

Samenvatting
This article shows how to seed a database from a SQL instance that is in a Windows availability group into a SQL instance running in a pod in a Kubernetes cluster using a distributed availability group.


Dit artikel over SQL Server gedistribueerde beschikbaarheidsgroepen verscheen oorspronkelijk op Andrew Pruski’s blog. Het is opnieuw gepubliceerd met het krediet en de toestemming van de auteur.
Een tijdje geleden schreef ik over het gebruik van een platformonafhankelijke (of clusterloze) beschikbaarheidsgroep om een database van een Windows SQL-instantie in een pod in Kubernetes te plaatsen.
Ik had vorige week een gesprek met een collega en ze vroegen: “Wat als de bestaande Windows-instantie al in een beschikbaarheidsgroep zit?”
Dit is een eerlijke vraag, omdat het vrij zeldzaam is (naar mijn ervaring) om een standalone SQL-instantie in productie te draaien… de meeste gevallen zijn in een vorm van HA-setup, of het nu een failover-clusterinstantie of een beschikbaarheidsgroep is.
Failover-clusterinstances werken met een clusterloze beschikbaarheidsgroep, maar het is een ander verhaal als het gaat om bestaande beschikbaarheidsgroepen.
Een Linux-node kan niet worden toegevoegd aan een bestaande Windows-beschikbaarheidsgroep (vertrouw me, ik heb het langer geprobeerd dan ik zou toegeven), dus de enige manier om het te doen is door een gedistribueerde beschikbaarheidsgroep te gebruiken.
Laten we het proces dus eens doornemen!
Hier is de bestaande Windows-beschikbaarheidsgroep:
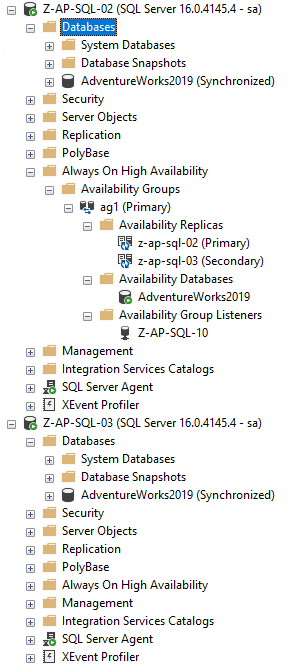
Gewoon een standaard AG met twee knooppunten met één database die al over de knooppunten is gesynchroniseerd. Het is die database die we gaan gebruiken voor de pod die op het Kubernetes-cluster draait met behulp van een gedistribueerde beschikbaarheidsgroep.
Hier is het Kubernetes-cluster:
kubectl krijgt nodes
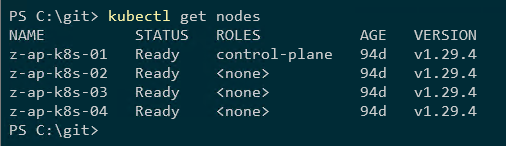
Vier nodes, één besturingsvlaknode en drie workernodes.
OK, dus het eerste wat u moet doen is een statefulset implementeren met één SQL Server-pod (met behulp van een bestand genaamd sqlserver-statefulset.yaml):
kubectl apply -f .\sqlserver-statefulset.yaml
Dit is het manifest van de statefulset:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465
apiVersion: apps/v1kind: StatefulSetmetadata: naam: mssql-statefulsetspec: serviceNaam: "mssql" replica's: 1 podManagementBeleid: Parallelle selector: matchLabels: naam: mssql-pod template:Metadata: labels: naam: mssql-pod annotaties:stork.libopenstorage.org/disableHyperconvergence: "true" spec: beveiligingContext: fsGroep: 10001 hostAliases: - ip: "10.225.115.129" hostnamen: - "z-ap-sql-10" containers: - naam: Afbeelding mssql-container: mcr.microsoft.com/mssql/server:2022-CU15-ubuntu-20.04ports: - containerPort: 1433 Naam: mssql-port env: - naam: MSSQL_PID value: "Ontwikkelaar" - naam: ACCEPT_EULA value: "Y" - naam: MSSQL_AGENT_ENABLED value: "1" - naam: MSSQL_ENABLE_HADR value: "1" - naam: MSSQL_SA_PASSWORD value: "Testing1122"-volumeMontages: - naam: sqlsystem mountPath: /var/opt/mssql - naam: sqldata mountPath: /var/opt/sqlserver/datavolumeClaimTemplates: - Metadata: naam: sqlsystem spec: accessModes: - ReadWriteOnce resources: requests: storage: 1GistorageClassName: mssql-sc - Metadata: naam: sqldata spec: accessModes: - ReadWriteOnce resources: verzoeken: opslag: 25GistorageClassName: mssql-sc
Net als bij mijn laatste bericht is dit behoorlijk onoverzichtelijk. Geen resourceslimieten, toleranties, etc. Het heeft twee persistente volumes: één voor de systeemdatabases en één voor de gebruikersdatabases van een opslagklasse die al in het cluster is geconfigureerd.
Eén ding om op te merken:
1234 hostAliases:- ip: "10.225.115.129" hostnamen: - "z-ap-sql-10"
Hier wordt een invoer in het hostsbestand van de pod gemaakt voor de luisteraar van de Windows-beschikbaarheidsgroep.
Het volgende wat u moet doen is twee diensten implementeren: één zodat we verbinding kunnen maken met de SQL-instantie (op poort 1433) en één voor de AG (poort 5022):
kubectl apply -f .\sqlserver-services.yaml
Dit is het manifest voor de diensten:
12345678910111213141516171819202122232425 apiVersie: v1kind: Servicemetadata: naam: mssql-servicespec: poorten: - naam: mssql-poorten poort: 1433 targetPort: 1433 selector: naam: mssql-pod type: LoadBalancer---apiVersie: v1kind: Servicemetadata: naam: mssql-ha-servicespec: poorten: - naam: mssql-ha-ports poort: 5022 targetPort: 5022 selector: naam: mssql-pod type: LoadBalancer
Opmerking: We zouden slechts één dienst kunnen gebruiken met meerdere geconfigureerde poorten, maar ik houd ze hier gescheiden om te proberen de zaken zo duidelijk mogelijk te houden.
T-SQL Snapshot Backup gebruiken: Point-in-time herstel
Controleer of alles er goed uitziet:
kubectl krijg alles
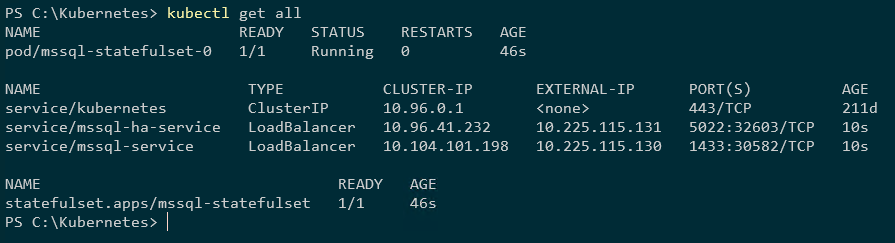
Nu moeten we in alle gevallen de mastersleutel, login en gebruiker aanmaken:
123 CREËER DE BELANGRIJKSTE INSCHRIJVING DOOR HET WACHTWOORD = '
Maak vervolgens een certificaat in de SQL-instantie in de pod:
CREËER CERTIFICAAT dbm_certificate MET ONDERWERP = 'Mirroring_certificate', EXPIRY_DATE = '20301031'
Maak een back-up van dat certificaat:
123456 BACK-UPCERTIFICAAT dbm_certificateNAAR BESTAND = '/var/opt/mssql/data/dbm_certificate.cer'MET PRIVATE KEY (BESTAND = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION PER WACHTWOORD = '
Kopieer het certificaat lokaal:
12 kubectl cp mssql-statefulset-0:var/opt/mssql/data/dbm_certificate.cer ./dbm_certificate.cer -n prodkubectl cp mssql-statefulset-0:var/opt/mssql/data/dbm_certificate.pvk ./dbm_certificate.pvk -n prod
En kopieer vervolgens de bestanden naar de Windows-boxen:
1234 Copy-Item dbm_certificate.cer \\z-ap-sql-02\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.pvk \\z-ap-sql-02\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.cer \\z-ap-sql-03\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.pvk \\z-ap-sql-03\E$\SQLBackup1\ -ForceCopy-Item
Zodra de bestanden op de Windows-boxen staan, kunnen we het certificaat in elke Windows SQL-instantie maken:
1234567 CREËER dbm_certificate CERTIFICAATAUTORISATIE dbm_user VANUIT BESTAND = 'E:\SQLBackup1\dbm_certificate.cer' MET PRIVÉSLEUTEL (BESTAND = 'E:\SQLBackup1\dbm_certificate.pvk', DECRYPTION PER WACHTWOORD = '')
Oké, geweldig! Nu moeten we een mirroring eindpunt creëren in de SQL-instantie in de pod:
123456789101112 [Hadr_endpoint]EINDPUNTSTATUS CREËREN = GESTARTALS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL)VOOR DATA_MIRRORING (ROL = ALL, AUTHENTICATIE = WINDOWS CERTIFICAAT [dbm_certificate], ENCRYPTIE = VEREIST ALGORITME AES );ALTER [Hadr_endpoint]EINDPUNTSTATUS = GESTART;GRANT CONNECT OP EINDPUNT::[Hadr_endpoint] AAN [dbm_login];
Er zijn al eindpunten in de Windows-instanties, maar we moeten ze bijwerken om het certificaat te gebruiken voor authenticatie:
12345678910 [Hadr_endpoint]EINDPUNTSTATUS WIJZIGEN = GESTARTALS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL)VOOR DATABASE_MIRRORING (VERIFICATIE = WINDOWS-CERTIFICAAT [dbm_certificate], ENCRYPTIE = VEREIST ALGORITME AES );GRANT CONNECT OP EINDPUNT:[Hadr_endpoint] AAN [dbm_login];
Nu kunnen we een clusterloze beschikbaarheidsgroep met één knooppunt creëren in de SQL-instantie in de pod:
12345678910111213 CREËER BESCHIKBAARHEIDSGROEPMET[AG2] (CLUSTER_TYPE=NONE) FORREPLICA OP'mssql-statefulset-0' MET ( ENDPOINT_URL = 'TCP://mssql-statefulset-0.com:5022', FAILOVER_MODE = MANUAL ,AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ,BACKUP_PRIORITY = 50 ,SEEDING_MODE = = AUTOMATIC ,SECONDARY_ROLE(ALLOW_CONNECTIONS = NEE) )
Geen luisteraar hier; we gaan de mssql-ha-service gebruiken als eindpunt voor de gedistribueerde beschikbaarheidsgroep.
Oké, dus op het primaire knooppunt van de Windows-beschikbaarheidsgroep kunnen we de gedistribueerde beschikbaarheidsgroep creëren:
1234567891011121314151617 CREËER BESCHIKBAARHEIDSGROEPMET [DistributedAG] (GEDISTRIBUEERD) BESCHIKBAARHEIDSGROEP OP'AG1' MET ( LISTENER_URL = 'tcp://Z-AP-SQL-10:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = = MANUAL, SEEDING_MODE = AUTOMATISCH ), 'AG2' MET ( LISTENER_URL = 'tcp://10.225.115.131:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = = AUTOMATISCH );
We konden een hostbestandsinvoer gebruiken voor de URL in AG2 (dat deed ik in het vorige bericht), maar hier gebruiken we gewoon het IP-adres van de mssql-ha-service.
Oké, bijna klaar! We moeten nu lid worden van de beschikbaarheidsgroep in de SQL-instantie in de pod:
1234567891011121314151617 NA BESCHIKBAARHEIDSGROEP SLUIT [DistributedAG]U AAN BIJ BESCHIKBAARHEIDSGROEP OP'AG1' MET ( LISTENER_URL = 'tcp://Z-AP-SQL-10:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = = MANUAL, SEEDING_MODE = AUTOMATISCH ), 'AG2' MET ( LISTENER_URL = 'tcp://10.225.115.131:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = = AUTOMATISCH );
En dat zou het moeten zijn! Als we nu verbinding maken met de SQL-instantie in de pod, is de database er!
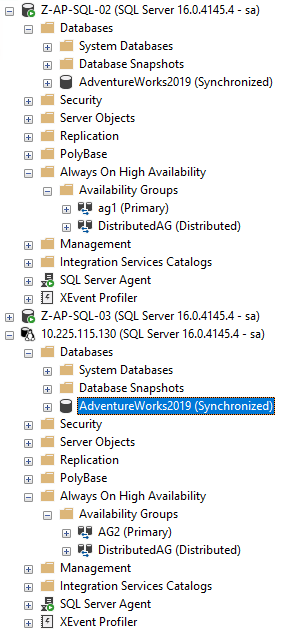
Daar is het! Oké, één ding dat ik hier niet heb meegemaakt is hoe ik automatisch zoeken vanuit Windows naar een Linux SQL-instantie kan laten werken. Ik heb in mijn vorige bericht doorgenomen hoe dat werkt, maar de gist is, zolang de databasegegevens en logbestanden zich onder de standaardgegevens en het logpad van de Windows SQL-instantie bevinden, zullen ze automatisch worden geplaatst op de standaardgegevens en logpaden van de Linux SQL-instantie.
Zo zet u een database uit een SQL-instantie in een Windows-beschikbaarheidsgroep in een SQL-instantie die in een Kubernetes-cluster draait met behulp van een gedistribueerde beschikbaarheidsgroep.

How Storage Plays a Role in Optimizing Database Environments

Stellar Storage
Boost performance for SQL Server with Pure Storage.



