

Samenvatting
FlashBlade//EXA is the newest member of the FlashBlade family. Optimized for AI workloads, this ultra-scale data storage platform provides massive storage throughput and operates at extreme levels of performance and scale.


Racers, start uw motoren! Pure Storage is verheugd om FLASHBLADE//EXA™ aan te kondigen – een ultra-scale dataopslagplatform dat is geoptimaliseerd voor AI-workloads door een enorme opslagdoorvoer te bieden en te werken op extreme prestatie- en schaalniveaus.
Wat hebben high-performance autofabrikanten en Pure Storage gemeen? Net zoals autofabrikanten van topniveau geavanceerde raceautomodellen ontwerpen die de grenzen van snelheid en efficiëntie verleggen, is FLASHBLADE//EXA gebouwd om prestaties van het volgende niveau te leveren voor AI- en HPC-workloads. FlashBlade//EXA is vergelijkbaar met die voorbeelden in de zin dat het een FLASHBLADE®-systeem is met Purity//FB dat zeer geoptimaliseerd is om prestaties van het volgende niveau te bieden voor de meest veeleisende AI-workloads. Het is een aanvulling op de high-performance FlashBlade//S™ en high-density FlashBlade//E™-modellen die al vier jaar op rij bewezen zijn op de bedrijfsmarkt en erkend zijn in het Gartner® Magic Quadrant™ voor file- en objectstorageplatforms als marktleider.
De zakelijke uitdaging van snelle AI-vooruitgang
Naarmate AI-innovatie uitbreidt, ontdekken veel bedrijven snel waarde bij het uitbreiden of revolutioneren van hun bestaande activiteiten met modeltraining en gevolgtrekking. Deze versnelde groei heeft de toepassing van AI-workflows in voorverwerking, training, testen, fine-tuning en implementatie verhoogd – elk profiteert van krachtigere GPU’s en grotere, multimodale datasets.
Deze uitbreiding heeft ook nieuwe uitdagingen op het gebied van infrastructuur met zich meegebracht. Legacy-storageschaalbaarheid, checkpointing, beheer en prestatiebeperkingen van Metadata op schaal veroorzaken knelpunten en belemmeren het volledige gebruik van dure GPU-georiënteerde infrastructuren en vertragen de vooruitgang en innovatie. Dit heeft een grote invloed op de agressieve ROI-financiële druk van AI – elke infrastructuur die eraan is gewijd, moet op topprestaties draaien om de snelst mogelijke time-to-value voor modeltraining en gevolgtrekking te garanderen. Verloren tijd gaat verloren.
Bedrijfsuitdagingen worden versterkt met grootschalige AI-workflows
Deze zakelijke uitdaging van inactieve GPU’s die gelijk staan aan verloren tijd en geld wordt om twee redenen exponentieel versterkt op schaal, bijv. GPU-cloudproviders en AI-labs. Ten eerste is enorme operationele efficiëntie op schaal de kern van hun winstgevendheid en ligt deze veel verder dan wat de meeste on-prem/in-house datacenteroperaties beheren. Een blog die we vorig jaar hebben gepubliceerd, bood inzicht in hoe dienstverleners denken en hoe automatisering en brutale standaardisatie van cruciaal belang zijn voor hun activiteiten. Ten tweede nemen dienstverleners zich in voor het kernprincipe om te voorkomen dat resources inactief worden. Voor hen zijn niet-actieve GPU’s in elk AI-model een kans om inkomsten te verliezen – inefficiënties in opslag op hun operationele niveau kunnen schadelijk zijn.
Traditionele high-performance opslagarchitecturen zijn gebouwd op parallelle bestandssystemen en zijn ontworpen en geoptimaliseerd voor traditionele, toegewijde high-performance computing (HPC)-omgevingen. HPC-workloads zijn voorspelbaar, zodat de parallelle opslagsystemen kunnen worden geoptimaliseerd voor specifieke prestatieschalen. Grootschalige, op AI gebaseerde workflows en modellen verschillen van traditionele HPC omdat ze complexer zijn en veel meer parameters omvatten die ook multimodaal zijn door tekstbestanden, afbeeldingen, video’s en meer op te nemen – die allemaal tegelijkertijd moeten worden verwerkt door tienduizenden GPU’s. Deze nieuwe dynamiek bewijst snel hoe traditionele HPC-gebaseerde opslagbenaderingen moeite hebben om op grotere schaal te presteren. Meer in het bijzonder worden de prestaties van traditionele parallelle opslagsystemen omstreden met het onderhoud van Metadata en bijbehorende data vanuit hetzelfde opslagcontrollervlak.
Dit opkomende knelpunt vereist een nieuwe manier van denken voor Metadata beheeren optimalisaties van datatoegang om diverse datatypes en hoge gelijktijdigheid van AI-workloads efficiënt te beheren op de schaal van een serviceprovider.
Extreme Storage-schaalvereisten met AI Workload Evolution
Naarmate datavolumes toenemen, wordt Metadata beheereen cruciaal knelpunt. Legacy-storage heeft moeite om Metadata efficiënt te schalen, wat leidt tot latency en prestatieverlies – vooral voor AI- en HPC-workloads die extreem parallellisme vereisen. Traditionele architecturen, gebouwd voor sequentiële toegang, kunnen het niet bijhouden. Ze hebben vaak last van stijfheid en complexiteit, waardoor de schaalbaarheid wordt beperkt. Het overwinnen van deze uitdagingen vereist een Metadata-first architectuur die naadloos schaalt, enorme parallelliteit ondersteunt en knelpunten elimineert. Naarmate de AI- en HPC-kansen evolueren, worden de uitdagingen alleen maar groter.

De bewezen Metadata core die beschikbaar is in FlashBlade//S heeft zakelijke klanten geholpen om veeleisende AI-training, tuning en inferentievereisten aan te pakken door Metadata-uitdagingen te overwinnen, zoals:
- Concurrency management: Efficiënt omgaan met enorme hoeveelheden Metadata verzoekenover meerdere nodes
- Hotspotpreventie: Het vermijden van knelpunten van een enkele Metadata serverdie de prestaties kunnen aantasten en voortdurende tuning en optimalisaties vereisen
- Consistentie op schaal: Zorgen voor synchronisatie tussen gedistribueerde Metadatakopieën
- Efficiënt hiërarchiebeheer: Optimaliseren van complexe bestandssysteemoperaties met behoud van prestaties
- Schaalbaarheid en veerkracht: Behoud van hoge prestaties naarmate datavolumes exponentieel groeien
- Operationele efficiëntie: Ervoor zorgen dat beheer en overhead worden geminimaliseerd en geautomatiseerd om efficiëntie op schaal te ondersteunen
FLASHBLADE//EXA pakt AI-prestatie-uitdagingen op schaal aan
Pure Storage heeft een bewezen staat van dienst in het ondersteunen van klanten in een breed scala aan high performance use cases en in elke fase van hun AI-reis. Sinds de introductie van AIRI® (AI-Ready Infrastructuur) in 2018 zijn we toonaangevend gebleven met innovaties zoals certificeringen voor NVIDIA DGX SuperPOD™ en NVIDIA DGX BasePOD™ en kant-en-klare oplossingen zoals GenAI Pods. FLASHBLADE heeft vertrouwen gekregen in de AI- en HPC-markt van bedrijven, waardoor organisaties als Meta zijn AI-workloads efficiënt kunnen schalen. Onze Metadata core is gebouwd op een massaal gedistribueerde transactionele database, en key-value store-technologie heeft gezorgd voor een hoge Metadata beschikbaarheid en efficiënte schaalbaarheid. Door inzichten van hyperscalers toe te passen en gebruik te maken van onze geavanceerde Metadata core die bewezen is met FlashBlade//S, heeft Pure Storage de unieke mogelijkheid om extreme performance storage te leveren die de Metadata-uitdagingen van grootschalige AI en HPC overwint.
Voer FLASHBLADE//EXA in.
Nu extreme end-to-end AI-workflows de grenzen van de infrastructuur verleggen, is de behoefte aan een dataopslagplatform dat overeenkomt met deze schaal nog nooit zo groot geweest. FLASHBLADE//EXA breidt de FLASHBLADE-familie uit en zorgt ervoor dat grootschalige AI- en HPC-omgevingen niet langer worden beperkt door legacy-opslagbeperkingen.
FLASHBLADE//EXA is ontworpen voor AI-fabrieken en levert een massaal parallelle verwerkingsarchitectuur die data en Metadata opsplitst, waardoor knelpunten en complexiteit in verband met legacy parallelle bestandssystemen worden geëlimineerd. Gebouwd op de bewezen sterke punten van FLASHBLADE en aangedreven door de geavanceerde Metadata-architectuur van Purity//FB, biedt het een ongeëvenaarde verwerkingscapaciteit, schaalbaarheid en eenvoud op elke schaal.
Of het nu gaat om het ondersteunen van AI-natives, tech titans, AI-gedreven ondernemingen, GPU-aangedreven cloudproviders, HPC-labs of onderzoekscentra, FLASHBLADE//EXA voldoet aan de eisen van de meest data-intensieve omgevingen. Het ontwerp van de volgende generatie maakt naadloze productie, gevolgtrekking en training mogelijk, en biedt een uitgebreid dataopslagplatform voor zelfs de meest veeleisende AI-workloads.
Onze innovatieve aanpak in de manier waarop we Purity//FB hebben gewijzigd, waarbij de snelle doorvoernetwerkgebaseerde I/O in twee discrete elementen werd opgesplitst:
- De FLASHBLADE-array slaat de Metadata op en beheert deze met zijn toonaangevende scale-out gedistribueerde key/value-database.
- Een cluster van datanodes van derden is waar de datablokken met zeer hoge snelheid worden opgeslagen en benaderd vanuit het GPU-cluster via Remote Direct Memory Access (RDMA) met behulp van standaard netwerkprotocollen.
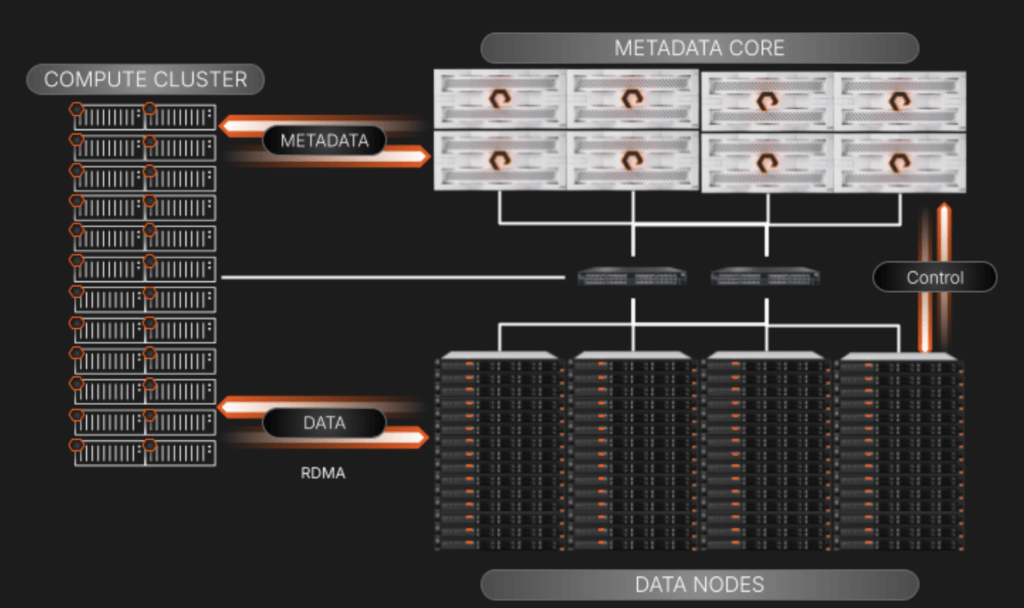
Deze scheiding biedt niet-blokkerende datatoegang die exponentieel toeneemt in high-performance computerscenario’s waarbij de Metadata verzoekengelijk kunnen zijn aan, zo niet groter dan, data-I/O-bewerkingen.
Waarom Off-The-Shelf Servers en SSD’s voor datanodes?
Grootschalige AI-omgevingen kunnen een gevestigde investering hebben van 1U- en 2U-servers met SSD’s als infrastructuurbouwstenen. FLASHBLADE//EXA maakt gebruik van kant-en-klare servers voor het datavlak, waardoor het gemakkelijker wordt om in de architectuur van de doelklant te passen (in dit geval grootschalige omgevingen). Dit benadrukt een belangrijk punt over ons dataopslagplatform:
*De kracht van Purity, als het hart van ons platform, ligt in het vermogen om te worden gewijzigd om nieuwe gebruikssituaties aan te pakken, zelfs als het betekent dat het zich moet uitrekken om buiten onze eigen hardware te werken. Het oplossen van uitdagingen met onze software is een kernprincipe voor ons, omdat het een elegantere aanpak is en klanten een snellere time-to-value biedt.
Deze kant-en-klare datanodes geven klanten de flexibiliteit om zich in de loop van de tijd aan te passen en kunnen worden gedreven door de evolutie van de klanten over hoe ze NAND-flash in hun datacenters gebruiken.
Een overzicht op hoog niveau van FLASHBLADE//EXA-componenten en I/O
Bij het scheiden van de Metadata en data servicing planes hebben we ons gericht op het eenvoudig schalen en beheren van de elementen in het bovenstaande diagram:
- Metadata Core: Hiermee worden alle Metadata-query’s van het compute cluster bediend. Wanneer een query wordt uitgevoerd, wordt het aanvragende compute node naar het specifieke data node geleid om zijn werk te doen. De array houdt ook toezicht op de relatie tussen datanodes en Metadata via een control plane-verbinding die achter de schermen van zijn eigen netwerksegment staat.
- Datanodes van derden: Dit zijn standaard kant-en-klare servers om brede compatibiliteit en flexibiliteit te garanderen. De datablokken bevinden zich op de NVMe-schijven in deze servers. Ze zullen een “dunne” Linux-gebaseerde OS en kernel uitvoeren met volumemanagement en RDMA-doeldiensten die zijn aangepast om te werken met Metadata die zich op de FLASHBLADE//EXA-array bevinden. We zullen een Ansible-draaiboek opnemen om de implementatie en upgrades van de nodes te beheren om eventuele zorgen over complexiteit op schaal te elimineren.
- Parallelle toegang tot data met behulp van de bestaande netwerkomgeving: FLASHBLADE//EXA maakt gebruik van een elegante aanpak die gebruikmaakt van een zeer beschikbaar, single-core netwerk dat BGP gebruikt om verkeer tussen Metadata, data en workload clients te routeren en te beheren. Dit ontwerp maakt naadloze integratie in bestaande klantnetwerken mogelijk, waardoor de implementatie van zeer parallelle opslagomgevingen wordt vereenvoudigd. Belangrijk is dat alle benutte netwerkprotocollen voldoen aan de industrienorm; de communicatiestack bevat geen bedrijfseigen elementen.
De uitdagingen van legacy high-performance storage uitpakken met parallelle bestandssystemen en uitgesplitste modellen
Veel opslagleveranciers die zich richten op de krachtige aard van grote AI-workloads lossen alleen de helft van het parallellismeprobleem op – ze bieden de breedst mogelijke netwerkbandbreedte voor klanten om datadoelen te bereiken. Ze pakken niet aan hoe Metadata en data worden onderhouden met een enorme verwerkingscapaciteit, waar de knelpunten op grote schaal ontstaan. Dit is logisch omdat de bedoeling van het ontwerp van NFS toen Sun Microsystems het in 1984 creëerde, was om simpelweg de kloof tussen lokale en externe bestandstoegang te overbruggen, waarbij de ontwerpfocus functionaliteit over snelheid was.
Uitdagingen van schalen met legacy NAS
Het ontwerp en de schaal van legacy NAS verbiedt het ondersteunen van parallelle opslag vanwege het ontwerp voor één enkel doel om operationele fileshares te onderhouden en het onvermogen om I/O lineair te schalen naarmate meer controllers worden toegevoegd.
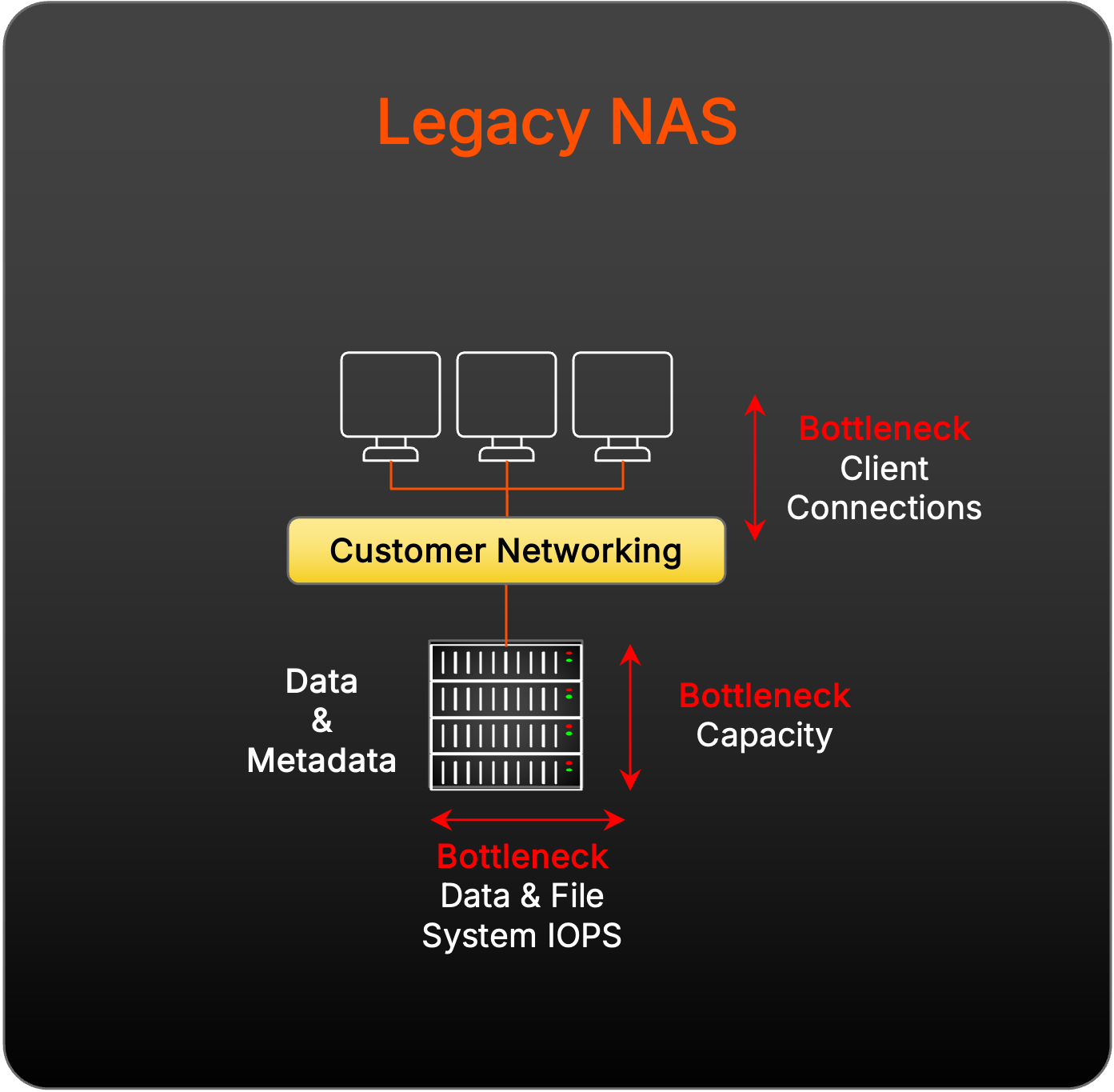
Uitdagingen van schalen met traditionele parallelle bestandssystemen
Zelfs vóór de huidige opkomst van AI maakten sommige legacy-opslagaanbieders gebruik van gespecialiseerde parallelle bestandssystemen zoals Lustre om hoge verwerkingscapaciteit parallellisme te leveren voor high-performance computerbehoeften. Hoewel dit werkte voor verschillende grote en kleine omgevingen, is het gevoelig voor Metadata-latency, extreem gecompliceerd netwerken en beheercomplexiteit, vaak overgedragen aan PhD’s die toezicht hielden op hun HPC-architecturen en de bijbehorende zachte kosten bij het schalen naar grotere behoeften.
Uitdagingen van uitgesplitste data en computeroplossingen
Andere opslagleveranciers hebben hun oplossingen ontworpen om niet alleen te vertrouwen op een speciaal gebouwd parallel bestandssysteem, maar ook een rekenaggregatielaag toe te voegen tussen workloadclients en de Metadata- en datatargets:
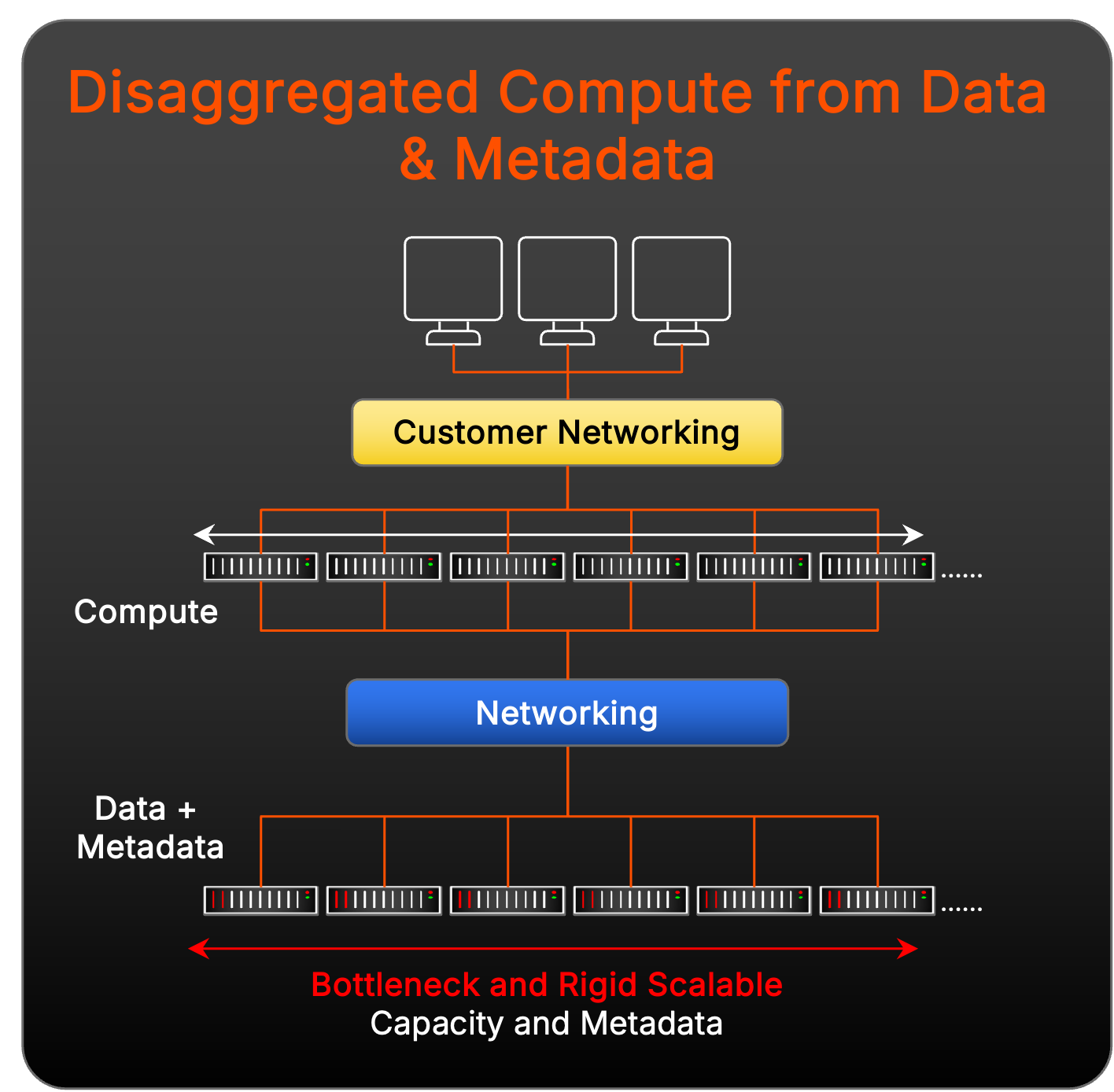
Dit model heeft te maken met uitdagingen op het gebied van expansierigiditeit en meer complexiteit van het management dan pNFS bij het schalen voor enorme prestaties, omdat het gaat om het toevoegen van meer bewegende delen met compute-aggregatienodes. Er is nog een mogelijke uitdaging – de implementatie van uitgesplitste datatoegangsfuncties in dit model brengt onverwachte latency in de stack met zich mee omdat het netwerk veel ingewikkelder wordt in het beheer van de adressering, bekabeling en connectiviteit met drie discrete lagen in vergelijking met wat nodig is voor pNFS.
Daarnaast krijgt elke data- en Metadata node een vaste hoeveelheid cache toegewezen waar Metadata altijd worden opgeslagen. Deze stijfheid dwingt data en Metadata in lockstep te schalen, waardoor inefficiënties ontstaan voor multimodale en dynamische workloads. En naarmate de workload verschuift, kan deze benadering van lineaire schaalbaarheid leiden tot prestatieknelpunten en onnodige overprovisioning van de infrastructuur, waardoor het resourcemanagement verder wordt bemoeilijkt en de flexibiliteit wordt beperkt.
We zijn ook nog maar net begonnen
Onze FLASHBLADE//EXA-aankondiging brengt een revolutie teweeg in prestaties, schaalbaarheid en eenvoud voor grootschalige AI-workloads. En we zijn nog maar net begonnen.
Neem contact op met uw Pure Storage-team om meer te weten te komen over hoe we, nogmaals, conventioneel denken verstoren in een van de snelgroeiende segmenten van de industrie!
Ontmoet ons op NVIDIA GTC 2025, 17-21 maart. Boek een vergadering.
Bekijk pure.ai en onze AIAIoplossingenpagina voor meer informatie.

FlashBlade//EXA
Experience the World’s Most Powerful Data Storage Platform for AI
Join the Webinar
Discover the power of FlashBlade//EXA for AI workloads. April 24, 2005.



