


Every vendor is going to offer an option to non-disruptively transition your workload from the current storage array to the next. Generally this will involve some form of data migration driven from the host. Virtualized environments have it a bit easier than most, as virtualized environments will offer some form of non-disruptive storage migration feature in the hypervisor. Other host-based options are logical volume managers, application mirroring, etc. Many vendors recommend these copy-based migration technologies, as they enable their non-disruptive transition capabilities.
At Pure Storage we do non-disruptive upgrades (NDU) all the time. It’s a matter of convenience. Why should I stop a workload if I don’t have to? What if I want to test a new Purity feature on my colleague’s array but he’s got a workload running and I can’t get ahold of him? What if I don’t even know who’s using the array?
NDU to the rescue.
Host-Based Data Migration Enabled Non-Disruptive Upgrades
Many NDU techniques will use data migration. Host-based non-disruptive data migration has been a lifesaver for many storage admins, and many storage vendors. But let’s think a bit wider here.
Your existing storage system is consuming resources. It’s consuming power, it’s using rack space, it’s occupying switch ports on the SAN and the network, and it’s consuming your time.
Host-based methods can take weeks or months, especially in mixed environments where migration of critical legacy applications can stretch the duration of a project well beyond what was planned. While all that data migration is going on you might experience some performance degradation, so you might try to plan the migrations during less busy times. You’ll need to leave your existing storage online for the duration of this transition project so you need more rack space, more power, more SAN and LAN switch ports. You’ll need to configure that new array and the infrastructure, creating new zones and VLANs, provisioning new LUNs, mapping them to the hosts, applying best practice settings, etc.
Non-Disruptive Upgrades at Pure Storage
As I mentioned earlier at Pure Storage we NDU our arrays all the time. I’ve sent more than one “FYI, I upgraded that array earlier,” emails to my colleagues, usually without much complaining. The saying “It’s better to ask for forgiveness than permission” comes to mind.
More often than not these are, of course, just software upgrades. But what do I do when I’ve got a Pure Storage array that’s become overloaded with workload, I’ve got a shiny new array to replace it, but I don’t really want to shut anything down because that would just be harder?
It would be more work to go find everyone who’s using the array, shut down all their workloads, disconnect their hosts, upgrade the hardware, and reconnect their hosts than just change arrays on the fly.
NDU to the rescue again.
If whoever is using the array doesn’t notice better latency and higher throughput, then I won’t even have to ask for forgiveness.
Compared to the migration based NDU method we’ve had to deal with in the past, the Pure Storage NDU process is simply some multipath failover and path recovery events for the hosts. The value in terms of efficiency and use of resources this returns to large organizations with many arrays to manage is immeasurable.

How Pure Storage Non-Disruptive Upgrades Work
So, how does a Pure Storage non-disruptive hardware upgrade work?
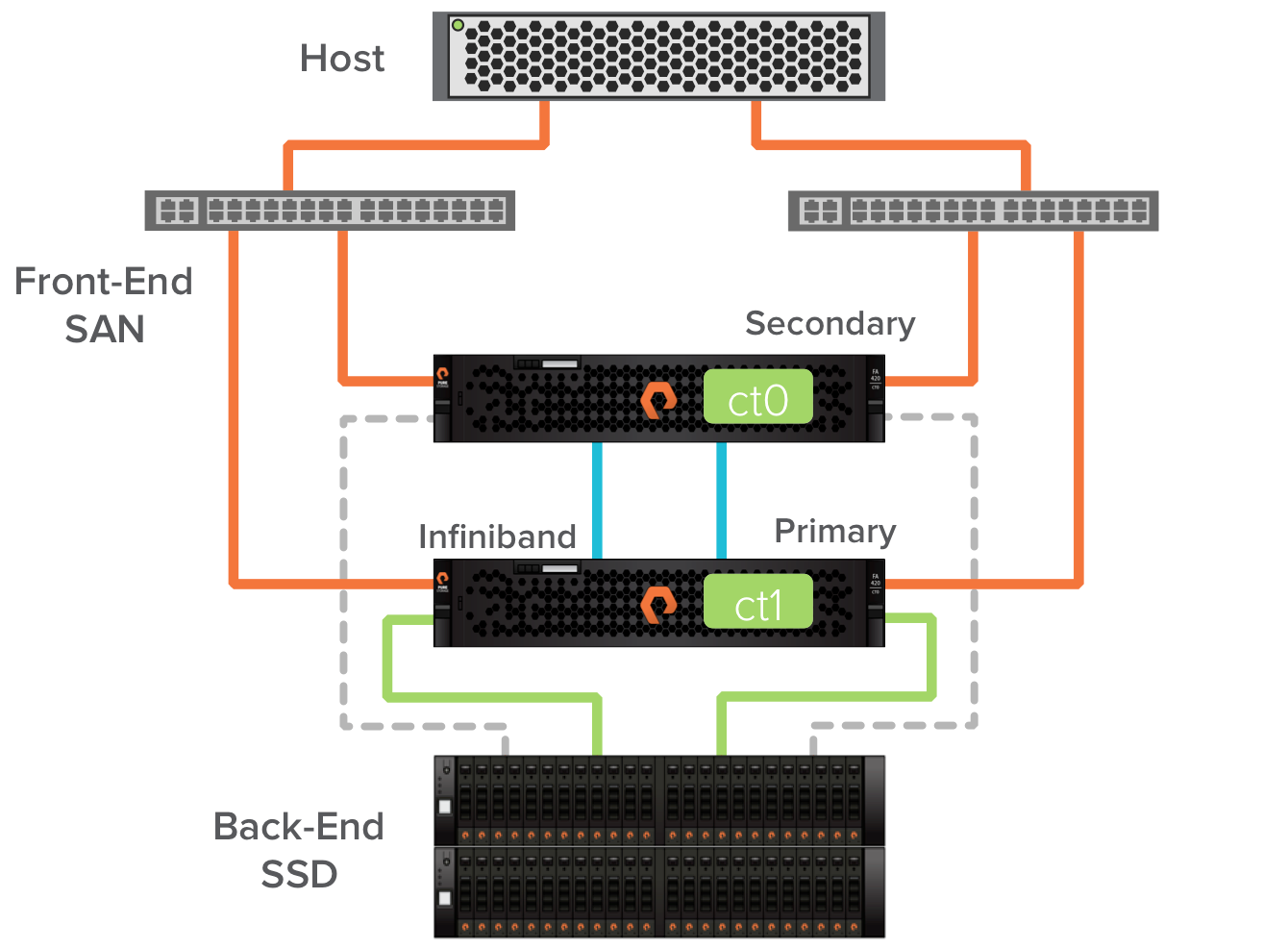
Every Pure Storage FlashArray is active/active on the front-end SAN, and active-passive on the back-end where the SSDs are connected. In the images below, the solid colored lines represent active online paths. The dashed grey lines represent passive paths (in a couple cases paths that are off temporarily). All four of the front-end paths are servicing IO from the host and we recommend a round-robin multipathing policy to use all paths equally. Controller ct0’s connections to the SSD are currently passive (we call this being secondary), and controller ct1’s connections to the SSD are active (we call this being primary). This active/passive back-end behavior is what allows us to maintain performance through upgrades.
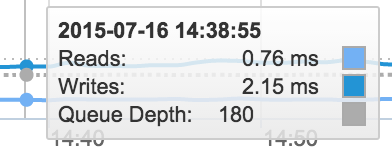
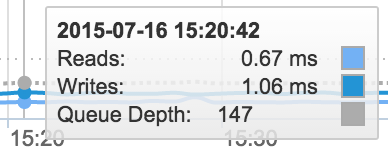
Before starting the upgrade, let’s take a look at performance using one of the simplest metrics we can measure, latency. I’ve let too many colleagues pile workloads onto my FA-405. Write latency is hurting a bit at 2ms.
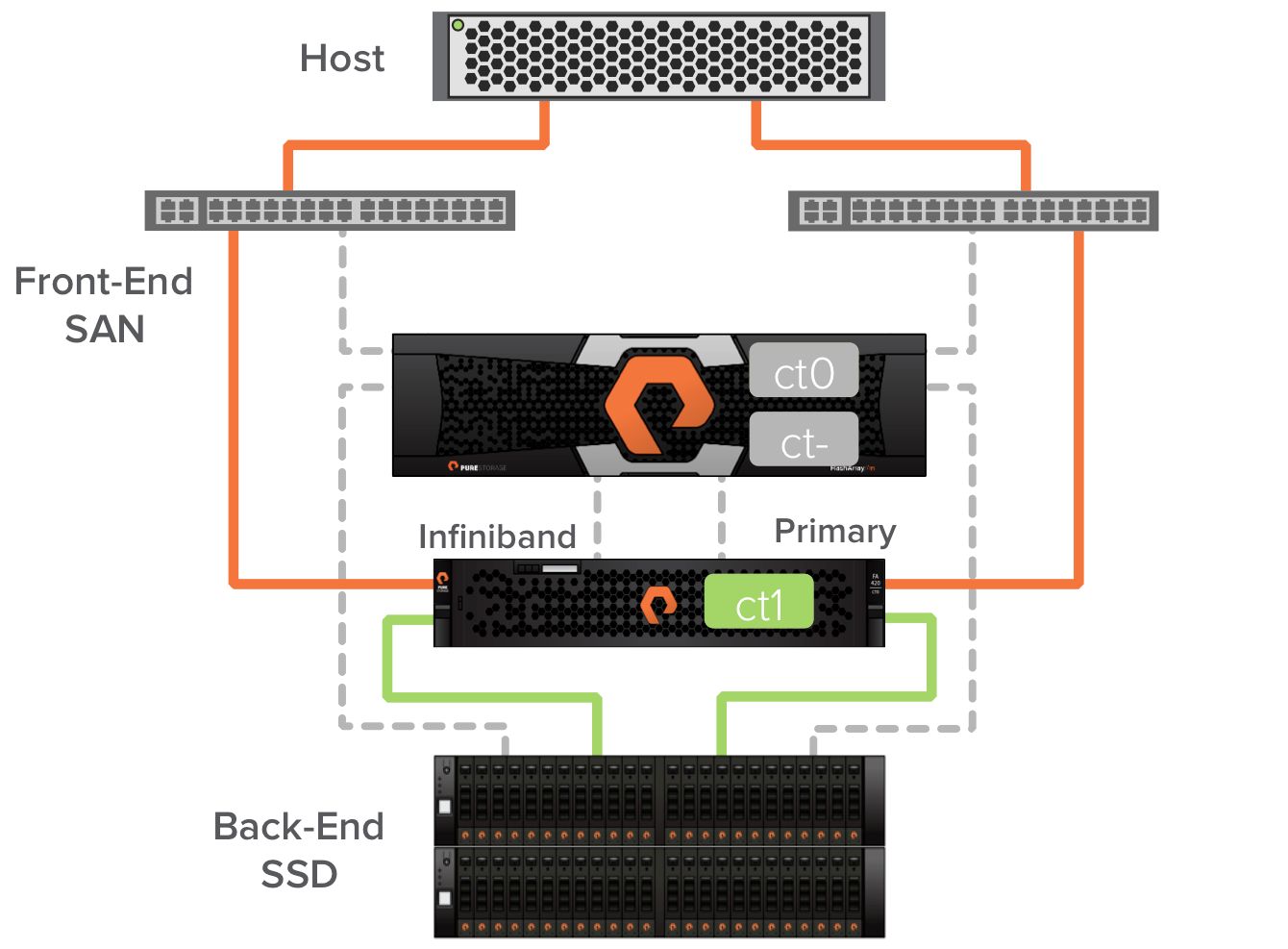
The first part of the non-disruptive hardware upgrade involves removing the secondary controller and replacing it with the controller in the Pure Storage FlashArray//m chassis. When the Pure Storage FA-400 controller is removed the connected hosts will experience path failures for the affected paths. The multipath software in the host allows them to survive these events.
As I mentioned before I don’t want to take the time to go meet with all the colleagues that I allow to use my array and check that they’ve properly setup multipath software in their hosts. Luckily, I can do this from the array using a tool we call IO balance. This command will show you if there are hosts that are not equally using all the front-end paths on the array, indicating that the host might have misconfigured multipath software. I use this tool before every multipath path failure event to ensure there will be no disruptions.
Next ct0 in the Pure Storage FlashArray//m chassis is brought online to replace the FA-400 controller. The FlashArray//m controller ct0 becomes secondary for the FA-400 controller ct1. At this point the host paths are restored. We now have an array that is one FA-400 controller and one FlashArray//m controller. This is enabled by external Infiniband connectivity between the FlashArray//m ct0 and FA-400 ct1.
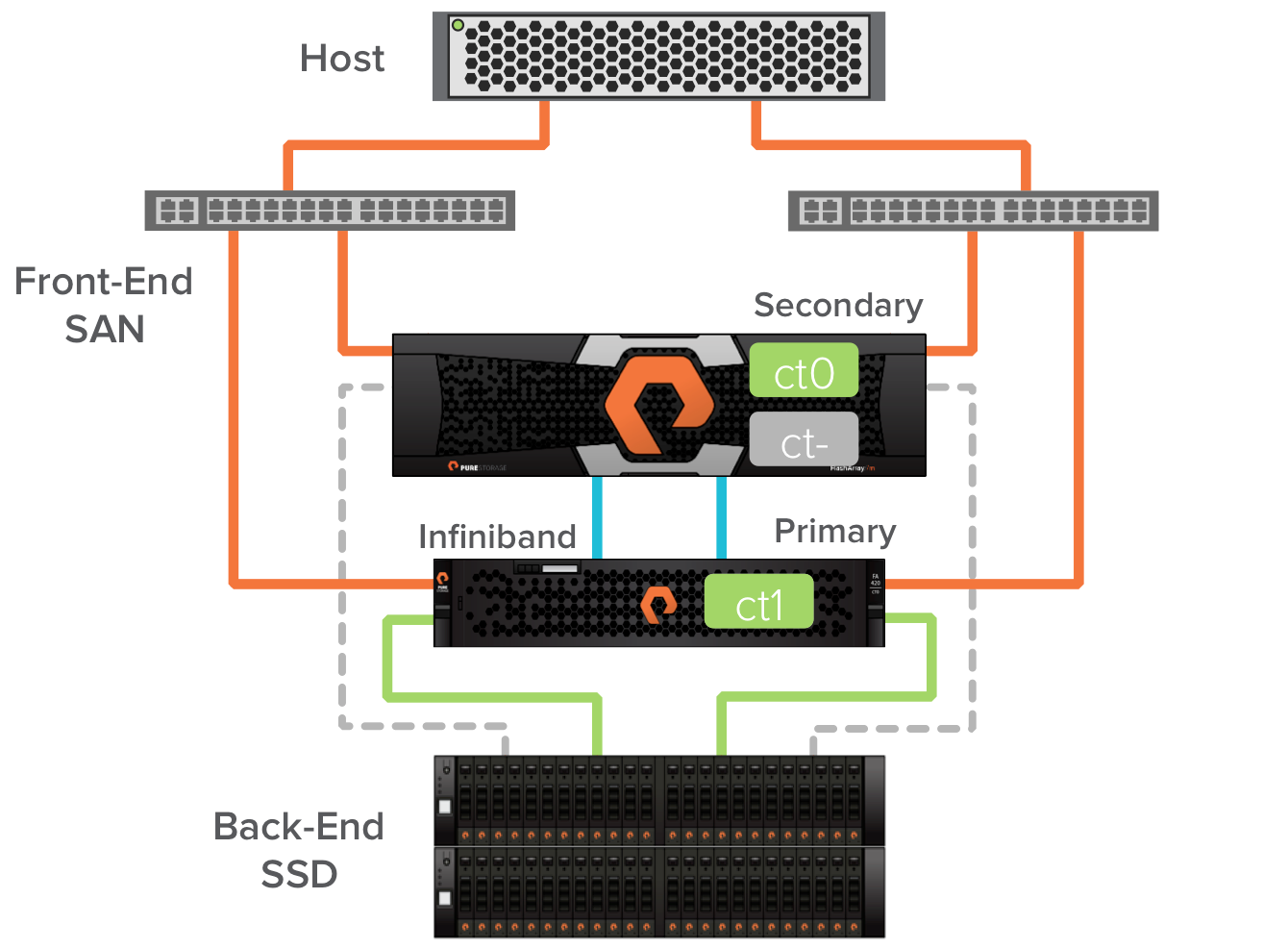
A quick internal failover of the backend path to the SSDs makes the Pure Storage FlashArray//m ct0 the primary.
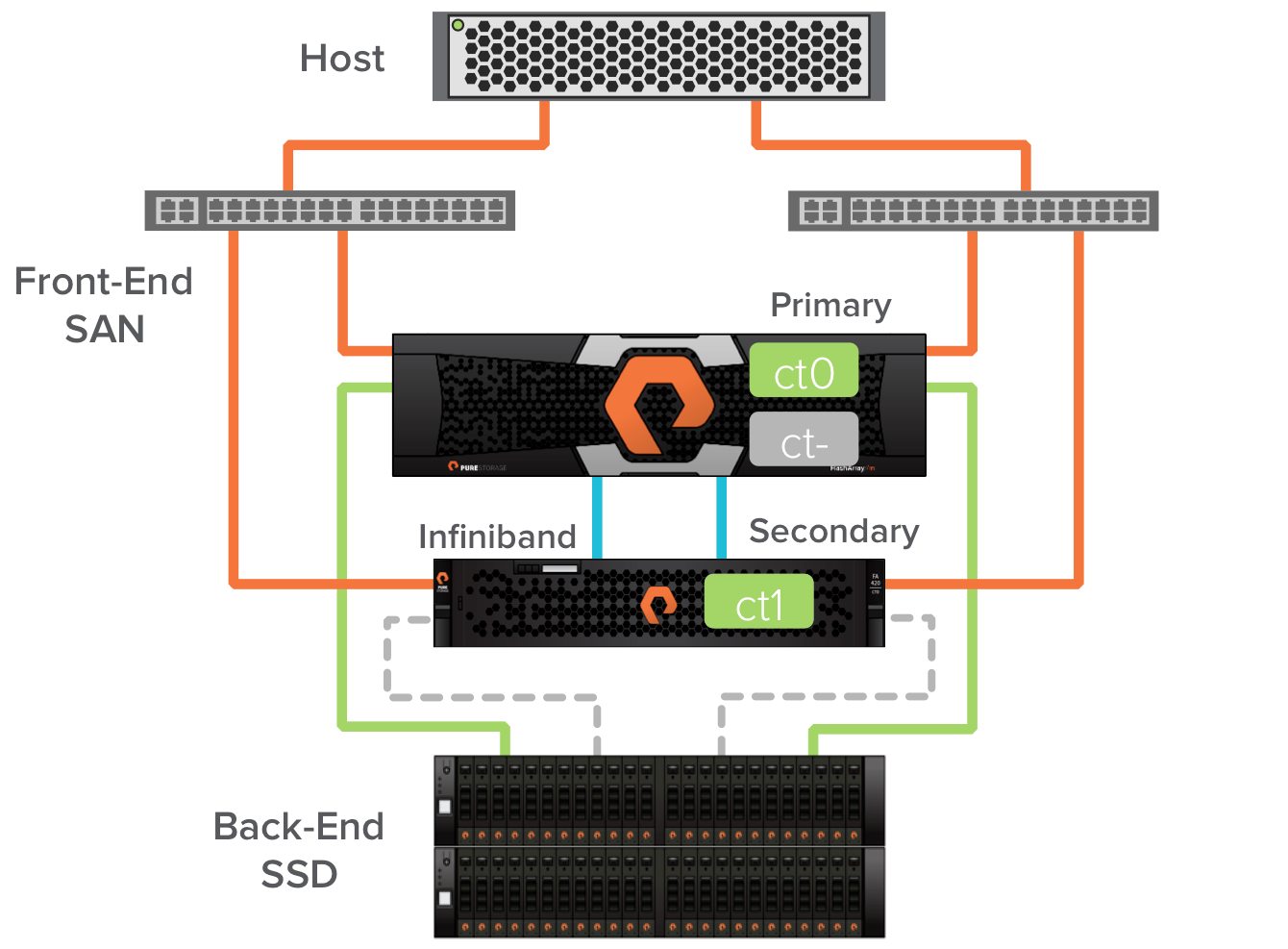
In this case I was upgrading to a FlashArray//m20. We support non-disruptive upgrades between platforms and from any of our previous platforms to the new FlashArray//m. With that extra power I’m already seeing better latency in the environment.
With the FA-400 ct1 in secondary mode I can now remove it from the array and cable in ct1 from the FlashArray//m chassis. I check the hosts with IO balance again as at this point the hosts will again experience path failures.
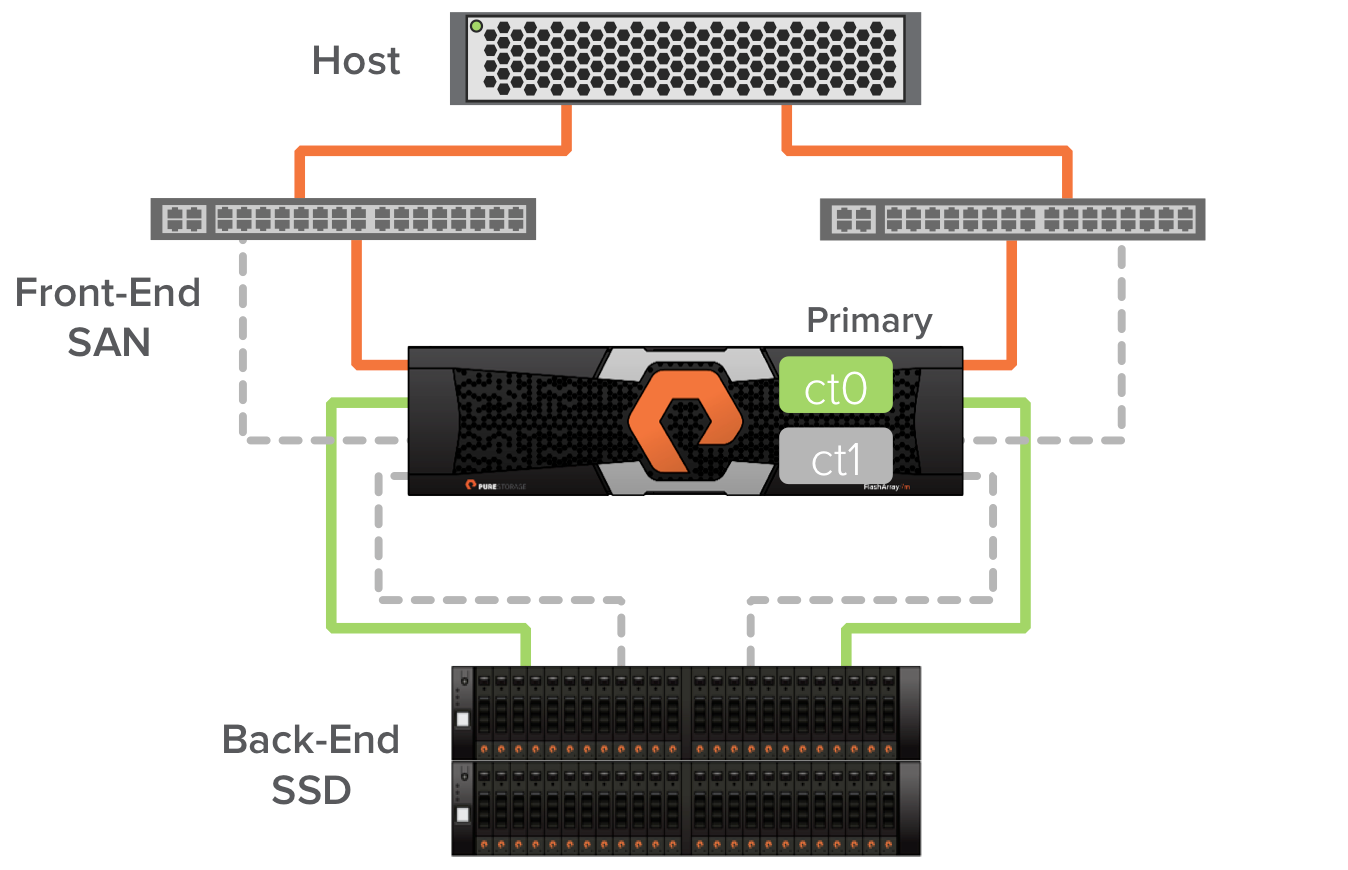
With the cabling done I can bring the FlashArray//m ct1 online and I now have a complete FlashArray//m with all paths to the host live. The FlashArray//m allows ct0 and ct1 to communicate directly over a high speed low latency PCIE NTB interconnect in the chassis.
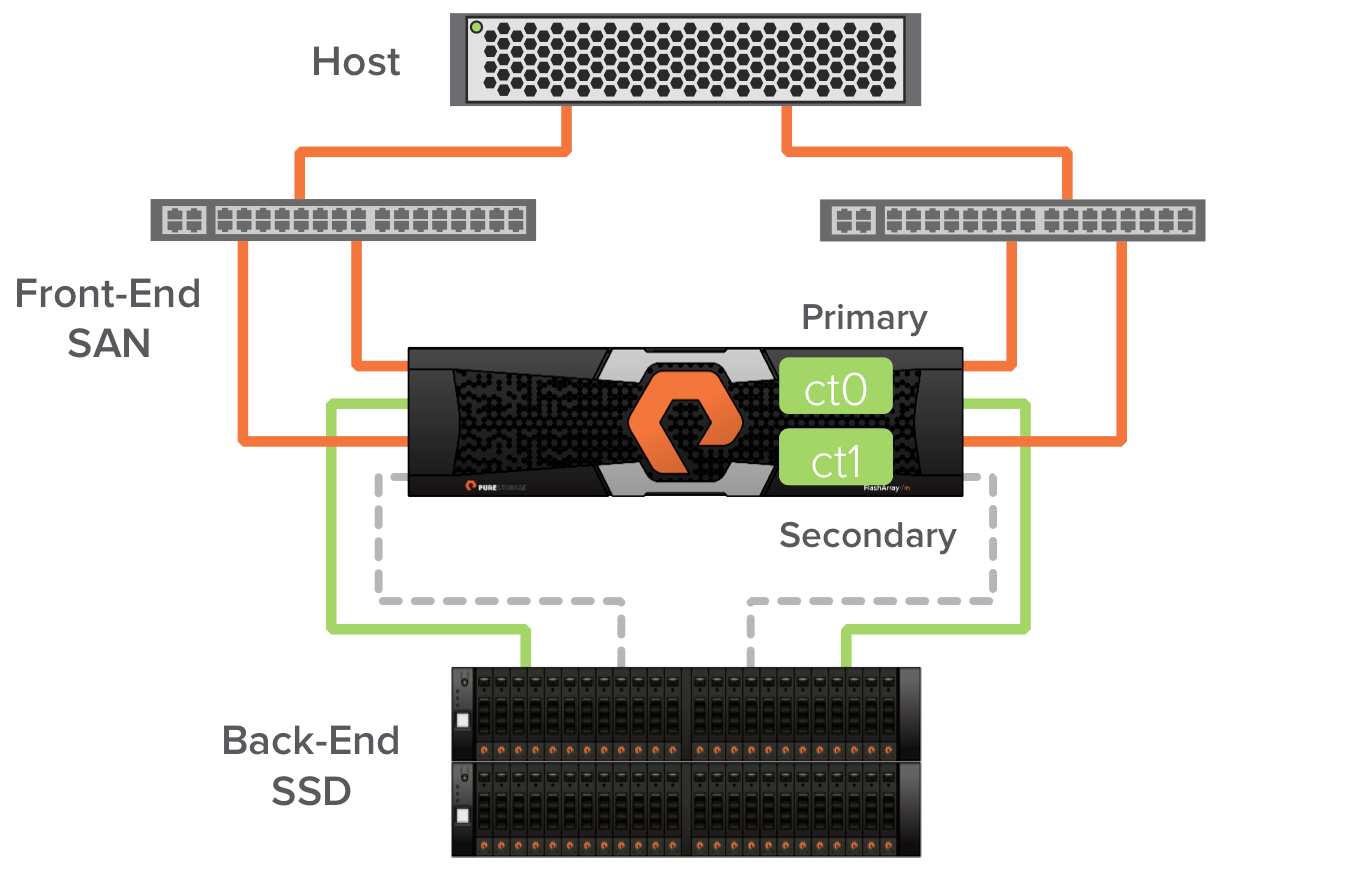
The Pure Storage FlashArray//m contains some new technology that enables greater performance. One of these is the new NVRAM modules. These are DDR3 memory based devices where the Pure Storage operating system protects incoming writes before acknowledging the writes to the host. The final step in transitioning from a FA-400 array to the FlashArray//m is to transition the NVRAM function from the shelf based NVRAM devices to the new DDR3 NVRAM devices in the chassis. Once this happens we see even more improvement in write latency.
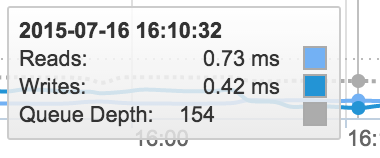
If my colleagues don’t notice the performance increase after a couple path failure events, then maybe they’ll just think I rebooted a switch or something. Maybe they’ll notice the increase in capacity when I remove the NVRAM devices from the shelves and replace them with SSDs, or when I install the new dual SSDs flash modules in the chassis. Overall they shouldn’t have anything to complain about.
A Better Non-Disruptive Upgrade
One thing I didn’t mention about performing non-disruptive upgrades with Pure Storage is that they are fun to do. I don’t mean to imply that it’s easy. We’ve got trained professionals who do this for our customers. It involves a documented process that helps to ensure it will be successful and won’t cause a disruption. It’s such a paradigm shift in the way of thinking: that upgrading hardware to get better performance is easier to do without shutting anything down. It forces one to consider what a vendor really means when they say they can non-disruptively transition you between their platforms.
In the future my next hardware upgrade will be even easier. I can upgrade from the Pure Storage FlashArray//m20 to a FlashArray//m50 or FlashArray//m70 by simply replacing the controllers in the chassis with the same process described above, but I wont have to un-rack or re-rack anything.
Burning valuable resources for long and complex migration projects has become a thing of the past. The future of enterprise storage is Evergreen.



