Samenvatting
Storage is the backbone of AI, but as model complexity and data intensity increase, traditional storage systems can’t keep pace. Agile, high-performance storage platforms are critical to support AI’s unique and evolving demands.


In de race naar artificiële algemene intelligentie (AGI) zet opslagtechnologie het tempo op. Terwijl algoritmen en compute de schijnwerpers zetten, is opslag de drijvende kracht achter AI-doorbraken. Tijdens de flashrevolutie stagneerden 15K-schijven als rekenprestaties om de twee jaar, maar flash-enabled virtualisatie en, vandaag de dag, GPU-gedreven workloads stimuleren verdere opslaginnovatie naast de eisen aan efficiëntie, duurzaamheid en betrouwbaarheid.
Vroege AI-inspanningen werden beperkt door algoritmische complexiteit en dataschaarste, maar naarmate algoritmen zich ontwikkelden, ontstonden er geheugen- en opslagknelpunten. High-performance storage heeft doorbraken opgeleverd zoals ImageNet, dat visiemodellen aanwakkerde, en GPT-3, waarvoor petabytes aan opslag nodig waren. Met 400 miljoen terabytes aan data die dagelijks worden gegenereerd, moet opslag exabyte-scale workloads beheren met een latency van minder dan een milliseconde om AGI en quantum machine learning aan te drijven. Naarmate AI vorderde, stelde elke innovatiegolf nieuwe eisen aan opslag, waardoor de capaciteit, snelheid en schaalbaarheid werden verbeterd om tegemoet te komen aan steeds complexere modellen en grotere datasets.
- Klassiek machine learning (1980s-2015): Spraakherkenning en leermodellen onder toezicht brachten de groei van datasets van megabytes naar gigabytes, waardoor het ophalen en de organisatie van data steeds belangrijker werd.
- Deep learning-revolutie (2012-2017): Modellen zoals AlexNet en ResNet hebben de vraag naar opslag gedreven, terwijl Word2Vec en GloVe de natuurlijke taalverwerking hebben verbeterd en zijn overgestapt op snelle NVMe-opslag voor datasets op terabyte-schaal.
- Foundation-modellen (2018-heden): BERT introduceerde datasets op petabyte-schaal, waarbij GPT-3 en Llama 3 schaalbare systemen met lage latency zoals Meta’s Tectonic nodig hebben om biljoenen tokens te verwerken en een verwerkingscapaciteit van 7TB/s te behouden.
- Chinchilla schaalwetten (2022): Chinchilla benadrukte het groeien van datasets boven LLM-modelgrootte, waarbij parallelle-toegangsopslag nodig was om de prestaties te optimaliseren.
Storage ondersteunt niet alleen AI – het loopt voorop en geeft vorm aan de toekomst van innovatie door ’s werelds steeds groeiende data efficiënt en op schaal te beheren. AIAItoepassingen in autonoom rijden zijn bijvoorbeeld afhankelijk van opslagplatforms die petabytes aan sensorgegevens in realtime kunnen verwerken, terwijl genomicaonderzoek snelle toegang tot enorme datasets vereist om ontdekkingen te versnellen. Terwijl AI de grenzen van datamanagement blijft verleggen, worden traditionele opslagsystemen geconfronteerd met toenemende uitdagingen in overeenstemming met deze veranderende eisen, waardoor de noodzaak van speciaal gebouwde oplossingen wordt benadrukt.
Hoe AI-workloads traditionele opslagsystemen belasten
Dataconsolidatie en volumemanagement
AI-applicaties beheren datasets variërend van terabytes tot honderden petabytes, die de mogelijkheden van traditionele opslagsystemen zoals NAS, SAN en legacy direct-attached storage ver overtreffen. Deze systemen, ontworpen voor nauwkeurige, transactionele workloads zoals het genereren van rapporten of het ophalen van specifieke records, worstelen met de aggregatie-intensieve eisen van data science en de meeslepende, snelle toegangspatronen van AI/ML-workloads. Modeltraining, waarvoor massaal, batchgewijs dataherstel over gehele datasets nodig is, benadrukt deze verkeerde uitlijning. De starre architecturen, capaciteitsbeperkingen en onvoldoende verwerkingscapaciteit van traditionele infrastructuur maken het ongeschikt voor de schaal en snelheid van AI, waardoor de behoefte aan speciaal gebouwde opslagplatforms wordt onderstreept.
Prestatieknelpunten voor snelle datatoegang
Realtime analyses en besluitvorming zijn essentieel voor AI-workloads, maar traditionele opslagarchitecturen creëren vaak knelpunten met onvoldoende IOPS, omdat ze zijn gebouwd voor gematigde transactietaken in plaats van de intensieve, parallelle lees-/schrijfvereisten van AI. Bovendien vertraagt de hoge latency van draaiende schijven of verouderde cachingmechanismen de toegang tot data, waardoor de tijd tot inzicht toeneemt en de efficiëntie van AI-processen wordt verminderd.
Omgaan met diverse datatypes en workloads
AI-systemen verwerken zowel gestructureerde als ongestructureerde data, waaronder tekst, afbeeldingen, audio en video, maar traditionele opslagoplossingen worstelen met deze diversiteit. Ze zijn vaak geoptimaliseerd voor gestructureerde data, wat resulteert in langzaam ophalen en inefficiënte verwerking van ongestructureerde formaten. Bovendien maken slechte indexering en Metadata beheerhet moeilijk om diverse datasets effectief te organiseren en te doorzoeken. Traditionele systemen hebben ook te maken met prestatieproblemen met kleine bestanden, gebruikelijk in trainingstaalmodellen, omdat hoge Metadata-overhead leidt tot vertragingen en langere verwerkingstijden.
Beperkingen van legacy-architectuur
Het cumulatieve effect van deze uitdagingen is dat traditionele opslagarchitecturen de eisen van moderne AI-workloads niet kunnen bijbenen. Ze missen de flexibiliteit, prestaties en schaalbaarheid die nodig zijn om de diverse en grote datavereisten van AI te ondersteunen. Deze beperkingen benadrukken de noodzaak van geavanceerde opslagoplossingen die zijn ontworpen om de unieke uitdagingen van AI-toepassingen aan te kunnen, zoals snelle schaalbaarheid, hoge verwerkingscapaciteit, lage latency en diverse dataverwerking.
Belangrijkste opslaguitdagingen in AI
AI-workloads stellen unieke eisen aan opslagsystemen en het aanpakken van deze uitdagingen vereist geavanceerde mogelijkheden op de volgende gebieden:
- Unified dataconsolidatie: Datasilo’s versnipperen waardevolle informatie, waardoor consolidatie nodig is in een uniform platform dat diverse AI-workloads ondersteunt voor naadloze verwerking en training.
- Schaalbare prestaties en capaciteit: Een robuust opslagplatform moet diverse I/O-profielen beheren en schalen van terabytes tot exabytes, waardoor toegang met lage latency en hoge verwerkingscapaciteit wordt gegarandeerd. Door non-disruptieve schaalbaarheid mogelijk te maken, stelt het platform AI-workloads in staat om naadloos uit te breiden naarmate de vraag naar data toeneemt, met behoud van soepele, ononderbroken activiteiten.
- Flexibiliteit bij scale-up en scale-out: Het afhandelen van transactietoegang met lage latency voor vectordatabases en workloads met hoge concurrency voor training en inferentie vereist een platform dat beide mogelijkheden levert.
- Betrouwbaarheid en continue uptime: Naarmate AI cruciaal wordt voor ondernemingen, is 99,9999% uptime essentieel. Een opslagplatform moet non-disruptieve upgrades en hardwarevernieuwingen ondersteunen, waardoor continue activiteiten worden gegarandeerd zonder dat downtime zichtbaar is voor eindgebruikers.
Optimalisatie van opslag over de AIAIpijplijn
Effectieve opslagoplossingen zijn essentieel in elke fase van de AI-pijplijn, van datacuratie tot training en gevolgtrekking, omdat ze AI-workloads in staat stellen efficiënt en op schaal te werken. AI-pipelines hebben opslag nodig die naadloos latency-gevoelige taken aankan, kan schalen om te voldoen aan hoge-concurrency-eisen, verschillende datatypes ondersteunt en prestaties in gedistribueerde omgevingen kan handhaven.
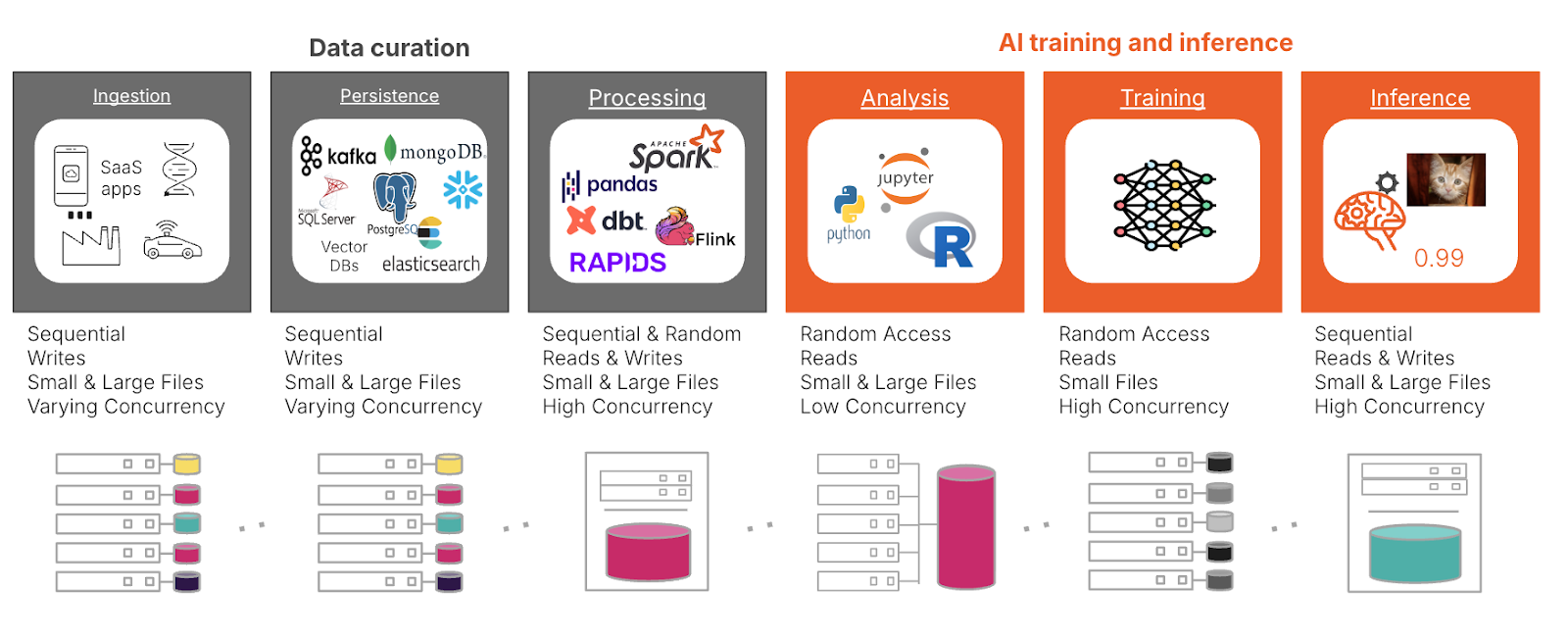
Afbeelding 1: Opslagpatronen voor AI zijn gevarieerd en vereisen een platform dat is gebouwd voor multidimensionale prestaties.
In de datacuratiefase begint het beheer van datasets op petabyte-to exabyte-schaal met opname, waarbij opslag naadloos moet schalen om enorme datavolumes aan te kunnen en tegelijkertijd een hoge verwerkingscapaciteit te garanderen. Realtime applicaties, zoals autonoom rijden, vereisen opslag met lage latency die in staat is om inkomende data onmiddellijk te verwerken. DirectFlash®-modules (DFM’s) blinken uit in deze scenario’s door traditionele SSD-architecturen te omzeilen om rechtstreeks toegang te krijgen tot NAND-flash, waardoor snellere, consistentere prestaties met aanzienlijk verminderde latency worden geleverd. In vergelijking met legacy SSD’s en SCM bieden DFM’s ook een grotere energie-efficiëntie, waardoor organisaties kunnen voldoen aan de eisen van grootschalige AI-workloads, terwijl het stroomverbruik wordt geoptimaliseerd en voorspelbare prestaties onder hoge gelijktijdigheid behouden blijven.
Tijdens persistentie moeten data-opslag oplossingen langdurige retentie en snelle toegankelijkheid voor vaak gebruikte data ondersteunen. De verwerkingsstap is essentieel voor het voorbereiden van data voor training, waarbij opslag een reeks datatypes en -groottes efficiënt moet beheren, en gestructureerde en ongestructureerde data moet verwerken in formaten zoals NFS, SMB en object.
In de AI-trainings- en inferentiefase genereert modeltraining intensieve lees-/schrijfvereisten, waarvoor scale-out-architecturen nodig zijn om prestaties over meerdere nodes te garanderen. Efficiënte controlepunten en versiebeheersystemen zijn in dit stadium van cruciaal belang om dataverlies te voorkomen. Naast checkpointing vormen opkomende architecturen zoals retrieval-augmented generation (RAG) unieke uitdagingen voor opslagsystemen. RAG vertrouwt op efficiënt ophalen van externe kennisbanken tijdens gevolgtrekking, waarbij opslag met lage latency en hoge verwerkingscapaciteit nodig is die in staat is om gelijktijdige, parallelle query’s te verwerken. Dit legt extra druk op Metadata beheeren schaalbare indexering, waardoor geavanceerde opslagarchitecturen nodig zijn om de prestaties te optimaliseren zonder knelpunten.
Door opslagoplossingen af te stemmen op de specifieke behoeften van elke pijplijnfase, kunnen organisaties de AI-prestaties optimaliseren en de flexibiliteit behouden die nodig is om de veranderende AI-eisen te ondersteunen.
Bezoek ons op NVIDIA GTC van 17-25 maart in het San Jose Convention Center
AIAItraining en -inferentie op Exabyte-schaal mogelijk maken
Conclusie
Storage is de ruggengraat van AI, met toenemende complexiteit van het model en data-intensiteit die exponentiële eisen aan de infrastructuur stellen. Traditionele opslagarchitecturen kunnen niet aan deze behoeften voldoen, waardoor de adoptie van agile, high-performance opslagoplossingen essentieel is.
De symbiotische relatie tussen AI en opslagplatforms betekent dat de vooruitgang in opslag niet alleen ondersteuning biedt, maar ook de vooruitgang van AI versnelt. Voor bedrijven die net AI beginnen te verkennen, is flexibiliteit cruciaal: Ze hebben opslag nodig die kan schalen naarmate hun data- en computebehoeften groeien, meerdere formaten ondersteunt (bijv. bestand, object) en gemakkelijk integreert met bestaande tools.
Organisaties die investeren in moderne opslagplatforms plaatsen zichzelf in de voorhoede van innovatie. Dit vereist:
- Infrastructuur beoordelen: Huidige beperkingen en gebieden voor onmiddellijke verbetering identificeren.
- Schaalbare oplossingen implementeren: Implementeer platforms die flexibiliteit, hoge prestaties en naadloze groei bieden.
- Plannen voor toekomstige behoeften: Blijf opkomende trends voor om ervoor te zorgen dat het platform meegroeit met AI-ontwikkelingen.
Door opslagplatforms te prioriteren als een kerncomponent van AI-strategie, kunnen organisaties nieuwe kansen ontsluiten, voortdurende innovatie stimuleren en een concurrentievoordeel behouden in de datagestuurde toekomst.
Wilt u meer weten?
Bezoek de AIAIoplossingenpagina
Bekijk de webinar-replay: “Overwegingen voor een versnelde strategische AIAIinfrastructuur voor ondernemingen“
Download de whitepaper: “Het Pure Storage-platform voor AI”

ANALYST REPORT,
Top Storage Recommendations
to Support Generative AI

A Game-changer for AI
Accelerate your AI initiatives with the Pure Storage platform.