

Resumen
This article shows how to seed a database from a SQL instance that is in a Windows availability group into a SQL instance running in a pod in a Kubernetes cluster using a distributed availability group.


Este artículo sobre los grupos de disponibilidad distribuida de SQL Server apareció originalmente en el blog de Andrew Pruski. Se ha vuelto a publicar con el crédito y consentimiento del autor.
Hace un tiempo, escribí sobre cómo usar un grupo de disponibilidad multiplataforma (o sin clúster) para sembrar una base de datos de una instancia de Windows SQL en un pod en Kubernetes.
Estaba hablando con un colega la semana pasada y me preguntaron: “¿Qué sucedería si la instancia existente de Windows ya estuviera en un grupo de disponibilidad?”.
Esta es una pregunta justa, ya que es bastante raro (en mi experiencia) ejecutar una instancia de SQL independiente en producción… la mayoría de las instancias se encuentran en alguna forma de configuración de HA, ya sea una instancia de clúster de conmutación por error o un grupo de disponibilidad.
Las instancias de clúster de conmutación por error funcionarán con un grupo de disponibilidad sin clúster, pero es una historia diferente cuando se trata de grupos de disponibilidad existentes.
No se puede agregar un nodo Linux a un grupo de disponibilidad existente de Windows (confíe en mí, intenté más tiempo del que admitiré), por lo que la única forma de hacerlo es usar un grupo de disponibilidad distribuida.
¡Así que repasemos el proceso!
Este es el grupo de disponibilidad existente de Windows:
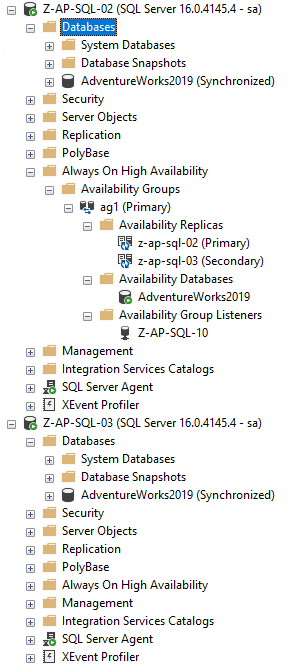
Solo un AG estándar de dos nodos con una base de datos ya sincronizada entre los nodos. Es esa base de datos que vamos a sembrar en el pod que se ejecuta en el clúster de Kubernetes usando un grupo de disponibilidad distribuida.
Este es el clúster de Kubernetes:
nodos kubectl get
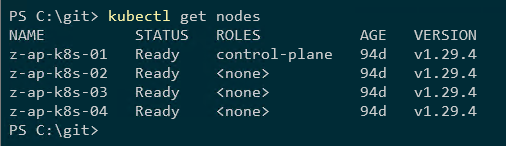
Cuatro nodos, un nodo de plano de control y tres nodos de trabajadores.
Bien, lo primero que debe hacer es implementar un conjunto de estados que ejecute un pod de SQL Server (usando un archivo llamado sqlserver-statefulset.yaml):
kubectl apply -f .\sqlserver-statefulset.yaml
Este es el manifiesto del conjunto de estados:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465
apiVersión: aplicaciones/v1kind: StatefulSetmetadata: name: mssql-statefulsetspec: serviceName: "mssql" replicas: 1 podManagementPolítica: Selector paralelo: matchEtiquetas: nombre: plantilla mssql-pod:metadatos: etiquetas: nombre: anotaciones de mssql-pod:stork.libopenstorage.org/disableHyperconvergence: especificaciones "verdaderas": securityContext: fsGroup: 10001 hostAlias: - ip: "10.225.115.129" nombres de host: - contenedores "z-ap-sql-10": - nombre: imagen del contenedor mssql: mcr.microsoft.com/mssql/server:2022-CU15-ubuntu-20.04puertos: - containerPort: Nombre de 1433: mssql-port env: - nombre: MSSQL_PID value: "Desarrollador" - nombre: ACCEPT_EULA value: "Y" - nombre: MSSQL_AGENT_ENABLED value: "1" - nombre: MSSQL_ENABLE_HADR value: "1" - nombre: MSSQL_SA_PASSWORD value: "Pruebas1122" volumeMounts: - name: sqlsystem mountPath: /var/opt/mssql - name: sqldata mountPath: /var/opt/sqlserver/data volumeClaimTemplates: - metadatos: name: sqlsystem spec: accessModes: - ReadWriteOnce resources: requests: storage: 1GistorageClassName: mssql-sc - metadatos: name: sqldata spec: accessModes: - ReadWriteOnce Recursos: solicitudes: almacenamiento: 25GistorageClassName: mssql-sc
Al igual que en mi última publicación, esto está bastante despojado. Sin límites de recursos, tolerancias, etc. Tiene dos volúmenes persistentes: uno para las bases de datos del sistema y otro para las bases de datos de usuarios de una clase de almacenamiento ya configurada en el clúster.
Una cosa a tener en cuenta:
1234 hostAlias:- ip: "10.225.115.129" nombres de host: - "z-ap-sql-10"
Aquí, se está creando una entrada en el archivo hosts del pod para el oyente del grupo de disponibilidad de Windows.
Lo siguiente que debe hacer es implementar dos servicios: uno para que podamos conectarnos a la instancia SQL (en el puerto 1433) y uno para el AG (puerto 5022):
kubectl apply -f .\sqlserver-services.yaml
Este es el manifiesto de los servicios:
12345678910111213141516171819202122232425 apiVersión: v1kind: Servicemetadata: name: mssql-servicespec: puertos: - name: mssql-ports port: 1433 targetPort: 1433 selector: name: mssql-pod type: LoadBalancer---apiVersión: v1kind: Servicemetadata: name: mssql-ha-servicespec: puertos: - name: mssql-ha-ports port: 5022 targetPort: 5022 selector: name: mssql-pod type: LoadBalancer
Nota: Podríamos usar solo un servicio con varios puertos configurados, pero los mantengo separados aquí para intentar mantener las cosas lo más claras posible.
Uso de la copia de seguridad de snapshots T-SQL: Recuperación en un momento determinado
Verifique que todo se vea bien:
kubectl obtenga todo
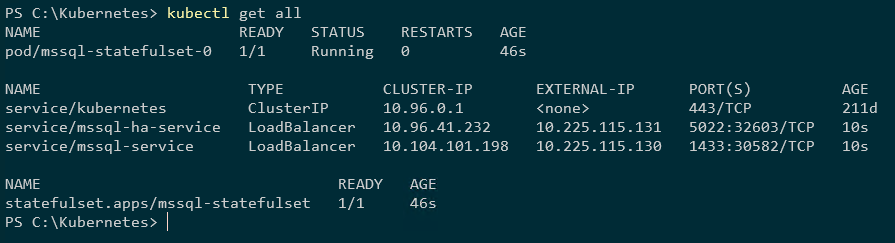
Ahora, debemos crear la clave maestra, el inicio de sesión y el usuario en todos los casos:
123 CREAR LA ENCRYPCIÓN CLAVE MAESTRA POR CONTRASEÑA = '
Luego, cree un certificado en la instancia SQL en el pod:
CREAR CERTIFICADO dbm_certificate CON ASUNTO = 'Mirroring_certificate', EXPIRY_DATE = '20301031'
Realice una copia de seguridad de ese certificado:
123456 CERTIFICADO DE RESPALDO dbm_certificatePARA ARCHIVO = '/var/opt/mssql/data/dbm_certificate.cer'CON CLAVE PRIVADA ( ARCHIVO = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION POR CONTRASEÑA = '
Copie el certificado localmente:
12 kubectl cp mssql-statefulset-0:var/opt/mssql/data/dbm_certificate.cer ./dbm_certificate.cer -n prodkubectl cp mssql-statefulset-0:var/opt/mssql/data/dbm_certificate.pvk ./dbm_certificate.pvk -n prod
Y luego copie los archivos a las casillas de Windows:
1234 Copy-Item dbm_certificate.cer \\z-ap-sql-02\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.pvk \\z-ap-sql-02\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.cer \\z-ap-sql-03\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.pvk \\z-ap-sql-03\E$\SQLBackup1\ -Force
Una vez que los archivos están en los cuadros de Windows, podemos crear el certificado en cada instancia de Windows SQL:
1234567 CREAR CERTIFICADO DE dbm_certificate AUTORIZACIÓN dbm_user DESDE EL ARCHIVO = 'E:\SQLBackup1\dbm_certificate.cer' CON CLAVE PRIVADA (ARCHIVO = 'E:\SQLBackup1\dbm_certificate.pvk', DECRYPTION POR CONTRASEÑA = '')
Bien, ¡excelente! Ahora necesitamos crear un punto final en espejo en la instancia SQL en el pod:
123456789101112 CREAR [Hadr_endpoint]ESTADO DE PUNTO FINAL = INICIADOCOMO TCP ( LISTENER_PORT = 5022, LISTENER_IP = TODOS)PARA DATA_MIRRORING ( ROL = TODOS, AUTENTICACIÓN = CERTIFICADO DE WINDOWS [dbm_certificate], CIFRADO = ALGORITMO REQUERIDO AES );ALTERAR [Hadr_endpoint] ESTADO DE PUNTO FINAL = INICIADO;OTORGAR CONEXIÓN EN EL PUNTO FINAL::[Hadr_endpoint] A [dbm_login];
Ya hay puntos finales en las instancias de Windows, pero necesitamos actualizarlos para usar el certificado para la autenticación:
12345678910 ALTER ENDPOINT [Hadr_endpoint]STATE = STARTEDAS TCP ( LISTENER_PORT = 5022, LISTENER_IP = = ALL)PARA DATABASE_MIRRORING ( AUTENTICACIÓN = CERTIFICADO DE WINDOWS[dbm_certificate], CIFRADO = ALGORITMO REQUERIDO AES );GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] A [dbm_login];
Ahora, podemos crear un grupo de disponibilidad sin clúster de un nodo en la instancia de SQL en el pod:
12345678910111213 CREE UN GRUPO DE [AG2]DISPONIBILIDADCON (CLUSTER_TYPE=NONE) FORREPLICA ON'mssql-statefulset-0' WITH ( ENDPOINT_URL = 'TCP://mssql-statefulset-0.com:5022', FAILOVER_MODE MANUAL ,AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ,BACKUP_PRIORITY = 50 ,SEEDING_MODE = AUTOMATIC ,SECONDARY_ROLE(ALLOW_CONNECTIONS = = NO) )
No hay oyente aquí; vamos a usar el servicio mssql-ha como punto final para el grupo de disponibilidad distribuida.
Bien, en el nodo principal del grupo de disponibilidad de Windows, podemos crear el grupo de disponibilidad distribuida:
1234567891011121314151617 CREE UN GRUPO DE DISPONIBILIDAD [DistributedAG]CON (DISTRIBUIDO) GRUPO DE DISPONIBILIDAD EN 'AG1' CON ( LISTENER_URL = 'tcp://Z-AP-SQL-10:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = = AUTOMÁTICO ), 'AG2' CON ( LISTENER_URL = 'tcp://10.225.115.131:5022', AVAILABILITY_MODE ASYNCHRONOUS_COMMIT, FAILOVER_MODE = = MANUAL, SEEDING_MODE = = AUTOMÁTICO );
Podríamos usar una entrada de archivo de host para la URL en AG2 (lo hice en la publicación anterior), pero aquí solo usaremos la dirección IP del servicio mssql-ha.
Bien, ¡casi allí! Ahora tenemos que unirnos al grupo de disponibilidad en la instancia SQL en el pod:
1234567891011121314151617 ALTER AVAILABILITY GROUP SE [DistributedAG]UNE A AVAILABILITY GROUP ON'AG1' WITH ( LISTENER_URL = 'tcp://Z-AP-SQL-10:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = = AUTOMÁTICO ), 'AG2' WITH ( LISTENER_URL = 'tcp://10.225.115.131:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = = AUTOMÁTICO );
¡Y eso debería ser todo! Si ahora nos conectamos a la instancia de SQL en el pod, ¡la base de datos está allí!
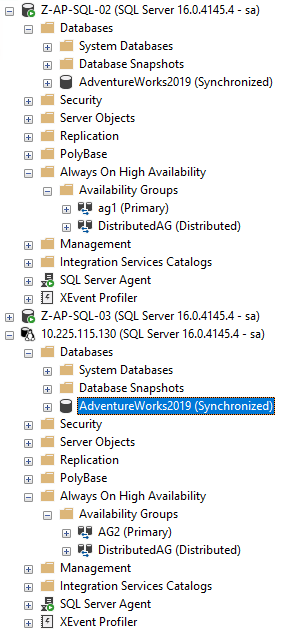
¡Ahí está! Bien, una cosa que no he analizado aquí es cómo hacer que la autoseminación funcione desde Windows a una instancia de Linux SQL. Repasé cómo funciona eso en mi publicación anterior, pero el punto de referencia es que, siempre que los datos de la base de datos y los archivos de registro se encuentren debajo de la ruta de datos y registros predeterminada de la instancia de SQL de Windows, se colocarán automáticamente en las rutas de datos y registros predeterminadas de la instancia de SQL de Linux.
Así es como se puede sembrar una base de datos desde una instancia de SQL que está en un grupo de disponibilidad de Windows en una instancia de SQL que se ejecuta en un pod en un clúster de Kubernetes usando un grupo de disponibilidad distribuida.

Stellar Storage
Boost performance for SQL Server with Pure Storage.



