


Supply chains—or more specifically, data supply chain failures—are a hot topic right now. People are frustrated because they can’t find the products they need on store shelves, such as pet food, and manufacturers are working overtime to resolve issues from ingredient shortages to transportation bottlenecks, undermining their efforts to get finished products into consumers’ hands.
The global supply chain’s fragility is so severe that many companies are already laying the groundwork to completely redesign their supply chain networks to be both stronger and more flexible for the future. As they do that, they’ll also want to consider whether another business-critical supply chain they rely on needs improvement: their data supply chain.
Data supply chain challenges aren’t grabbing headlines the same way the global supply chain failures are, but they should be. Without a resilient supply chain, companies will struggle to transform into the data-driven and agile organizations they need to be to compete in the Fourth Industrial Revolution (4IR). Also, given how essential data is to supply chain management and planning, it stands to reason that a next global supply chain can’t be built on a broken supply chain, either.
Here’s a look at what the modern supply chain is, how it’s evolving, and the challenges shaping that evolution.
What is a Data Supply Chain?
A data supply chain is the steps involved in transforming raw data into the actionable insights companies use to drive innovation, generate revenue, serve customers, and make informed decisions on such things as what product to make next and which technologies to invest in. Like a real supply chain, a supply chain relies on many different steps and participants working in unison to get a certain product to a certain place or group of people, although in this case the product is usable, or analyzed, data.
The typical steps of a supply chain are the creation of raw data, the transformation and integration of that raw data into various systems, and the consumption or analysis of that data to make it useful for an organization.
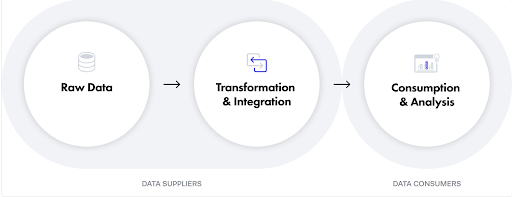
Caption: The data supply chain.
In a typical data supply chain, the company first extracts data in various formats from different and often siloed sources and prepares that data so it can be loaded into a repository to be accessed later for analysis. The data will then undergo more processes such as formatting, enriching, and cleansing before it can be analyzed and turned into business value.
This is a very simple overview of a complex, time-consuming process that requires many tools and players to execute—from advanced technologies, such as machine learning and artificial intelligence (AI), to human data experts, like data architects and data scientists. Exactly how, where, and by what or whom data is “transformed” depends on what type of information it is and what the business wants to do with it—which could be anything from detecting fraud to predicting equipment failures.
Data Supply Chain vs Data Pipeline
A data supply chain is different from a data pipeline in that a data pipeline is the tool or process by which data actually gets moved from one point to another. In that sense, a data pipeline is really a subset or part of a supply chain, which also involves data lakes, data warehouses, databases, potentially various types of data platforms, messaging queues, and analytics tools.
Data Supply Chain Challenges
Just as the global supply chain responsible for bringing products to our stores and doors is facing major challenges such as cost and complexity, so too is the modern supply chain that supplies our data products. The challenges for the supply chain are in fact quite similar to those faced by the global supply chain.
1. Complexity
Along with tech stacks in general, data supply chains have only become more complex over the last five years. Complexity is never good for any kind of system, but oftentimes, including in the world of technology, the way people solve problems is by adding more and more layers or components to them as bandaid-type fixes that end up slowing everything down and potentially even breaking whatever system these band-aids were intended to fix.
Data supply chains are no different. As with the hard goods of the global supply chain, the more data the world puts out, the harder it is to get that data through the supply chain to produce the data products companies rely on for their data-driven decision-making. Organizations tend to deal with this influx of data by adding more and more layers to their supply chain management system, which sometimes works initially but often leads to costly headaches down the line in the form of system failures, downtime, and potentially even costly data breaches.
2. Cost
Cost is another major challenge of modern data supply chains and it’s one that relate directly to complexity. Complexity-created gaps and inefficiencies throughout a supply chain prevent organizations from achieving their modern data analytics objectives fully, timely, and cost-effectively. The more complex your supply chain, the more expertise you will need to make it run smoothly and the more time and money you will spend fixing things that go wrong.
Cost is also directly related to scalability. Modern orgs need to find ways to scale their data pipelines and supply chains easily and affordably or, at the current rate of data growth, their budgets will soon be busted and they will find themselves patching up their supply chains in the cheapest way possible, which will only leads to deeper and more expensive issues down the line.
3. Dealing With Both Structured and Unstructured Data
The significant increase in the amount of unstructured data being produced is also wreaking havoc on the modern supply chain. Unstructured data is, by nature, harder to define and to process because it can’t be represented by numbers. The typical way to deal with unstructured data has been to throw it into a data lake, but data lakes present their own issues with data quality, reliability, and hacking.
Organizations end up throwing money at the problem by investing in more appliances and in technologies such as AI, but it ends up becoming a vicious cycle because they’re only adding more infrastructure to their supply chain that can’t scale, and this, in turn, exacerbates the cost and complexity issues mentioned above.
Modern Data Storage for a Seamless Data Supply Chain
To improve the overall performance of their supply chain, many organizations are embracing modern data storage that can consolidate all types of data with massive scale-out capabilities.
The consolidation of unstructured data into a central, accessible data layer helps enterprises streamline their data flow and make data more shareable across the business.
That’s why Pure developed FlashBlade//S®, a data storage platform that evolves and scales with you as your supply chain needs grow. FlashBlade//S delivers the scalability, flexibility, and investment protection to uncomplicate your unstructured data for the next decade and beyond via:
- Capacity and performance that can be updated independently and scaled flexibly and non-disruptively as your business needs change.
- Future-proofed upgradability and investment protection. Customers maintain availability, reduce waste, and keep data secure through unprecedented change.
- The option for consumption as a service to match customers’ growth ambitions.
Just like designing a next-generation supply chain for delivering physical goods, modernizing your supply chain takes careful planning and investment—and time. One thing is certain: In the 4IR, and even now, no business can afford to have anything but a flexible, high-performing supply chain that’s built with the future in mind.
Ready to get started strengthening your supply chain? Pure is here to help your business take a new approach to data and achieve competitive insights and uncomplicate data storage, forever! .
![]()



