


AI, high-performance computing (HPC), and analytics workloads are growing exponentially in their data needs. It’s true whether you’re analyzing millions of videos to find deep fakes, parsing network logs to identify unauthorized intrusions, or analyzing huge quantities of small data files from millions of computers to create the next vaccine. That’s the case for Folding@home, a distributed computing project and research platform. The team at Pure learned of the storage challenges Folding@home was experiencing and jumped at the opportunity to help.
Adding to the data complexity is the need to manage many different types of data and access patterns all the way from metadata (data about the data) and small files to huge video and log data sets-—something traditional HPC storage architectures struggle with. Also consider that data has gravity and can take a lot of time to copy. For example, it would take more than two hours to copy a 10TB data set that is transferring at 10Gb/s. And that’s assuming ideal conditions and network saturation. It’s a delay that could really impact time to results. To reduce any impact on analysis times, try to minimize copying data as much as possible during the analysis phase.
The ability to handle high and increasing levels of concurrency is also of paramount and growing importance at the data layer. Complex problems are being solved with new algorithms and techniques that support ever-increasing amounts of concurrency and parallelism. With CPUs and GPUs providing higher numbers of cores with every generation, and with large data centers and cloud resources available almost instantly, storage systems need to be able to scale with increasing compute load and concurrency to keep compute processes fed with minimal wait for I/O.
We’ll be discussing these topics and more at SC20, a supercomputing conference happening virtually this year from November 9–19. We’ll showcase how Pure FlashBlade®, an all-flash file-and-object-based storage architecture, can scale performance linearly to enable efficient execution of all types of highly parallel workloads with different storage needs and access patterns. The figure below shows validation of the linear scalability of IOPS and bandwidth for a mixed I/O-type workload that you’d find in highly concurrent semiconductor-design environments.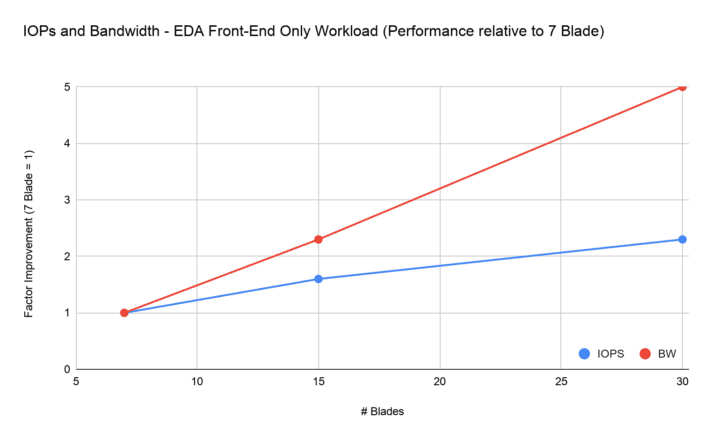
To learn more about performance scaling on FlashBlade, we look forward to seeing you virtually at our session “Flexing Muscles with Flash for Megascale HPC Metadata Workloads.”



