
2018년 5월 말 퓨어스토리지의 //Accelerate 행사에서 찰스 잔칼로(Charles Giancarlo) CEO는 미래의 데이터센터 인프라스트럭처에 대한 퓨어스토리지의 비전 ‘데이터 센트릭 아키텍처(Data-Centric Architecture)’를 소개였습니다. 데이터 중심의 아키텍처는 기업이 스토리지가 중요성을 가지는 인프라스트럭처 설계의 중심에 데이터를 둘 수 있도록 지원할 것입니다.
퓨어스토리지는 플래그십 제품인 플래시어레이(FlashArray) 제품군의 7세대 제품을 소개하였습니다. 플래시어레이는 AFA라는 카테고리를 창조한 혁신적인 올플래시 어레이입니다. 완전히 새로운 스토리지 아키텍처를 가진 이 플래시어레이가 어떻게 서로 각기 다른 군에 속해있는 공유 스토리지(SAN/NAS)와 직접 연결 스토리지(DAS)는 물론, 클래식 애플리케이션과 현대의 스케일-아웃 애플리케이션을 통합할 수 있는 잠재력을 가지고 있는지에 대해 자세히 말씀을 드리도록 하겠습니다. 또한 퓨어스토리지는 지금 바로 사용이 가능한 이 새로운 아키텍처가 왜 빠른 시일 내에 표준화될 것이라고 믿는지에 대해서도 말씀드리겠습니다.
과거로부터의 교훈
잠시 2009년으로 되돌아 가보겠습니다. 플래시가 막 시장에 등장했고, 가장 승승장구하고 있던 스토리지 기업은 Fusion-IO였습니다. 업계가 플래시를 바라보는 시선은 아래와 같았습니다.

플래시는 초고속 성능을 제공하지만 대단히 높은 가격($20/GB) 때문에 “틈새(Niche)” 기술로 간주되었습니다. 경제적으로 만들기 위해, 대형 스토리지는 계층화/캐싱 모델로, 작은 플래시는 수많은 디스크와 함께 사용되었습니다.
퓨어스토리지는 이러한 시기에 태어났습니다. 퓨어스토리지는 플래시가 주류가 될 수 있는 잠재력을 가지고 있다고 믿었지만 이를 위해서는 핵심적인 문제들을 해결해야 했습니다. 즉, 플래시를 보다 경제적이고(GB당 $5 미만으로 만드는 것이 당시 목표였습니다!), 안정적이며 간단하게 설계하여 쉽게 도입을 할 수 있도록 만드는 것이었습니다. 실제로, 당시 적색 로고를 달고 나타난 “Os76”라는 이름의 작은 기업도 생겨났었습니다.

이러한 상황들이 조합되어 AFA 카테고리가 생겨났고, 많은 카피캣들이 뒤를 따랐습니다. 그러나 가장 중요한 것은, 스토리지 업계에서 긍정적인 변화가 일어나기 시작했다는 것입니다. 스토리지는 더욱 간단해지고 효율적이며, 더 빨라졌습니다. 그리고 AFA는 새로운 스토리지라는 인식이 보편화되었습니다.

그렇다면 이러한 과거로의 시간 여행으로부터 어떤 교훈을 얻을 수 있을까요? 마법은 기술을 만드는 것에서 시작되는 것이 아니라 그 기술을 주류로 이끄는 것에서 생겨납니다. 실질적인 혁신이 일어나는 곳이기 때문입니다.
데이터센터를 재창조할 시간
퓨어스토리지는 데이터 센트릭 아키텍처에 대한 비전을 발표하면서 현대적인 웹 스케일 분산 애플리케이션들로 향한 이동이 어떻게 스토리지에 대한 요구사항을 완전하게 변화시키고 있는지에 대해서도 언급했습니다. 여기서 핵심은 기존 스토리지가 네트워크에 연결(SAN/NAS)되거나 직접 연결(DAS)되는 두 가지 아키텍처로 제공되었다는 것입니다.

근본적으로 어떤 것이 더 좋거나 나쁘다고 할 수 없으며, 각자 장단점이 있습니다. 수십 년 동안 네트워크 연결 스토리지가 비즈니스에 핵심적인 애플리케이션을 위한 주축이 되어온 반면, DAS 스토리지는 지난 몇 년간 빅데이터, 분석, 웹 스케일 데이터베이스 및 HCI 사용사례 등에서 다시 등장했습니다.
DAS가 가진 장점은 굉장히 단순합니다. 저비용의 상용 인프라스트럭처, 표준화, 추가 노드 당 선형 확장 등을 들 수 있습니다.

그러나 대부분의 사람들은 DAS의 현실이 그다지 밝지만은 않다는 사실을 알게 되었습니다. DAS는 저절로 구동 되지 않습니다. 현대적인 애플리케이션 파이프라인의 경우 10~20개의 툴이 필요하고 각 툴은 이상적인 확장 노드를 위해서 또 각자의 “레시피”가 필요합니다. 노드에 표준화를 시키면, 해당 노드에 종속이 됩니다. 모든 앱에서 갑자기 스토리지와 연산의 양이 너무 커지거나 너무 작아져서 적정 수준을 찾을 수 없는 상태가 되어버립니다. 십여 개, 아니 백여 개가 되는 랙이 존재하는 상황에서 불량 SSD의 노드 하나에 문제가 생겨 장애를 관리해야 하는 경우는 언급하지도 않겠습니다. 또한 샤딩과 노드 설계를 잘못하면, 새로 시작하기가 굉장히 어렵습니다. 이 때문에, DAS 인프라스트럭처에 분열이 생기기 시작하지 않았나 싶습니다. HCI 공급업체들은 스토리지만 포함된 노드를 공급하고, 하둡 공급업체는 서버와 스토리지를 분리할 것을 권장하고 있습니다. 공유 스토리지가 그렇게 나쁜 아이디어가 아니었을 수도 있지 않을까요?
현실적으로, 우리는 두 가지 모두를 가지고 있습니다. 기존의 스케일-업 앱과 VM을 가지고 있으며, DAS를 기대하는 새로운 웹 스케일 애플리케이션을 구현하길 원합니다. 서로 다른 두 가지 인프라스트럭처를 꼼짝 없이 떠맡게 된 것일까요?
모든 것을 변화시키는 빠른 네트워크와 프로토콜
부상하고 있는 주류 플래시(워크로드를 잘 혼합하는 성능을 갖춘 빠른 스토리지)는 빠르며 대중적으로 보급된 값산 네트워킹과 맞물려, 이제 그 가능성의 한계를 시험하고 있습니다. 이제 25Gb/초 이더넷은 보편화 되었습니다. 100Gb/초 역시 비용이 지나치게 높지 않으며, 400Gb/초는 코앞으로 다가왔습니다. 그러나 더 중요한 것은 NVMe & NVMe-oF 같은 병렬 스토리지 프로토콜이 등장해, 이제 정말 최적화된 방식의 네트워크 스토리지에 대해 얘기할 수 있게 되었다는 것입니다. 왜 NVMe-oF가 그렇게 중요할까요?

간단히 말해, NVMe-oF는 네트워크에서 공유되는 스토리지가 ‘박스’ 안에 들어 있거나 서버의 PCIe 버스에 있는 스토리지처럼 빠르게 작동할 수 있게 만들어줍니다. 그러나 더 중요한 사실은, 오늘날의 서버 CPU는 SCSI 명령을 처리하는데 많은 시간을 소비한다는 것입니다. 퓨어스토리지가 테스트를 해본 결과, IO 로드가 높으면, 최대 20~30%의 CPU 시간이 낭비될 수 있습니다! NVMe-oF는 기본적으로 더 효율적인, 오프로드된 프로토콜이기 때문에, 이러한 CPU 페널티가 제거됩니다. 이는 지난 몇 년 동안 당연히 여겨왔던 무어의 법칙에 따른 CPU의 지속적인 진보를 더 이상 기대할 수 없는 상황에서 그 중요성이 더 커집니다. 마지막으로, 병렬 앱은 이제 병렬 프로토콜로 스토리지와 통신할 수 있는 병렬 서버에서 실행될 수 있다는 것입니다. 그리고 스토리지 장치는 병렬 플래시까지 전부 병렬화가 될 수 있습니다. 플래시의 진정한 병렬 성능이 마침내 실현될 수 있게 된 것입니다!

만약, 단일한 아키텍처가 SAN과 DAS를 진정한 데이터 중심 아키텍처로 통합시킬 수 있다면 어떨까요? 빠른 병렬 네트워크를 통해 무스택, 무디스크 연산을 제공하는 빠르고 안정적인 공유 스토리지 서비스를 지원하는 아키텍처 말입니다. 전혀 새로운 유형의 스토리지처럼 들리지 않으시나요?
새로운 스토리지 카테고리: 공유 가속화 스토리지
시장조사기관 가트너에 따르면 이러한 전환이 일어나고 있습니다. 그리고 가트너는 이러한 새로운 유형의 스토리지를 위해 ‘공유 가속화 스토리지(Shared Accelerated Storage)’라는 용어를 만들어 냈습니다. 이 용어는 새로운 무언가의 핵심을 정확히 짚어냈다고 생각합니다. 바로 애플리케이션을 위한 ‘가속화’된 데이터에 대한 액세스 ‘공유’라는 것입니다. 이 스토리지는 기존의 올플래시 어레이가 아닙니다.

“NVMe-oF는 이 두 아키텍처를 통합할 수 있는 힘을 가지고 있다”는 가트너의 말은 상당히 흥미롭습니다. 그렇다면, 이 새로운 스토리지는 어떤 모습을 하고 있을까요?

간단히 말하자면, 공유 가속화 스토리지는 빠른 융합 네트워크에서 병렬에 최적화된 프로토콜(NVMe-oF)을 사용해, 무디스크/무상태 서버를 공유되는 스토리지에 연결할 수 있도록 해주는 새로운 클래스의 스토리지입니다. 스토리지 계층에서, 완전하게 병렬 최적화된 소프트웨어를 갖춘 공유 스토리지 장치는 컴퓨트에서 플래시 칩까지, 모두 플래시에 최적화된 병렬 아키텍처로 된 병렬 NVMe 프로토콜로 플래시와 통신합니다. SCSI를 사용하지도 않고 레거시 디스크 드라이브인척 가장을 하지도 않습니다.
플래시로의 전환에서와 마찬가지로, 많은 사람들이 앞으로 NVMe와 NVMe-oF를 시도하고 개조할 것입니다. 그러나 진정한 공유 가속화 스토리지를 제공하려면 처음부터 설계를 그렇게 해야 합니다. 퓨어스토리지는 이러한 변혁을 수년 동안 준비해왔습니다.

플래시의 병렬성을 위해 설계된 퓨리티 OS(Purity OS)의 최초 버전에서부터, 전역적 플래시 관리를 지원하는 소프트웨어까지, 퓨어스토리지는 이 새로운 세상을 위해 소프트웨어를 설계했습니다. 2015년 처음으로 플래시어레이//M(FlashArray//M) 섀시를 출시했을 때, 퓨어스토리지는 표준이 아직 최종 결정되지 않은 상태에서 NVMe을 내장하여, 세계 최초의 듀얼 포트 NVMe 장치를 NV-RAM(현재 25,000여 대 운영 중)으로 공급했습니다. 그리고 플래시블레이드(FlashBlade™)를 통해, 소프트웨어를 원시 NAND와 직접 인터페이스해서 레거시 SSD 폼팩터의 비효율성을 제거하였고, NVMe를 활용하여 원시 플래시로의 고도의 병렬 통신을 생성하는 다이렉트플래시(DirectFlash™) 소프트웨어를 출시했습니다.
한편, 경쟁업체들은 많은 타협을 했습니다. 레거시 디스크 어레이를 지속적으로 개조를 하고, NVMe 플래시를 캐싱 계층에서만 활용하는가 하면, 플래시를 비효율적인 SSD에 의존하여 궁극적으로 공유 가속화 스토리지를 위한 소프트웨어를 개발하고 최적화하는 힘든 작업을 완료하지 못했습니다. 그 부분에 대해서는 나중에 자세히 설명을 해드리겠습니다.
그렇다면, 공유 가속화 스토리지가 모두를 위한 것일까요?
이 부분에서 약간의 문제가 발생하게 됩니다. 과거로부터 교훈을 얻을 수 있는 부분입니다. 현재, 시장은 올 NVMe 스토리지를 2009년 당시 플래시를 바라보던 시선으로 보고 있습니다. 스토리지 업계에 있는 모든 사람들이 올 NVMe 스토리지를 새롭고, 이국적인, 고성능/고비용 스토리지 옵션으로 생각하는 듯합니다.
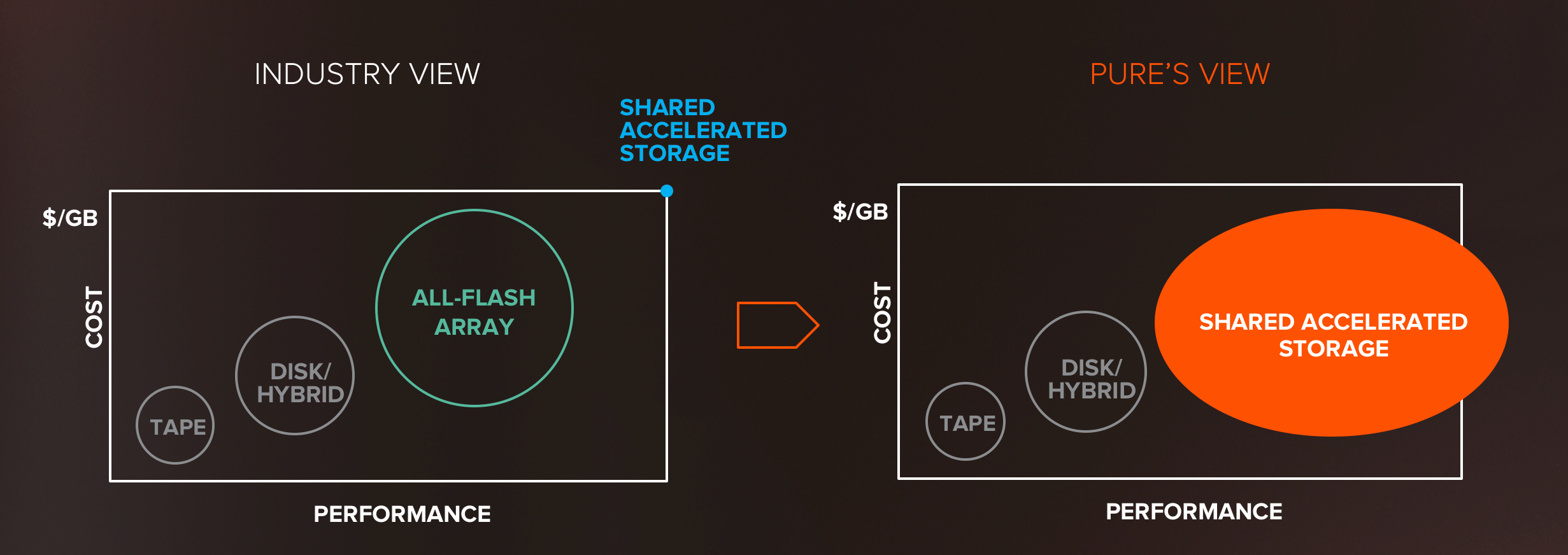
Dell-EMC는 한층 더 나가서 이 새로운 스토리지를 위해 “티어 0 스토리지”라는 말까지 만들었습니다. 티어 1 어레이보다 위에 있는 스토리지란 뜻입니다. 퓨어스토리지의 관점에서 보면, 지금은 “티어 0″적인 사고를 끝낼 때입니다. 데이터센터 아키텍처에 진정한 영향을 줄 수 있는 공유 가속화 스토리지가 되려면, 주류에 진입해야 합니다. 그리고 퓨어스토리지는 바로 오늘 그것을 실현하고자 합니다.

작년에 출시된 플래시어레이//X(FlashArray//X)는 업계 최초의 올 NVMe 어레이입니다. 올 NVMe 스토리지를 주류로 편입시키기 위한 퓨어스토리지의 여정은 그로부터 시작되었습니다. 지난 5월 말, 퓨어스토리지는 새로운 플래시어레이//X((FlashArray//X)) 제품군, //X10, //X20, //X50, //X70, //X90을 출시를 통해 비전을 공개하였습니다.
퓨어스토리지의 새로운 플래시어레이//X는 데이터센터의 모든 워크로드를 위한 올 NVMe 스토리지이며, 모든 가격대로 제공됩니다. //X와 //M은 이제 모든 기능을 수행하는 하나의 제품군으로 통합됩니다.
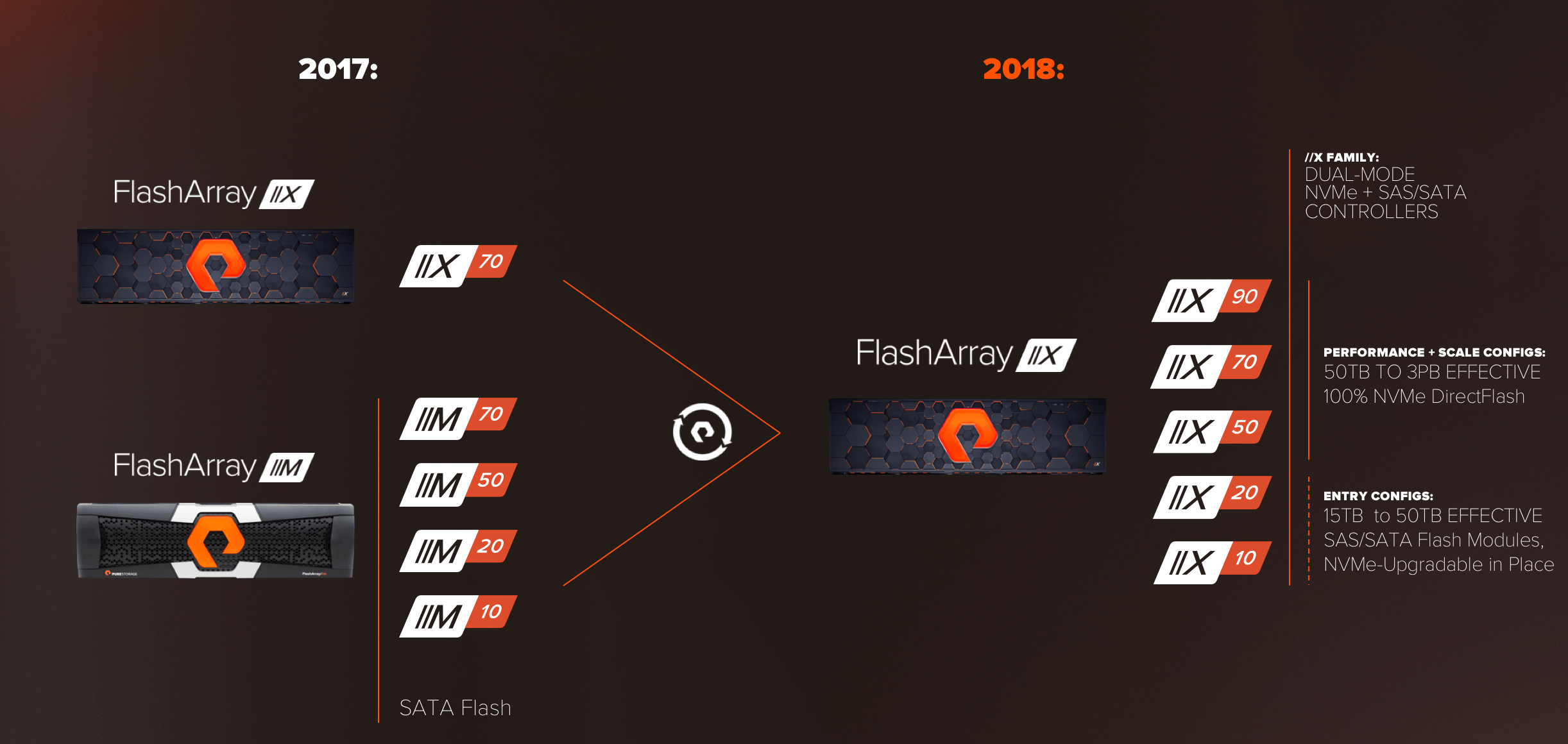
전체 //X 제품군에는 새로운 듀얼 모드 컨트롤러가 포함됩니다. PCIe에서 NVMe를 사용할 뿐만 아니라, SAS에서 SCSI를 사용해 //X의 미드플레인으로 통신하여, 같은 플랫폼에 퓨어스토리지의 기존 SAS/SATA 플래시 모듈은 물론 퓨어스토리지의 NVMe 다이렉트플래시 모듈이 탑재될 수 있도록 해줍니다. 이는 //M에서 //X로 쉽게 업그레이드할 수 있게 해주고(여기에 대해서는 나중에 더 자세히 설명해드리겠습니다.), 모든 사용사례에 맞게 제품을 구성할 수 있도록 해줍니다. 퓨어스토리지의 대표적인 어레이인 //X50과 //X70, 그리고 새로운//X90에는 올 NVMe 다이렉트플래시 모듈만, 2.2~18.3TB 용량으로 탑재됩니다. 이 때문에 유효용량이 50TB에서 최대 3PB인 모든 올 NVMe 솔루션을 //X90에 설정할 수 있습니다. 엔트리 레벨 제품인 //X10과 //X20은 기존 SAS/SATA 모듈(현재 2.2TB 이하의 다이렉트플래시 모듈은 만들지 않음)이 이미 탑재되어 출시되지만 컨트롤러는 미래의 확장을 위해 NVMe 매체를 지원할 수 있는 완전한 역량을 보유하고 있습니다.
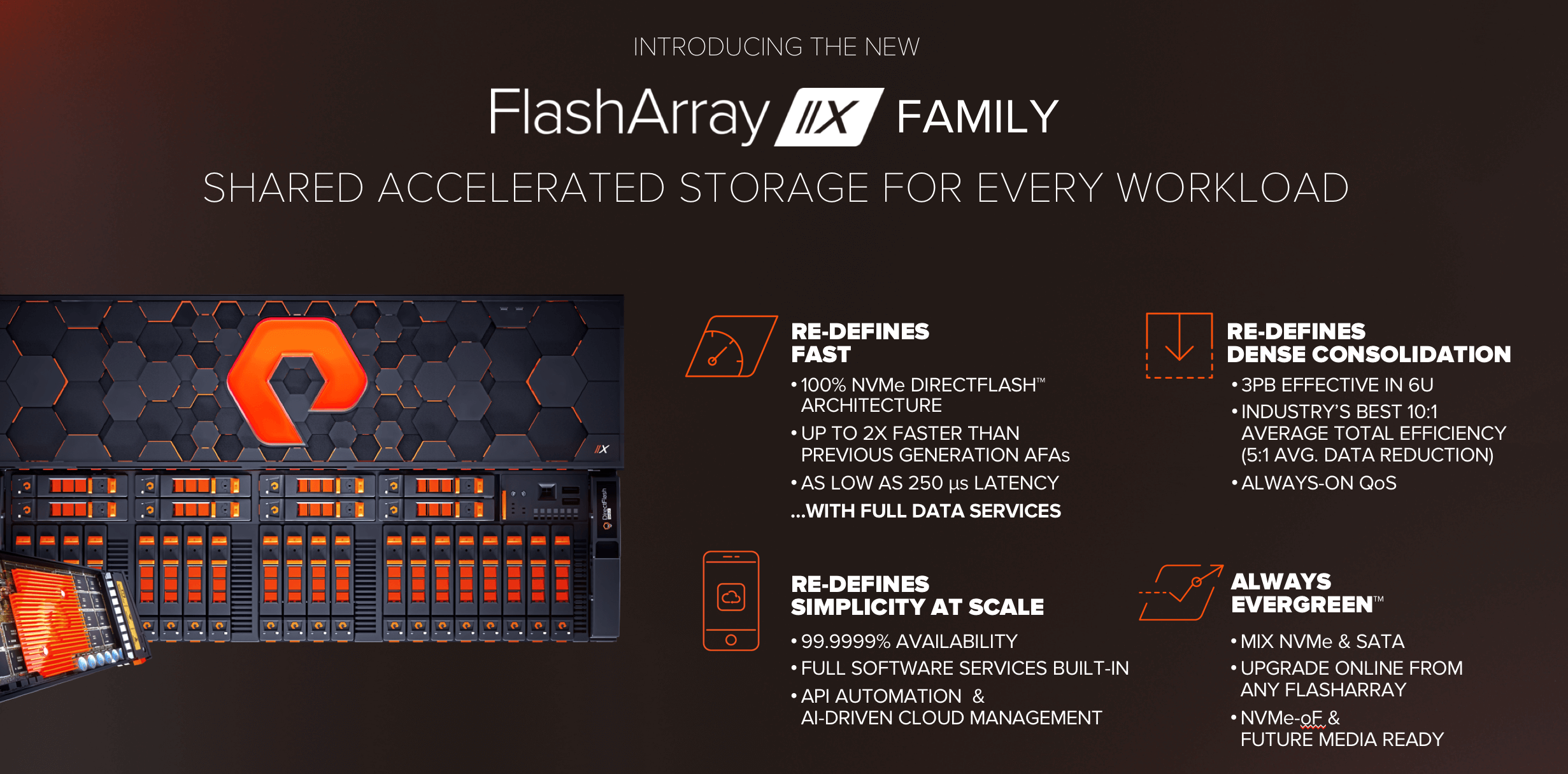
새로운 플래시어레이//X(FlashArray//X) 제품군은 속도와 집적도의 표준을 재정의합니다.
플래시어레이//X(FlashArray//X)는 퓨어스토리지의 다이렉트플래시 아키텍처에 구축됩니다. 이 아키텍처는 플래시 관리를 위한 다이렉트플래시 소프트웨어를 다이렉트플래시 모듈로 제공되는 RAW NAND와 결합하여, 기존 SSD 보다 획기적으로 빠른 성능과 월등한 효율성을 제공합니다. 다이렉트플래시를 제공하는 것은 퓨어스토리지 뿐입니다. 다이렉트플래시에 대한 세부적인 정보는 이 블로그를 확인해보십시오.
100% NVMe 다이렉트플래시 아키텍처는 모든 데이터 서비스가 활성화된 상태에서 기존 //M 올플래시 어레이보다 최대 2배 높은 성능과 최소 250µs의 레이턴시를 제공합니다(약간의 µs를 타협하더라도 더 큰 간단함과 데이터 효율성을 얻는 것이 더 가치가 있다는 생각입니다).
새로운 모든 컨트롤러들은 NVMe-oF에 대한 준비를 갖추었습니다. 컨트롤러에는 25 Gb/초 이더넷이 내장되어있고, NVMe-oF에 준비된 16/32 Gb/초 광채널 또는 50 Gb/초 Ethernet(향후 100 Gb/초이더넷)과 설정될 수 있습니다. 퓨어스토리지는 올해 후반기에 무중단 소프트웨어 업그레이드를 통해 NVMe-oF를 지원할 계획입니다. 지금 보시는 사양은 iSCSI와 FC를 사용하기 때문에, NVMe-oF가 활성화되면 //X의 속도는 더 빨라질 것입니다.
대역폭과 레이턴시가 향상되면 모든 애플리케이션에 물론 도움이 되지만, 다이렉트플래시를 갖춘 올 NVMe 아키텍처의 가장 큰 혜택은 새로운 수준의 통합이 가능해진다는 것입니다. //X90는 6U에 최대 3PB의 유효용량을 제공합니다. 퓨리티의 업계 선두적인 데이터 절감율(평균 10:1의 총효율성 및 5:1 데이터 절감율)은 광범위한 워크로드를 효과적으로 절감할 수 있도록 해주고, 퓨어스토리지의 상시 QoS는 혼합 워크로드가 어레이에서 지속적으로 최고의 성과를 낼 수 있도록 해줍니다.
가장 좋은 점은 //X 역시 퓨어스토리지의 플래시어레이기 때문에, 플래시어레이에서 기대되는 간단함과 완전한 소프트웨어 서비스, 그리고 퓨어1(Pure1)의 수월한 관리를 변함없이 이용할 수 있다는 것입니다. 그 뿐만 아니라 //X는 에버그린(Evergreen)™서비스로 구동됩니다. 기존 고객들은 중단없이 //M에서 //X로 이동할 수 있습니다. SATA 플래시를 그대로 유지하고 NVMe 다이렉트플래시를 추가하거나 업그레이드플렉스(UpgradeFlex) 용량 통합을 이용해 SATA 플래시를 집적도가 훨씬 높은 새로운 NVMe 플래시로 보상 교환할 수 있습니다. 경쟁업체들이 업그레이드 방법이 없는 새로운 제품들을 내놓고 있는 가운데, 퓨어스토리지는 데이터를 그대로 둔 상태로 이미 7세대 플래시어레이로의 무중단 업그레이드를 제공하고 있습니다.
:

더 빠른 속도 + 더 높은 집적도 = 좋아하지 않을 이유가 있을까요?
그렇다면 플래시어레이//X(FlashArray//X)의 실질적인 가치는 무엇일까요? 1세대 //X70이 시장에 나온지 일년이 지났습니다. 이로부터 나오는 매출이 퓨어스토리지 총매출의 20% 이상을 차지합니다. 고객들의 반응은 대단했습니다. 초기 //X 수용자인 호스팅 기업 맥스태디엄(MacStadium)을 그 예로 들 수 있습니다.
가장 간단한 단계에서, //X는 모든 것을 가속화합니다. 더 빠른 속도를 싫어하는 사람은 없습니다. 경쟁업체들이 올 NVMe 제품을 출시했을 때, 초고속 성능 사양이라고 주장하기 위해 전형적인 벤치마케팅에 의존하는 모습을 볼 수 있었습니다. 일례로 한 경쟁업체는 소량의 캐시 히트 읽기를 사용해 벤치마케팅 했습니다. 올 NVMe 어레이인데, NVMe는 전혀 사용하지 않고 DRAM만 사용했다는 말입니다. 수치는 놀랍지만 고객들이나 업계에는 별로 도움이 되지 않는다는 느낌을 지울 수 없습니다. 퓨어스토리지는 대신, 워크로드에 맞게 //X 솔루션을 가장 효과적으로 설계할 수 있도록 현장 조직들에게 세부적인 성능 규모 산정 데이터베이스를 제공하는 쪽을 선택했습니다.
이번 출시를 위해, //X를 시장을 정의하는 유일한 올플래시 어레이인 //M과 비교하여 포괄적인 성능 특성을 완성했습니다. 광범위한 애플리케이션 전반에서, //X는 획기적으로 높은 성능을 제공합니다. iSCSI와FC SAN에서도 마찬가지입니다.
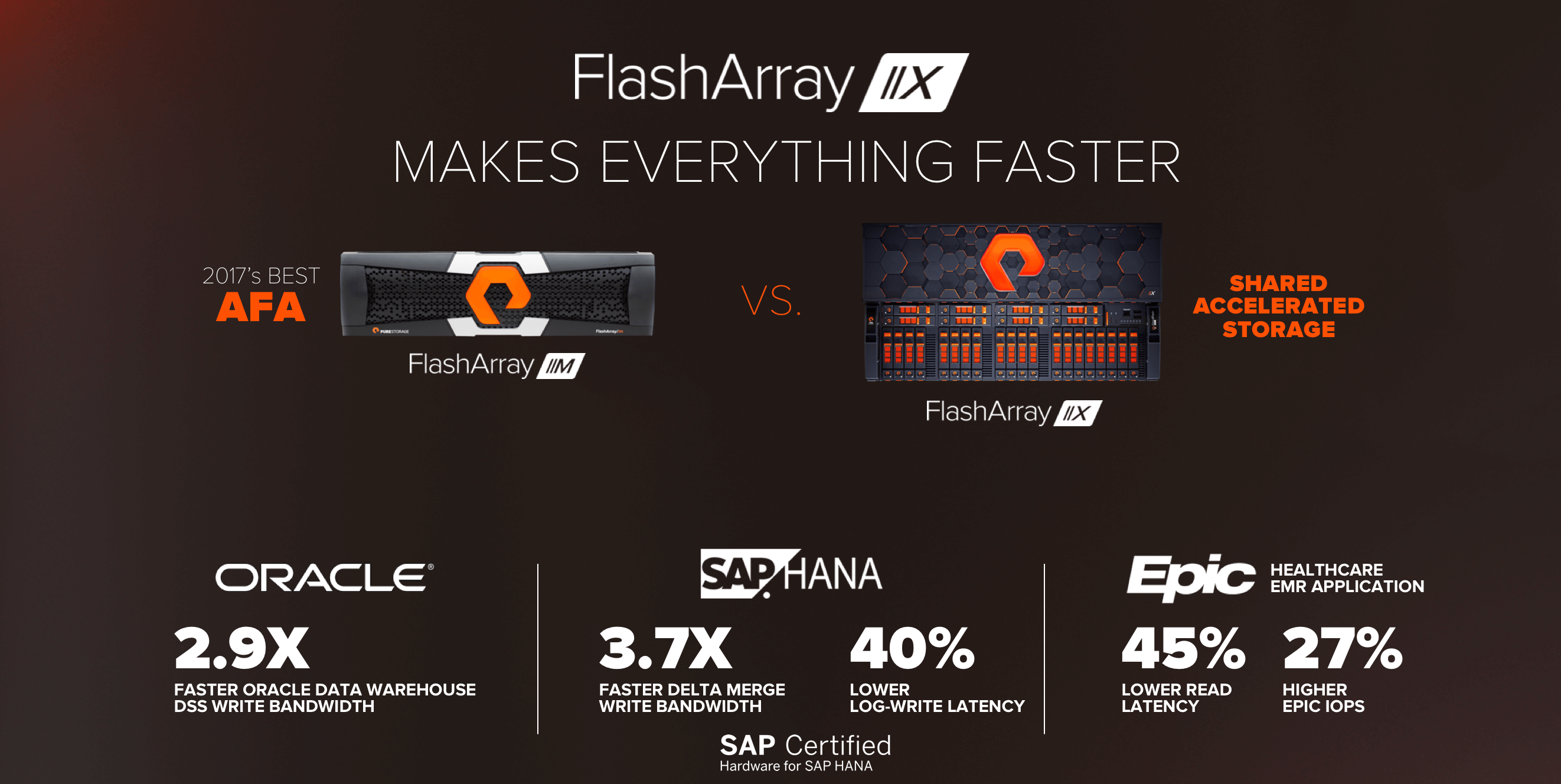
오라클 테스트에서는, 데이터 웨어하우스 테스트로부터 DSS 읽기 대역폭에서 2.9배나 향상된 성능을 제공했습니다. SAP HANA에서는 델터 통합 쓰기 대역폭에서 3.7배 더 높은 성능을 제공했고 레이턴시도 40%가 더 낮았습니다. 시장 선두적인 헬스케어 EMR 애플리케이션인 Epic의 경우, 레이턴시는 45% 더 낮았고 EPIC 트랜잭션은 27% 더 많았습니다. 이는 개괄적으로 요약한 것입니다. 테스트 결과에 대한 보다 자세한 정보는 Oracle, SAP, Epic 등의 애플리케이션에 대한 블로그를 참조하십시오.
애플리케이션의 성능이 빠른 것도 좋지만, 진정한 데이터 센트릭 아키텍처로 이동한다는 것은 기본적으로 데이터를 공유한다는 것을 의미합니다. 그렇기 때문에 통합이 중요합니다. //X와 올 NVMe의 진정한 가치는 타협 없는 통합 성능입니다.
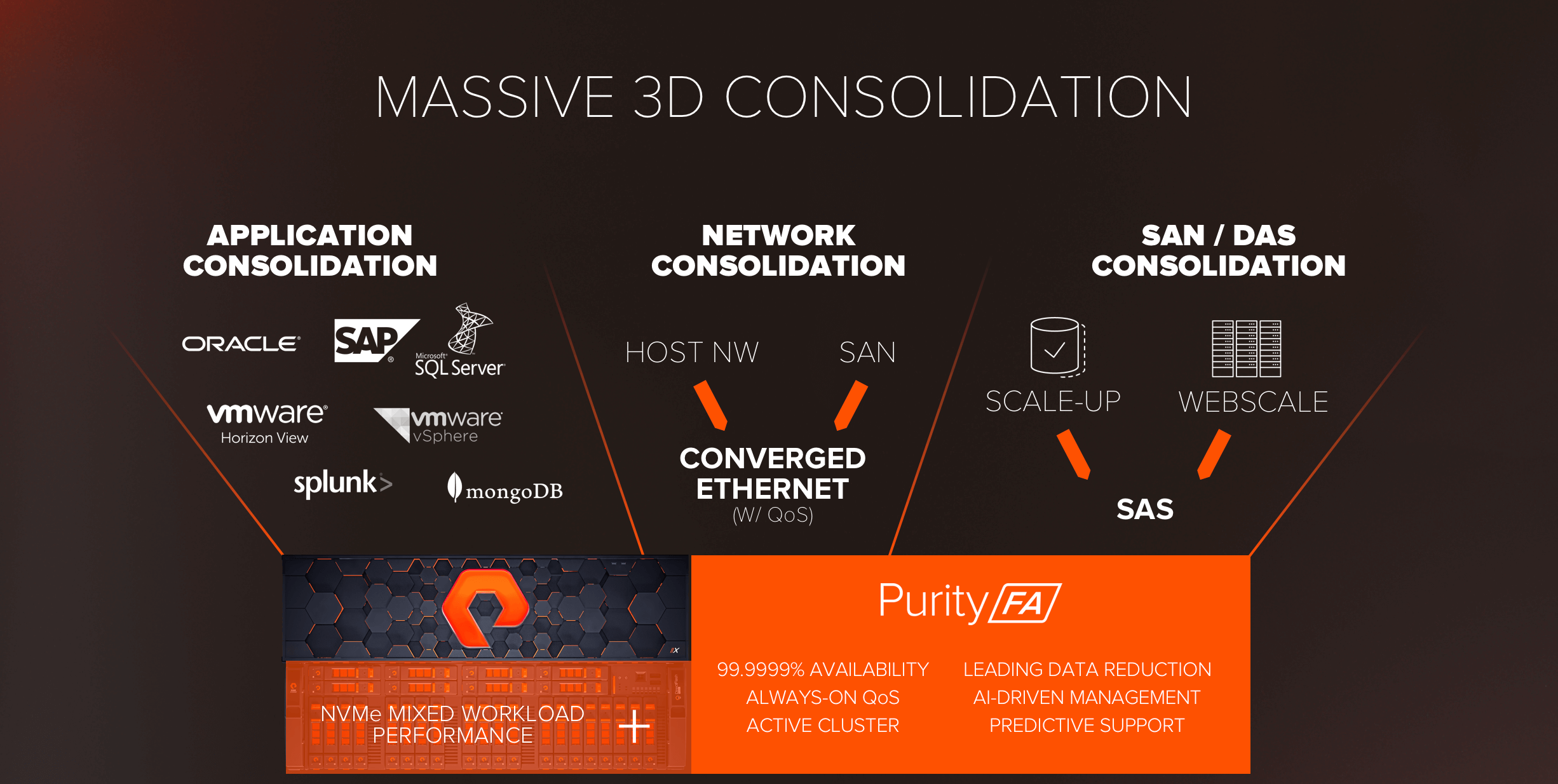
공유 가속화 스토리지와 //X는 세 가지 차원의 통합을 약속합니다. 광범위한 애플리케이션을 단일한 어레이에서 통합하고, 네트워크를 통합하며, SAN과 DAS 인프라스트럭처를 단일한 공유 가속화 스토리지 풀로 통합하는 것입니다.
통합할 때는 성능 집적도가 중요합니다. 이 부분에서 퓨어스토리지의 올 NVMe 다이렉트플래시 아키텍처가 진정으로 빛을 발합니다. 경쟁업체들은 15TB와 30TB SAS SSD를 제공합니다. 이들은 성능에 영향을 미치기 때문에, 단일한 30TB SSD를 구현하느니 2TB SSD 15개를 개조 어레이에 구현하는 것이 훨씬 낫습니다. 그러나 이 경우, 물론 집적도를 희생해야 됩니다. 다이렉트플래시는 두 가지 세계의 장점만을 제공합니다. 성능에 전혀 영향을 미치지 않고 18.3TB 다이렉트플래시 모듈의 궁극적인 집적도를 제공합니다. 모든 크기의 다이렉트플래시 모듈 단 10개로부터 어레이의 최고 속도를 이끌어 낼 수 있습니다.
백문이 불여일견입니다. 레거시 레트로핏 아키텍처와 비교해 다이렉트플래시가 제공하는 집적도와 통합 가치를 직접 확인해보십시오.
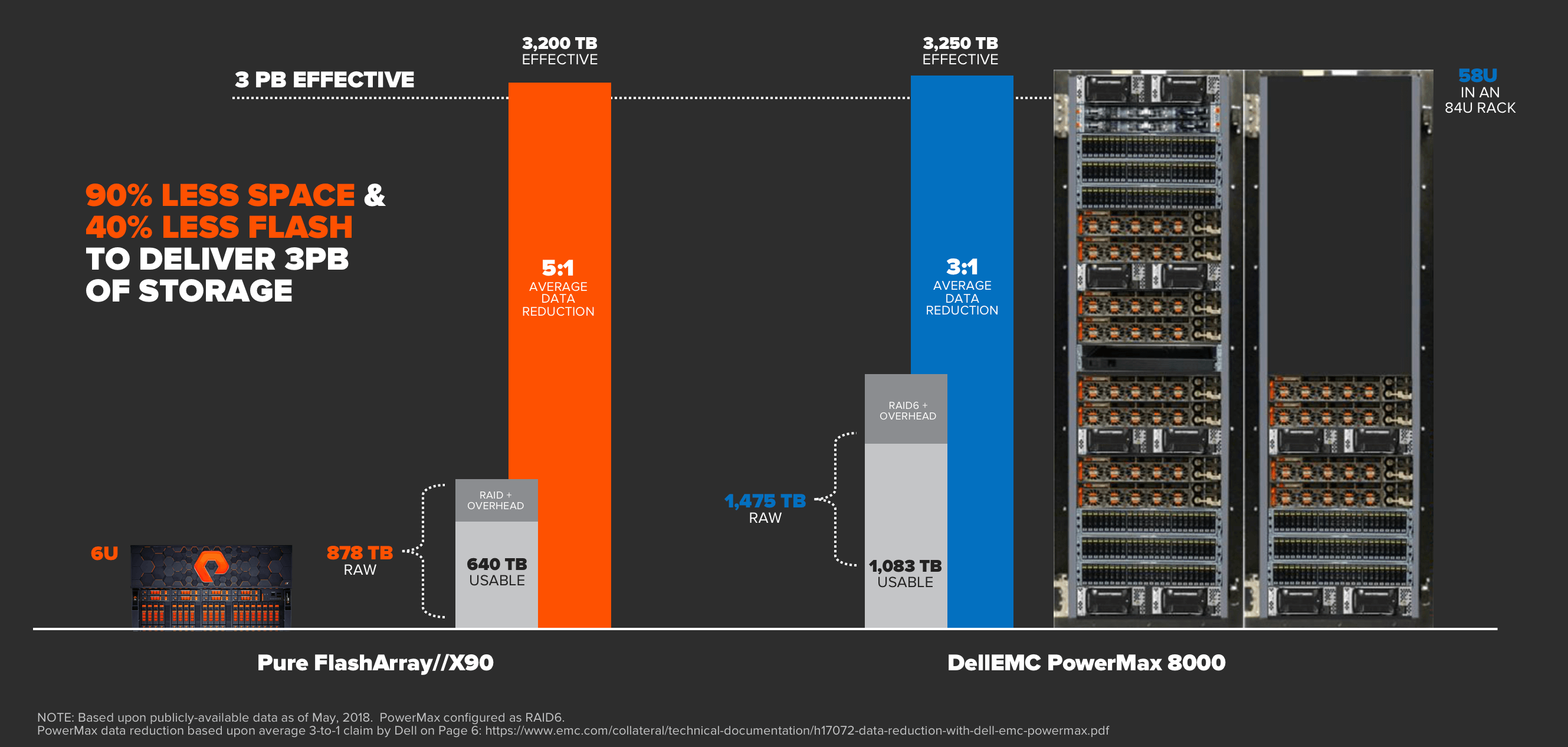
3PB 구현을 비교하자면, 플래시어레이//X(FlashArray//X)는 단 3U에서 3PB를 제공할 수 있습니다. 한 경쟁업체의 개조 아키텍처는 랙 1.5개 또는 58U를 가져야 이러한 유효용량에 대적할 수 있습니다. 공간 절감은 물론 관련된 전력, 냉방 비용의 절감까지, 그 차이는 정말 엄청납니다.
그렇다면 비용이 얼마나 들까요?
앞에서 언급한 것처럼, 퓨어스토리지의 비전은 공유 가속화 스토리지를 주류에 편입시키는 것입니다. 실제로 올 NVMe 스토리지에 대한 초기 시도는 올플래시 어레이 보다 최대 10배는 비용이 더 들었기 때문에 실패할 수 밖에 없었습니다. 지난 몇 개월 동안, 몇몇 공급업체들이 하이엔드 포트폴리오에 새로운 제품을 도입했지만, 비용의 측면에서는 이상하게도 아무런 언급이 없습니다.
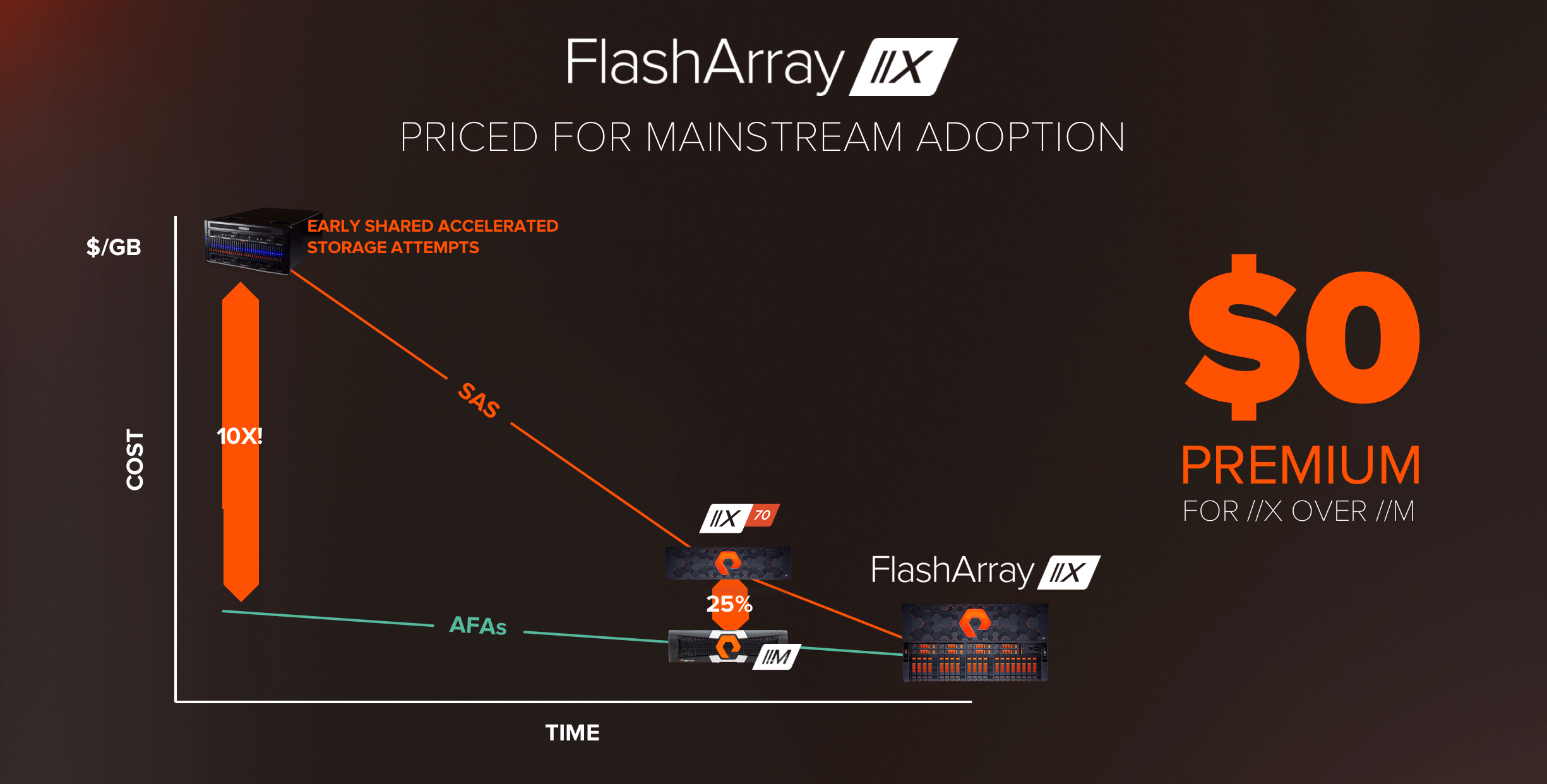
지난해, 퓨어스토리지가 출시한 플래시어레이//X(FlashArray//X)는 //M 가격에 프리미엄이 25% 붙었습니다. 2017년이었다는 점에서 보면 대단한 위업라고 할 수 있습니다. 듀얼 포트 NVMe SSD가 SAS SSD보다 2배 정도 비싸다는 점을 감안하면, 퓨어스토리의 다이렉트플래시 아키텍처가 얼마나 가치가 있는지를 알 수 있습니다. 지금은 2018년입니다. 말씀 드렸듯이, 퓨어스토리지는 올인할 예정입니다. 모든 //X는 유효용량 기준으로 프리미엄 없이, //M과 동일한 가격으로 제공됩니다. 올 NVMe 공유 가속화 스토리지로 이동하는 것은 생각할 필요도 없이 쉽게 결정할 수 있는 문제입니다.*
질문이 있으실 겁니다. “어떻게 그걸 할 수 있지요?” 쉽습니다. 다이렉트플래시 스토리지와 다이렉트플래시 소프트웨어를 제공하는 것은 퓨어스토리지뿐입니다. 다이렉트플래시는 원시 NAND를 활용할 수 있도록 해주고, NVMe의 진정한 잠재력을 제공해줍니다. 개조하는 경쟁업체들은 고가의 듀얼 포트 NVMe 드라이브를 활용해야만 합니다. 퓨어스토리지는 소프트웨어에서 NAND까지 최적화를 하기 위해 많은 노력을 기울였습니다. 덕분에, 공유 가속화 스토리지를 주류 스토리지 가격으로 제공할 수 있습니다.
아키텍처를 한단계 진보시킬 시간입니다.
여기까지 설명을 드렸습니다. 올 뉴 플래시어레이//X(FlashArray//X) 제품군은 모든 워크로드에 올 NVMe 성능을 제공하도록 설계되었습니다. 플래시어레이//X(FlashArray//X)는 기존 SAN와 차세대 웹 스케일 DAS 워크로드를 통합하고 운영 환경의 성능과 효율성을 대폭 향상하여 궁극적으로 진정한 데이터 중심의 아키텍처로 이동할 수 있도록 해줍니다. 그러한 고객들의 여정을 지원할 수 있게 될기를 기대합니다!
올해의 Pure//Accelerate에서 발표될 내용에 대한 자세한 정보는 전체 출시 블로그인 디지털 비지니스를 지원하는 데이터 센트릭 아키텍처(Data Centric Architecture Powers Digital Business)를 확인하십시오.
*$0 프리미엄은 전체 //X 제품군의 평균이며, 실제 //M vs. //X 가격은 SKU와 특정 용량 설정에 따라 약간씩 차이가 날 수 있습니다. 자세한 가격 정보는 퓨어스토리지 담당자나 파트너에게 문의해주십시오.



