

요약
Generative AI (GenAI) is one of the fastest-adopted technologies in history. Pure Storage is working with NVIDIA to bolster the power of GenAI for enterprise AI applications using retrieval-augmented generation (RAG).


생성형 AI는 역사상 가장 빠르게 도입된 기술 중 하나입니다. 그러나 이사회와 경영진이 이 기술을 진지하게 고려하도록 하려면, 엔터프라이즈 사용 사례에서 그 가치를 입증해야 합니다. 생성형 AI가 비즈니스, 혁신, 운영 속도를 어떻게 향상할 수 있을까요?
퓨어스토리지는 엔비디아와 함께 검색 증강 생성(RAG, Retrieval-Augmented Generation)을 사용해 엔터프라이즈 AI 애플리케이션을 위한 생성형 AI의 역량을 강화하고 있습니다. RAG를 대규모 고성능 LLM 사용 사례에 어떻게 사용할 수 있는지 자세히 알아보겠습니다.
검색 증강 생성(RAG)의 가치
검색 증강 생성은 기업이 구체적인 외부의 독점 데이터 소스를 사용해 일반적인 대규모 언어 모델을 개선하고 맞춤화할 수 있도록 합니다. 또한 생성형 AI의 주요 문제들을 바로 해결해주며, 대규모 언어 모델이 훈련에 사용된 지식 기반 외부의 지식을 참조하여 더 정확하고, 시기적절하며, 관련성이 높아질 수 있게 해줍니다.
대규모 언어 모델에서 발생할 수 있는 중요한 문제 중 하나인 할루시네이션(hallucination)은 그럴듯하지만 잘못된 응답을 생성하는 것을 의미합니다. 잘못된 추론으로 인해 조악한 경제적 분석, 트레이딩 또는 투자 권고가 생겨날 수 있고, 이 때문에 정확성이 중요한 실제 환경에서 이 기술을 사용하는 것이 어려워질 수 있습니다. 검색 증강 생성을 도입하면 할루시네이션의 위험을 줄일 수 있으며 분석가에게 더 나은 인사이트를 제공할 수 있습니다.
또 다른 문제는 대규모 언어 모델이 초기 훈련 이후에 사용할 수 있게 된 새로운 데이터를 통합하지 못한다는 것입니다. 이는 후속 훈련 이후에도 마찬가지입니다. 검색 증강 생성은 기업의 최신 데이터와 지식을 질의와 답변에 즉시 통합할 수 있으므로 LLM을 지속적으로 재훈련시킬 필요가 없습니다.
신뢰성, 정확성 및 적시성이 중요하고 엄격히 규제되는 금융 서비스 분야를 예로 들 수 있습니다. 구체적인 고객의 독점 벡터 데이터베이스로 일반적인 금융 LLM을 보강하면, 금융 기관은 자체 LLM을 훈련하는 능력을 향상할 수 있습니다. 기업의 재무제표, 브로커 보고서, 규정 준수 보고서, 고객 데이터베이스에서 얻어진 외부 데이터는 은행, 트레이딩 및 투자 회사들이 고객에게 더 나은 서비스를 제공하는 데 필요한 보다 구체적이고 의미 있는 분석을 제공하고, AI 시스템이 적시에 투자 인사이트를 생성하며, 데이터 소스를 검증하여 규정 준수를 강화하고 위험을 완화하도록 지원할 수 있습니다.
그러나 독점적인 LLM을 구축하고 훈련하는 데는 많은 비용이 듭니다. 검색 증강 생성은 기업이 상당한 비용과 자원을 절약하는 데 도움을 줄 수 있습니다. 특히 투자 수익률의 관점에서 생성형 AI를 비즈니스에 보다 효과적으로 활용할 수 있게 만들어줍니다.
예: AI 기반 기술 자료 구축
또 다른 업계의 사용 사례를 예로 들어보겠습니다. 제조업체가 제품 문서, 기술 지원 지식 기반, YouTube 비디오 및 보도 자료를 활용해 직원들에게 유용하고 정확한 답변을 제공하는 AI 기반 지식 시스템을 구축하려 합니다. AI로 생성되는 답변은 9개월 된 공개 데이터로 제한되어 있어 한계가 있고 기업의 제품 문서와 비디오를 참조할 수 없는 상황입니다.
RAG를 적용하면 고객과 직원들이 참조와 교육을 위해 최신 정보에 액세스할 수 있는 지식 시스템을 구축하고, AI로 운영, 영업 및 지원 프로세스를 개선할 수 있는 다양한 기회를 얻을 수 있습니다.
NVIDIA와 협력해 검색 증강 생성을 제공하는 퓨어스토리지
RAG 프로세스를 간소화하고 속도를 높이기 위해, 퓨어스토리지는 엔비디아와 협력해 엔터프라이즈 사용 사례를 시뮬레이션하여 AI 추론을 위한 검색 증강 생성 파이프라인을 시연합니다. 이는 엔비디아 GTC에서 오늘 발표된 새로운 NVIDIA NeMo Retriever 마이크로서비스(영문자료)를 보완하며, 엔비디아의 AI 엔터프라이즈 소프트웨어 제품군과 함께 프로덕션 등급 AI에 사용할 수 있게 될 것입니다.
엔비디아 GPU는 컴퓨팅에 사용되고 퓨어스토리지 플래시블레이드//S(FlashBlade//S)는 대규모 벡터 데이터베이스와 관련된 원시 데이터를 저장하는 올플래시 엔터프라이즈 스토리지로 사용됩니다. 이 사례에서, 원시 데이터는 RAG에 사용되는 퍼블릭 또는 프라이빗 문서 저장소에서 전형적으로 보여지는 대규모 공개 문서 모음으로 구성됩니다.
검색 증강 생성은 정리 및 벡터화된 데이터에 대한 쿼리의 벡터 검색 조회를 입력(새 문서 및/또는 독점 문서)으로 모델에 제공함으로써, LLM 추론의 정확성과 관련성을 향상합니다. 이를 통해 LLM으로 들어가는 매개변수에 더 나은 지침이 제공되고 사용자를 위한 출력이 미세 조정됩니다.
결과적으로 조직을 위한 LLM 추론 쿼리의 정확성, 적시성 및 관련성이 향상되어, 질문-답변 및 문서 요약 사용 사례에서 최종 고객이 쿼리를 더 유용하게 사용할 수 있게 됩니다.
왜 퓨어스토리지의 RAG여야 할까요?
까다로운 RAG 워크로드에 필요한 다차원적 성능을 제공하는 퓨어스토리지의 플래시블레이드//S는 벡터 데이터베이스, 분석, 임베딩용 원시 문서, AI 모델 및 로그 데이터를 저장할 수 있는 효율적인 고성능 공유 스토리지 플랫폼입니다.
이것이 중요한 이유는 다음과 같습니다.
- 비용.생성형 AI RAG 구현에서 벡터 데이터베이스가 수천만 개의 벡터를 넘어가며 규모가 커지면, 이에 맞게 GPU 메모리를 구성하는 데 엄청난 비용이 듭니다. 대안은 서버의 로컬 스토리지에 벡터 데이터베이스를 저장하는 것이지만, 이 경우 성능, 효율성 및 확장성이 제한될 수 있습니다.
- 성능.여러 문서 저장소와 수백 또는 수천 명의 AI 사용자가 있는 경우, RAG로 강화된 LLM은 여러 GPU 서버에서 실행됩니다. 이를 위해서는 훈련/임베딩 및 추론/검색이 가능하도록 확장 가능한 스토리지를 공유해야 합니다. 대규모 엔터프라이즈 생성형 AI RAG 솔루션에서 일부 서버는 새 문서를 임베딩 및 인덱싱하고, 다른 서버는 문서를 검색하며 LLM 쿼리를 동시에 수행합니다. 이는 스토리지가 여러 서버의 지속적인 읽기 및 쓰기 혼합을 지원할 수 있도록 다중 모드 성능 역량이 필요하다는 의미입니다.
- 확장.데이터 증가에 따른 확장은 중단 없이 간단하게 성능과 용량을 추가함으로써 간소화할 수 있습니다. 퓨어스토리지의 플래시블레이드//S 같은 엔터프라이즈 네트워크 스토리지 솔루션을 사용하면, 각 AI 서버 내에서 로컬 스토리지를 사용하는 것보다 강력한 데이터 보호, 더 나은 데이터 공유, 더 손쉬운 관리 및 더 유연한 프로비저닝이 가능해집니다. 또한 대규모 문서 저장소를 임베딩하고 인덱싱할 때 더 빠른 성능을 확보할 수 있습니다.
얼마나 빨라야 할까요?
퓨어스토리지는 생성형 AI RAG 임베딩 및 인덱싱을 위한 확장성 테스트를 실시했습니다. 2개의 엔비디아 GPU 서버(임베딩 서버)와 2개의 x86 서버(인덱스 노드)에서 테스트를 수행해, 기본 오브젝트 스토리지 인터페이스가 있는 로컬 플래시 스토리지를 사용하는 경우와 완전하게 갖춰진 플래시블레이드//S 1대를 사용하는 경우를 비교했습니다.
퓨어스토리지는 문서 임베딩 및 인덱싱 프로세스의 세 가지 단계를 테스트했습니다.
- 오브젝트 저장소에 벡터 파일 업로드
- 벡터 데이터베이스에 벡터 대량 삽입
- 인덱스 파일 생성 및 쓰기
결과는 두 노드(서버 2대와 인덱스 노드 2개)에서 RAG 프로세스를 실행하는 것이 한 노드만 사용하는 것보다 훨씬 빠르며, 여러 노드에 걸쳐 RAG를 확장할 수 있다는 사실을 강조해 보여주었습니다.
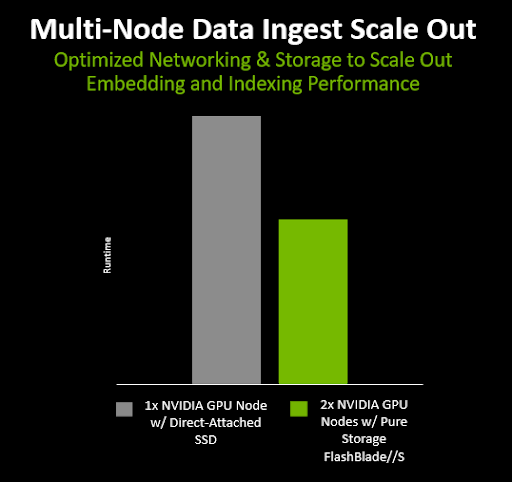
그림 1: 다중 노드 스케일 아웃 테스트 결과
또한 플래시블레이드//S를 네이티브 S3 인터페이스와 함께 사용하는 경우, 각 서버 내부에 있는 로컬 SSD를 사용하는 경우 보다 36% 더 빠르게 문서 임베딩과 인덱싱이 완료되었습니다. 이는 네트워크로 연결된 올플래시 스토리지가 RAG 문서 임베딩을 가속화하는 데 도움이 된다는 것을 보여줍니다.
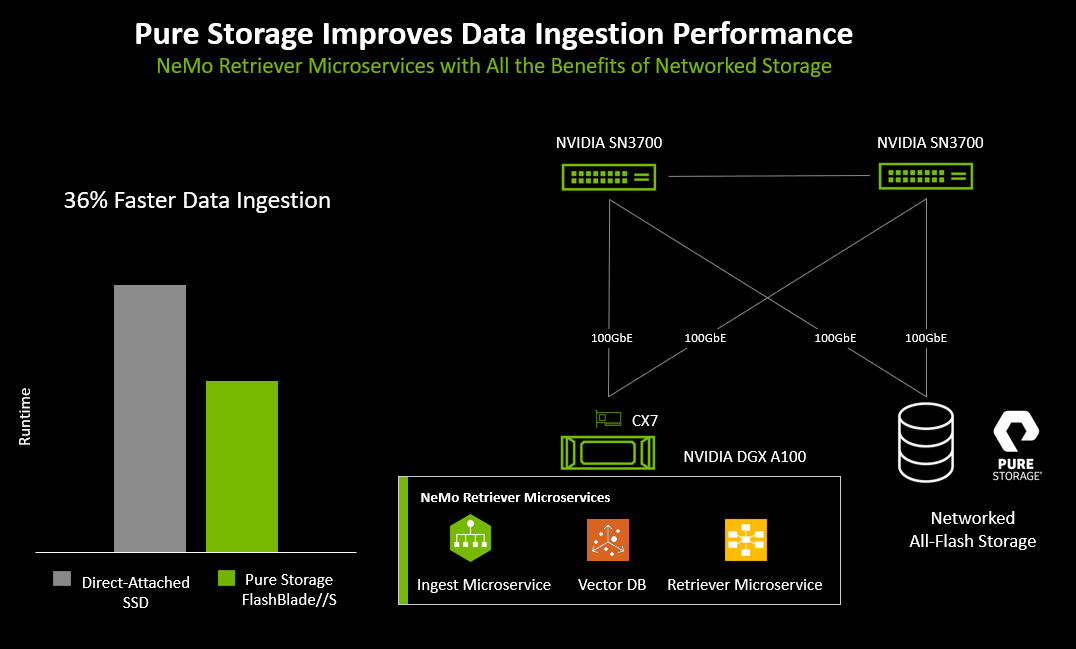
그림 2: RAG 프로세스 테스트 결과
고객이 얻을 수 있는 혜택
LLM과 엔비디아의 GPU, 네트워킹, 마이크로서비스, 그리고 퓨어스토리지의 플래시블레이드//S를 사용한 이 RAG 파이프라인은 몇 초 만에 전체 문서 저장소를 벡터 데이터베이스로 처리하고 쿼리할 수 있음을 보여주었습니다. 벡터 데이터베이스 내부의 보강된 정보와 LLM의 생성 기능을 기반으로 결과가 반환되기 때문에 이는 굉장한 결과입니다.
퓨어스토리지의 플래시블레이드//S는 로깅, 벡터 데이터베이스, 분석 및 원시 데이터 전반에서 다차원적인 성능을 제공하는 빠르고 효율적인 엔터프라이즈 스토리지 역할을 수행합니다. 운영 중단 없이 다이렉트플래시(DirectFlash) 모듈의 블레이드를 추가해 성능이나 용량을 향상할 수 있기 때문에, 빠르게 증가하는 다중 모드와 실시간 스트리밍 데이터 요구 사항을 신속하게 충족할 수 있습니다. 따라서 LLM과 RAG를 프로덕션 비즈니스 프로세스에 추가하려는 기업에게 이상적인 솔루션입니다.
퓨어스토리지가 어떻게 AI 도입을 가속화하는지 자세히 알아보려면 AI 솔루션 페이지에서 영업 팀에게 문의해주시기 바랍니다.
Written By:



