 더 자세한 내용은 “다이렉트플래시– 소프트웨어와 플래시의 직접적인 인터페이스를 가능하게 하다”와 “다이렉트플래시 심층분석”을 참고 부탁드립니다. 이제 저희와 애플리케이션 사이에서 해결해야 할 유일한 부분은 네트워킹 패브릭입니다.

퓨어스토리지는 다이렉트플래시 패브릭(DirectFlash™ Fabric)을 소개하게 되어 매우 기쁩니다. 다이렉트플래시 패브릭(DirectFlash™ Fabric)은 어레이 내에서 구동되던 다이렉트플래시의 제품군을 RoCEv2 라고도 불리는 RoCE를 통하여 패브릭까지 확장합니다. 이를 통해 매우 낮은 지연 속도(200~300 마이크로초 액세스) 및 엔드-투-엔드 NVMe 등 플래시 분리화에 필요한 부분이 해결되고, 애플리케이션이 플래시어레이에 접속하는 방식을 혁신적으로 바꿀 수 있습니다. 다이렉트플래시 패브릭(DirectFlash™ Fabric)은 2019년 1월 16일 펌웨어 업그레이드 및 스토리지 컨트롤러에 RDMA 지원 NIC의 설치와 함께 공식 출시되었습니다. 이 모든 것이 기존 플래시어레이의 성능에 영향을 주지 않는 무중단 상태로 혹은 유지보수 모드로의 전환 없이 진행됩니다. iSCSI와 비교하여 지연 속도는 최대 50% 개선되었으며, 기업 애플리케이션을 위한 가장 빠른 패브릭으로 알려져 있는 파이버 채널보다 최대 20% 빠릅니다. RMDA 오프로드를 통해 25%의 CPU 오프로드를 확인하였으며, 이를 통해 애플리케이션의 구동에 CPU가 더 많이 할당되어 더 많은 업무 처리가 가능해졌습니다.

다이렉트플래시 패브릭(DirectFlash™ Fabric)은 계속되는 퓨어의 선두적인 NVMe 혁신를 보여줍니다. 2015년에는 NVRAM 디바이스가 퓨어의 Stateless 아키텍처를 지원하며 퓨어의 플랫폼에서 NVMe의 기반을 시장 최초로 다졌습니다. 또한 2017년에는 100% NVMe 올플래시 어레이를 가장 먼저 선보였습니다. 2018년에는 확장 쉘프인 NVMe-oF을 가장 먼저 내놓았을 뿐 아니라, 100% NVMe 제품군을 비NVMe 제품라인과 동일한 가격으로 내놓았습니다. 이제 저희는 RoCE를 통해 NVMe-oF를 갖춘 첫번째 기업 수준의 어레이를 제공하게 되었습니다.

NVMe-oF을 통한 네트워크 패브릭의 최적화는 진화의 산물입니다. 이제 리눅스는 NVMe-oF을 위해 승인된 안정적인 드라이버를 갖추고 있습니다. 몽고DB, 카산드라, 마리아DB, 하둡 및 스플렁크와 같은 클라우드 네이티브 애플리케이션은 다음과 같은 특징이 있습니다.
- 전통적으로 리눅스에 구축
- 대부분 DAS 사용
- 빠른 이더넷 네트워킹에서 구동
- 스케일에 따른 비효율성 다수
이러한 애플리케이션은 NVMe-oF의 사용을 도입하는 좋은 초기 후보가 될 수 있으며, 그렇기 때문에 퓨어는 우선적으로 RoCE에 집중하기로 하였습니다. 현재, 이 부분이 바로 고객이 가장 큰 혜택을 누릴 수 있으며 시장이 준비된 곳입니다. 기업의 애플리케이션 환경과 OS에 대한 지원이 완전히 구현되면 다음 단계는 파이버 채널입니다. 안타깝게도 지금은 최소한의 파이버 채널 지원만 하고 있기 때문에 현재로서는 의미 있는 서비스가 아닙니다. 퓨어는 2019년 말에 Fiber Channel over NVMe(FC-NVMe)를 선보이고자 합니다. NVMe over TCP(NVMe/TCP)는 가장 마지막 단계이며 2020년에는 모든 사용자를 대상으로 NVMe를 지원할 수 있을 것입니다.
애플리케이션과 운영에 도움이 되는 다이렉트플래시 패브릭(DIRECT FLASH FABRIC)
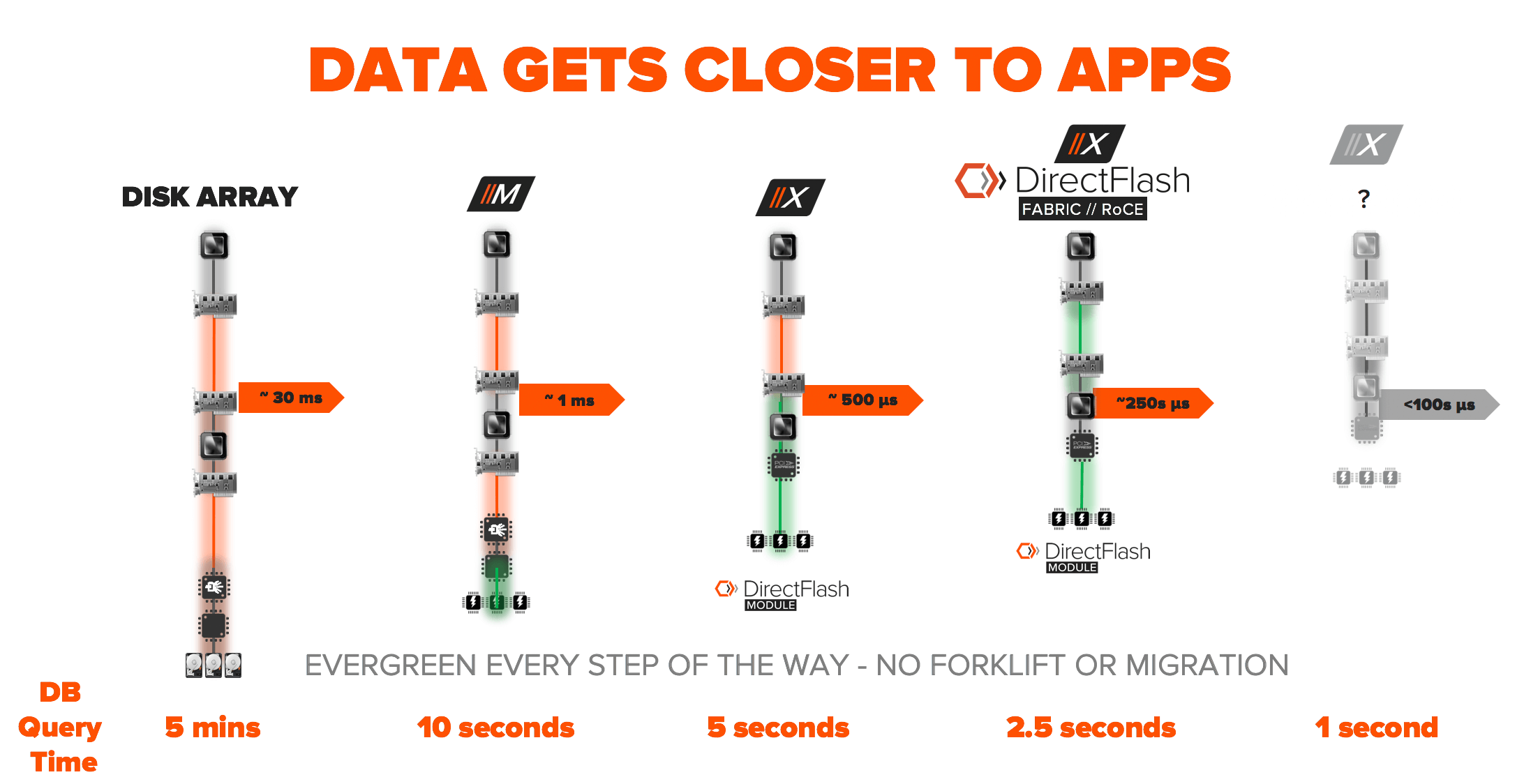
생각의 속도로 결과를 내는 것의 핵심은 데이터와 애플리케이션의 거리를 좁히는 것입니다. 퓨어의 기술 혁명을 살펴보면 구형 SCSI식의 접근을 완전히 없애고 차세대 NVMe기술로 전 스택을 최적화하였습니다. 데이터베이스 기반으로 백엔드 애플리케이션이 구동될 때의 쿼리 응답 속도의 변화를 살펴보겠습니다.
- 디스크 어레이= 5분 (지연속도 30ms)
- 올플래시 어레이= 10초 (지연속도 1ms)
- 내부의 다이렉트플래시 모듈/소프트웨어= 5초 (지연속도 500 μs)
- 외부의 다이렉트플래시 패브릭= 2.5초 (지연속도 250 μs)
이 속도가 끝이 아닙니다. 내년에 완전한 기업 수준의 데이터 서비스가 지속 운영되면 응답 속도를 1초(실시간)로 줄일 수 있을 것으로 예상합니다. 여기서 가장 좋은 점은 바로 고객이 전면적인 업그레이드나 마이그레이션 없이 이러한 변화의 혜택을 누릴 수 있다는 것입니다. 에버그린(Evergreen) 스토리지 모델 사용 고객은 펌웨어 업그레이드나 컨트롤러 교체(추가되는 비용만 지불)와 함께 위와 같은 새로운 기능도 누릴 수 있습니다.

클라우드 네이티브 애플리케이션이 엔드투엔드 NVMe-oF를 사용하게 되면 심지어 SAS DAS 솔루션과 비교하여도 매우 높은 수준으로 퍼포먼스를 향상시킬 수 있습니다. 퓨어의 시험 결과, 다음과 같은 성능의 향상이 예상됩니다.
- 몽고DB, 시간 당 최대 50% 향상
- 카산드라, 지연속도 최대 30%, 시간 당 운영 최대 30% 향상
- 마리아DB, 최고 거래량 최대 33% 향상
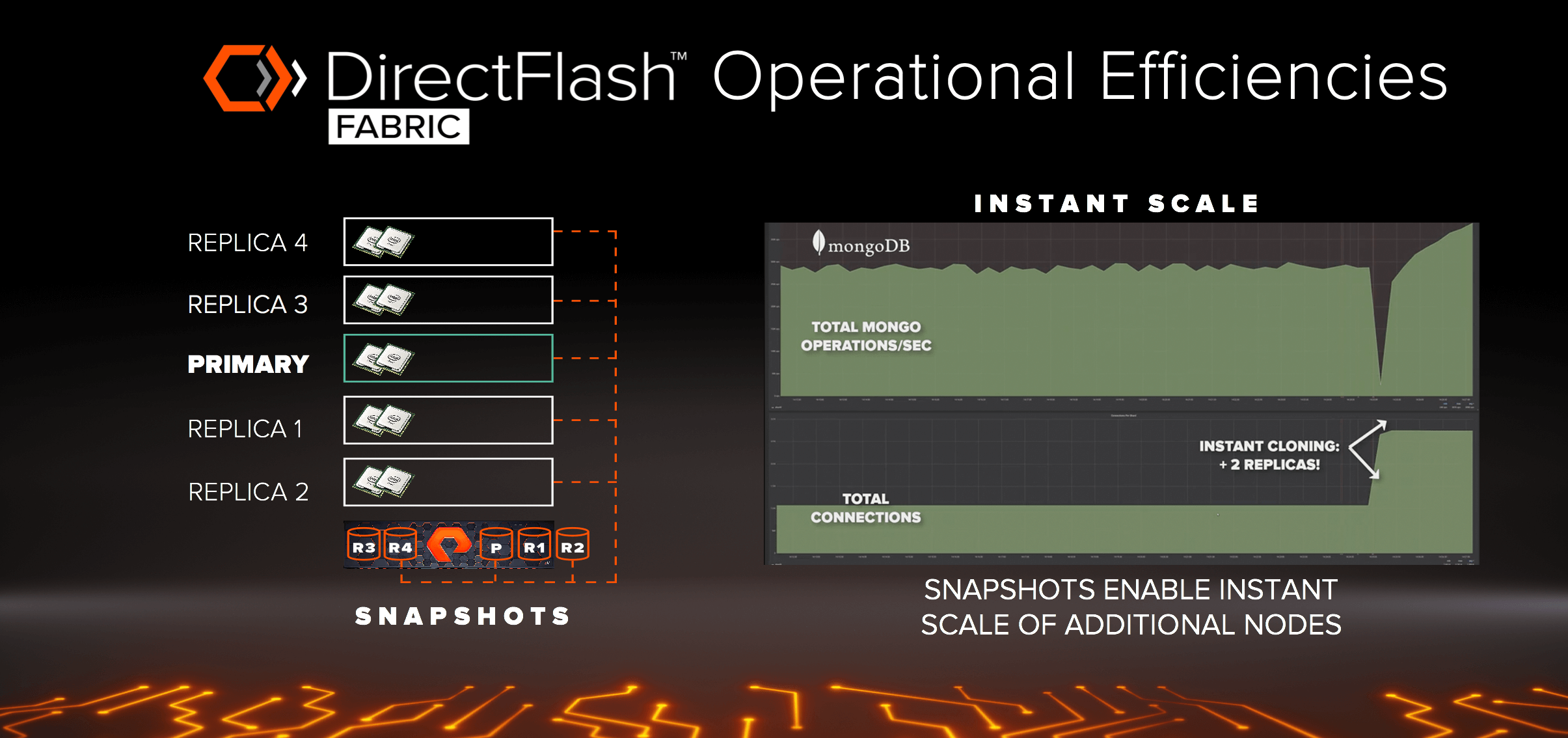
단순히 퍼포먼스만 향상하는 것이 아닙니다. 엔터프라이즈 수준 공유 스토리지를 통하여 운영 효율성을 높여 DAS로는 불가능 했던 새로운 프로세스를 사용할 수 있습니다. 여러분이 읽기 성능의 향상을 원한다면 피크 기간에 성능을 높이기 위하여 추가 노드를 스핀업 할 수 있습니다. DAS에서는 노드를 몇 개 더 추가하고, 새로운 복제본을 만든 뒤 이들이 싱크가 맞을 때까지 몇시간이고 기다려야 했습니다. 하지만 다이렉트플래시 패브릭(DirectFlash Fabric)을 사용하면 빠르게 스냅샷을 사용하여 추가 노드에 마운트하여 즉각적으로 스케일 할 수 있습니다. 스냅샷은 공간효율적이며 스냅샷의 변경 사항은 어레이 전체 데이터에 대해 글로벌 중복제거 및 압축되어 추가 용량이 필요하지 않습니다.
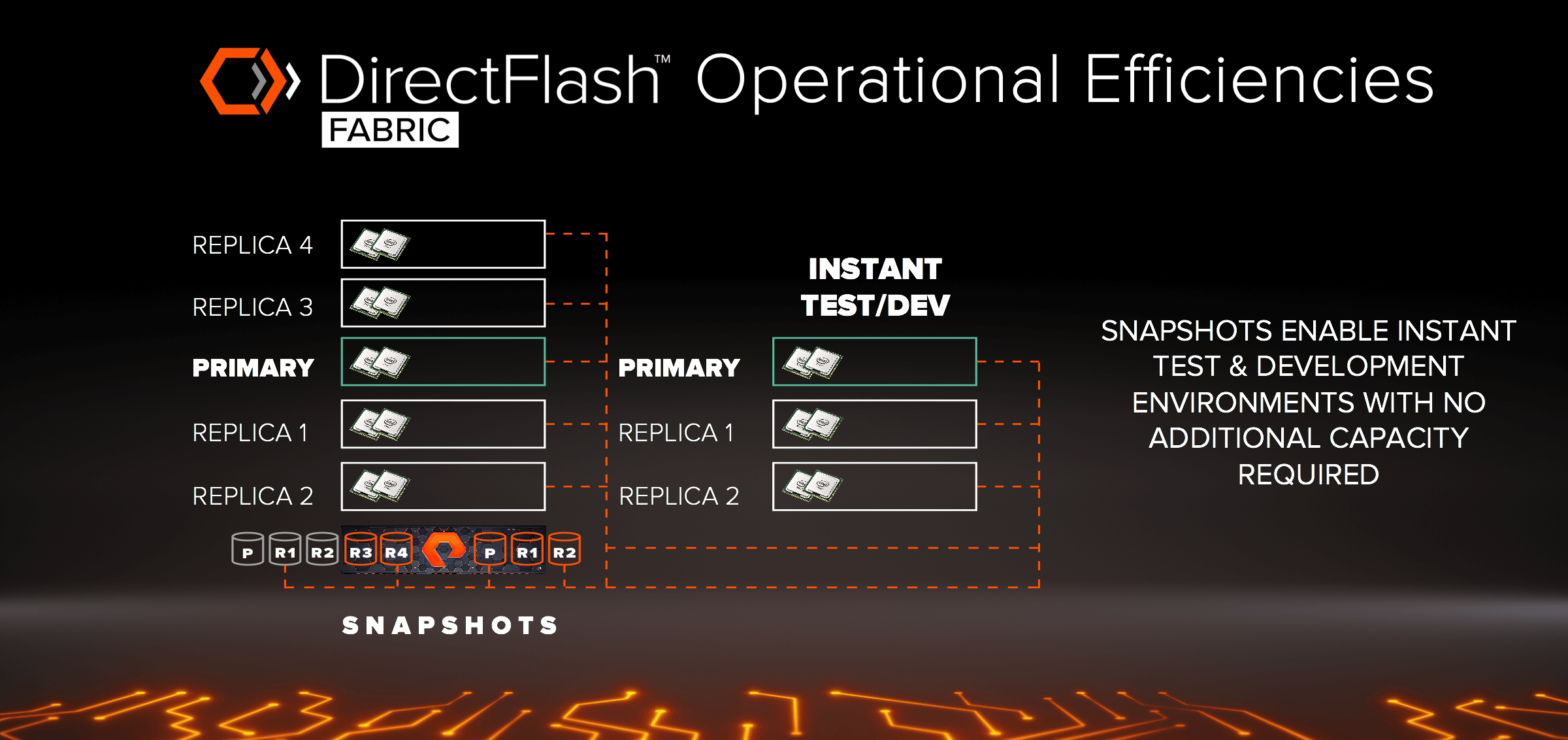
현재 운영환경의 몽고DB 데이터를 기반으로 하여 새로운 테스트나 환경 개발을 스핀업하는 것은 어떨까요? DAS의 경우에는 데이터를 복제하여 백업에 저장해야 합니다. 하지만 다이렉트플래시 패브릭(DirectFlash Fabric)의 경우는 스냅샷을 통해 운영환경에 아무 영향을 주지 않고 추가적인 용량이 필요 없이 즉각적으로 DB 인스턴스를 스핀업 할 수 있습니다. 그리고 이 모든 것이 REST API를 통하여 자동화될 수 있습니다.

다이렉트플래시 패브릭(DirectFlash Fabric)으로 DAS를 분리하면 일반적으로 DAS에서 빈번하게 발생하는 CPU 및 용량의 비효율적인 구성을 통합하고 제거할 수 있습니다. 이러한 효율성은 다음과 같은 곳에서 찾을 수 있습니다.
- 2 – 4X CPU 집적도. 2~ 4 RU(Rack Unit) 서버에서 1RU 서버나 블레이드 서버로 이전할 수 있습니다. 이를 통하여 컴퓨팅 집적도가 증가하고 결과를 더 빠르게 낼 수 있습니다.
- 랙 당 4 – 10X의 용량 집적도. 6RU의 플래시어레이(FlashArray)는 3PB의 용량을 가지고 있습니다.
- 25%의 CPU 오프로드를 통해 스토리지 I/O 작업의 많은 부분을 하드웨어로 오프로드하여 컴퓨팅 집적도의 효율이 더 높아집니다.
이 모든 것이 엔터프라이즈 수준 데이터 서비스로 묶여 있어 데이터셋을 가장 효율적인 형태로 줄이고, 비용을 낮춥니다.

컨버지드 인프라를 통하여 애플리케이션을 구축하고 싶은 고객을 위하여 엔드투엔드 NVMe 오버 패프릭 플래시스택(NVMe over Fabric FlashStack)을 소개합니다. 여기에는 시스코 넥서스(Cisco Nexus)의 스위치, 플래시어레이//X(FlashArray//X) 스토리지, 시스코 USC C-시리즈(Cisco UCS C-Series) 서버가 포함됩니다. 이를 통해서 여러분의 프라이빗 클라우드에서 하이퍼스케일 아키텍처를 배포하는 것이 매우 심플하고 편리해집니다.
기업들은 하이퍼스케일 준비가 되어있습니다

이제 모든 애플리케이션은 플래시어레이(FlashArray)를 통하여 기업들이 원하는 속도로 결과를 내놓을 수 있도록 할 수 있습니다. 전통적인 엔터프라이즈 애플리케이션의 경우, 퓨어의 NVMe 올플래시 어레이는 많은 혜택을 가져다 줄 것입니다. 클라우드 네이티브 앱에 대해서는 엔드투엔드 NVMe최적화로 애플리케이션 성능을 크게 높이고, 동시에 기업에 하이퍼스케일 아키텍처를 제공할 수 있습니다.
퓨어의 다이렉트플래시 패브릭(DirectFlash Fabric)와 파트너 에코 시스템, 그리고 애플리케이션이 얻는 혜택에 대하여 더 자세히 살펴보기 위해서는 아래 링크를 참조해 주세요.
- 퓨어가 선보이는 다이렉트플래시 패브릭: 플래시어레이를 위한 NVMe-oF
- 마리아DB와 다이렉트플래시 패브릭의 가능성 분석
- DAS를 넘어서: NVMe-oF RoCE 플래시어레이를 사용하는 몽고DB
- 빅데이터 안녕!!! 퓨어스토리지의 다이렉트플래시를 사용하는 플래시어레이, 호튼웍스 데이터 플랫폼 v3.0.0의 인증을 받다.
- 카산드라를 다이렉트플래시 패브릭과 함께 플래시어레이에서 구동할 때의 혜택
- NVMe-oF 서포트가 이제 출시됩니다!
- 플래시어레이 NVMe-oF과 SQL 서버 리눅스와 함께 성능의 지속성 알아보기
- 오라클 18c은 퓨어 다이렉트플래시에서 더 빠르게 운영된다
- 다이렉트플래시 패브릭 vs iSCI기반 에픽 워크로드



