


Pure Storage® FlashArray™//X provides a valuable combination of 100% NVMe all-flash performance, optional NVMe-oF for maximum performance and data center saving density, as well as rich enterprise features delivered via the Purity Operating Environment. With FlashArray, you can accelerate and consolidate production database applications as well as provide a robust storage infrastructure on which you can bet your business.
Why PostgreSQL? According to DB-Engines, PostgreSQL is the fastest growing database management system. In this post, we’ll compare the performance of PostgreSQL 12 on the FlashArray//X R3 vs. a SAS-DAS based system and discuss the benefits of using a modern data platform.
Test Bed Configuration
We tested PostgreSQL on Cisco UCS servers and FlashArray//X90 R3. The Cisco M5 server was connected to the FlashArray via Fibre Channel connections using Cisco’s VIC FCoE HBA [1137:0045] (rev a2) HBAs. There were eight paths from the host to the FlashArray (Figure 2). The same server was also configured with a 12G SAS RAID controller and two SAS SSDs.
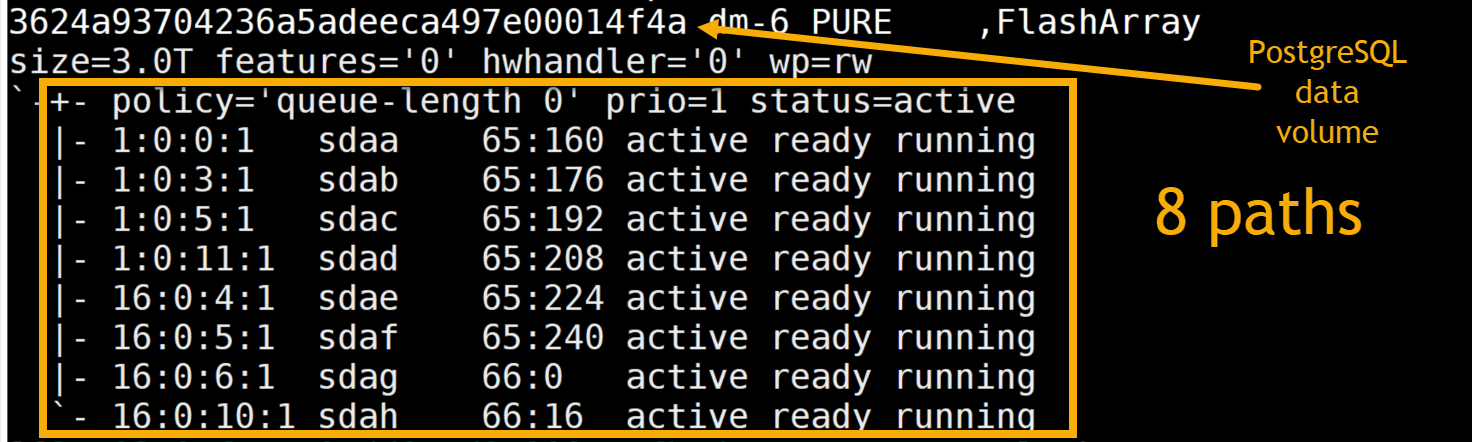
Figure 1: Server setup with FlashArray//X R3
Here is the complete breakdown of the setup:
- Operating System: CentOS Linux 7.6
- Storage: Pure Storage FlashArray//X90 R3
- Purity OS version: 5.3.2
- PostgreSQL version: 12.1
- CPU: Intel® Xeon® Platinum 8160 CPU @ 2.10GHz (48 cores)
- Memory: 512GiB system memory, DDR4 synchronous 2666MHz (0.4 ns)
- Server: Cisco UCSC-C220-M5SX
- DAS: SAS-DAS RAID 0 : 2 SAS SSD with 1.6TB
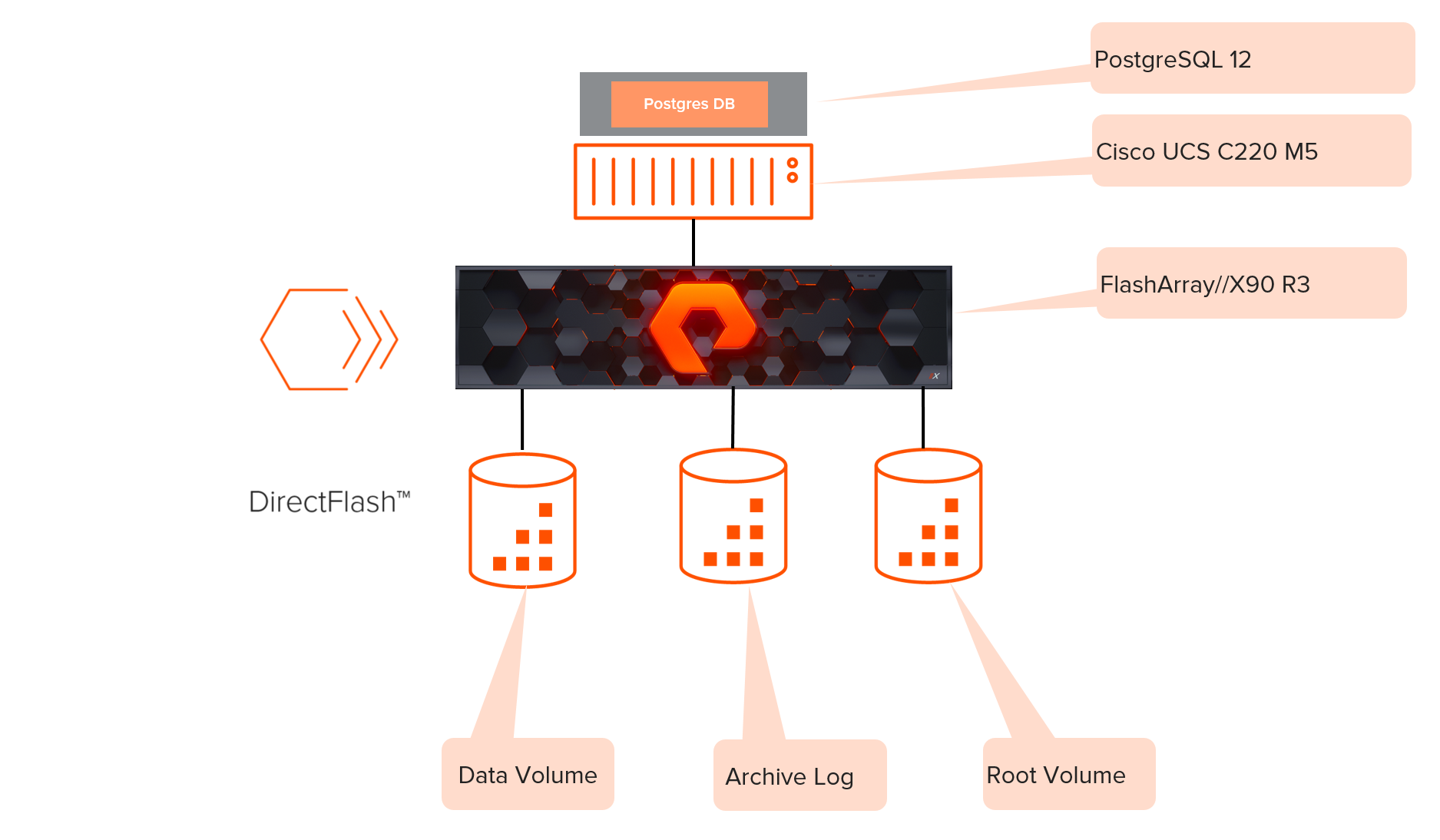
Figure 2
Performance Test Setup
We tested PostgreSQL using the SysBench benchmarking tool to compare the performance between PostgreSQL deployed on the FlashArray//X 90 R3 and the SAS-DAS system. SysBench is a very popular, extensible, multi-platform and multi-threaded benchmark tool for evaluating OS and database parameters that are vital for a system under immense load.
Configuration of Sysbench: TPCC-like data is used with sysbench with a scale factor of 100 and 10 warehouses.
We deployed PostgreSQL 12 with data volumes mounted using the FlashArray//X90 R3. Then, we mounted the same data volume using SAS-DAS RAID 0 disks. We then executed a Sysbench-generated workload executed against the PostgreSQL configuration on the FlashArray and DAS systems.
Performance Test Results
The SysBench performance report included an average number of transactions per second (tps) and latency. To adequately represent varying workloads, we increased the number of threads that simulate the number of database users and took measurements with each simulation.
We increased the number of threads for each run, then performed a forced checkpoint between each run. See the pseudo script for the SysBench testing:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
for thr in 48 64 96 128 256 512 1024 do sysbench /usr/share/sysbench/tpcc.lua --threads=$thr --tables=10 --scale=100 --pgsql-user=postgres --pgsql-password=XXXXXXX --pgsql-db=sysbench --db-driver=pgsql --time=XXX --report-interval=10 run echo "***CHECKPOINT...." su postgres << EOF cd /var/lib/pgsql psql -c "checkpoint;" exit EOF echo "***CHECKPOINT DONE****" sleep 30 Done |
As mentioned previously, we changed the mount point between the FlashArray//X90 R3 volumes and the SAS-DAS RAID 0 disks, then executed the same script again.
Results
Transactions per Second: Figure 3 shows that PostgreSQL 12 running on FlashArray//X 90 R3 had up to 20.48% higher tps than the SAS-DAS based database.
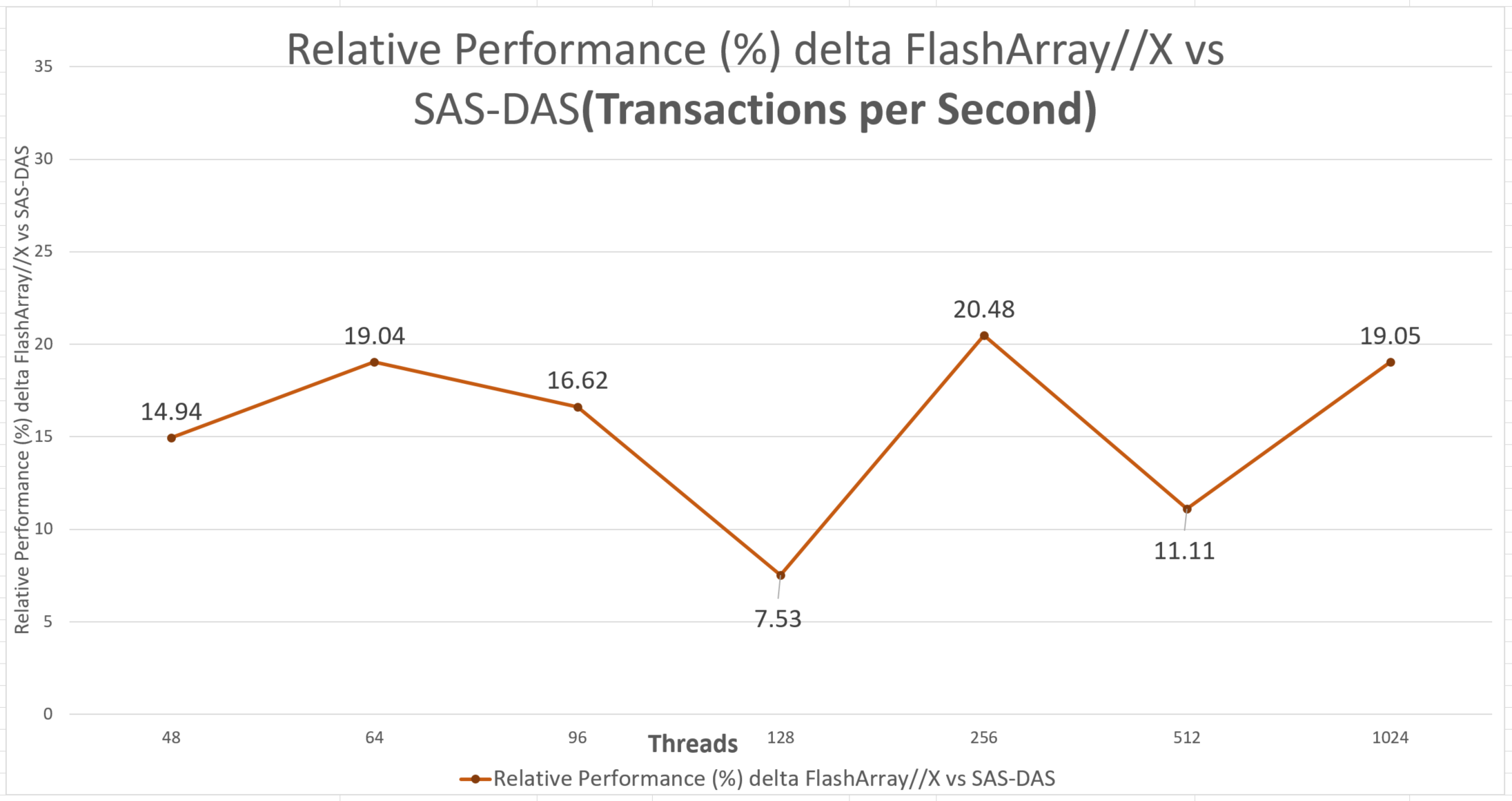
Figure 3: Relative performance difference in transactions per second of FlashArray//X compared to SAS-DAS
Latency: Latency is much lower on the FlashArray//X compared to SAS-DAS. The latency results show a negative delta, meaning that latency was as much as 12.66% less on the FlashArray//X (Figure 4).
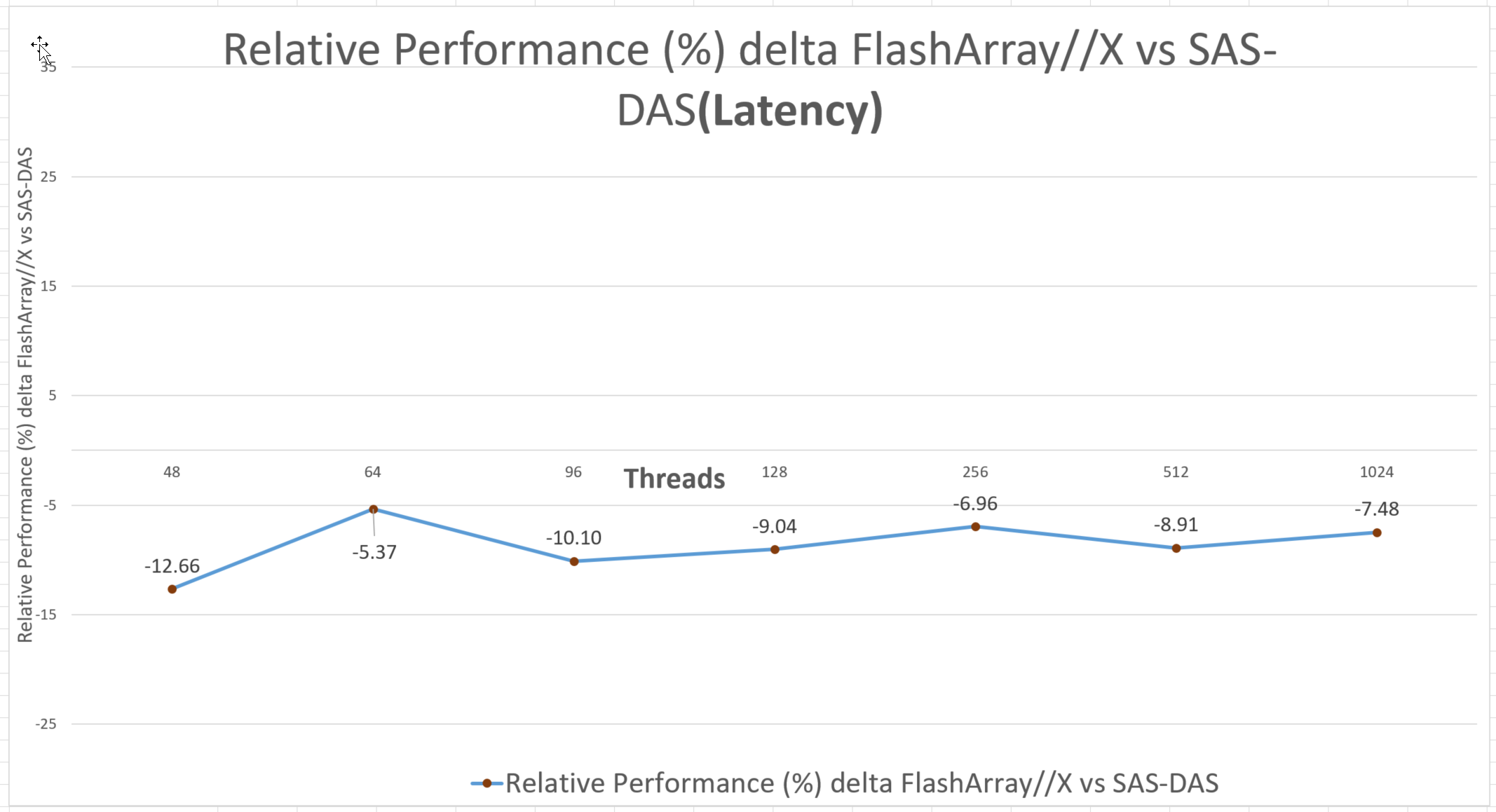
Figure 4. Latency comparison of PostgreSQL on FlashArray//X R3 vs. SAS-DAS
Summary
As our testing demonstrates, the performance of PostgreSQL 12 on the FlashArray//XR3 is better than it is on a comparable SAS-DAS system. While known for providing sub 1ms latency and strong, consistent performance for database workloads, FlashArray//X provides additional rich enterprise features that you won’t usually find with DAS. These include:
- industry-leading data reduction
- efficient snapshot technology
- proven 99.9999% availability
- robust business continuity and disaster recovery options, included at no additional cost
Based on these results, we believe Pure Storage FlashArray//X is a better choice than DAS for PostgreSQL database workloads. Learn more about our third generation FlashArray//X if you want to avoid the complexity, cost, and availability disadvantages typically associated with siloed DAS architectures.
More About FlashArray//X R3
- Product page: Learn more about how FlashArray//X can help simplify your work life.
- Blog post: Improving SAP HANA Performance—Again
- Blog Post: Pure FlashArray Outperforms DAS!
- Blog Post: Comparing Customer Experiences with FlashArray//X Competitors
- Blog Post: Accelerate Oracle Database with the Next-Gen FlashArray//X



