

$1,200. It’s roughly the market value of 20 barrels of oil or an ounce of gold. It’s also how much a single end user’s data is worth, in a study published a few years ago. It’s likely worth significantly more now. At this incredible rate, most enterprises are literally sitting on a gold mine.
Over a century ago, gold miners from all over the world rushed to California for the faint possibility of striking it rich. They labored tirelessly in streams and rivers hoping to find gold nuggets hidden in river beds. Their preferred tools were pots and pans. Since then, technology has evolved, and miners are much more efficient with modern tools to analyze seismic sensor data, as well as drills and explosives.
In the same way, the world of data has clearly evolved. Fact is there’s been a dramatic shift in the nature of data and the types of tools available to analyze (or mine) it. Yet most data scientists, engineers, and researchers are using infrastructure of the old era, the equivalent of pots and pans to mine their data, leading to frustration for data scientists, constraints and complexity for data architects and delayed results for business units.
Modern data pushes beyond the limits for which legacy technologies were designed. A modern approach demands an architecture that is real-time, dynamic and massively parallel, and when, data scientists are given the right platform to build on, like Man AHL did (more on this later), it can be a game-changer for the organization. Let me explain.
The Work that Sparked Hadoop and Big Data Analytics
In 2003, Google published a seminal paper titled “The Google File System”. This paper, in combination with another on MapReduce, inspired the creation of Hadoop and the Hadoop File System (HDFS) which spawned a multi-billion dollar industry and forever changed the course of history for big data. For the first time, the world was given a recipe to tap into massive amounts of data for insight using a relatively simple programming model.

The Google File System and HDFS were built around certain assumptions about the nature of data. The paper articulates these following assumptions:
- Large files: “Multi-GB files are common”
- Sequential access: “Applications mostly read and write large files sequentially”
- Batched workload: “Most of our target applications place a premium on processing data in bulk at a high rate, while few have stringent response time requirements”
- Component will fail: “Component failures are the norm”
The obvious tool of choice given these assumptions was distributed direct-attached storage (DDAS) in server nodes. DDAS are built for handling large files sequentially, yet they are poor at handling random, small file access. DDAS can deliver high bandwidth for batched workloads when many disks are aggregated together, yet are not performant for real-time workloads. Since the network was assumed to be slow (see our view on this), moving compute to be directly adjacent to and tightly coupled with storage seemed logical, even though such an architecture brings complexity, scaling, cost and agility challenges. All together, the trade-offs were necessary and worth it at the time.
Modern Data Changes Everything
We are in a new era, fueled by a surge of real-time applications and AI, and the modern gold rush is just getting started. While Hadoop was the only widely available analytics tool a decade ago, data scientists have a plethora of tools at their disposal today. Apache Spark is a real-time, streaming framework that’s simpler and more powerful than Hadoop. Kafka is a real-time messaging tool for any file sizes, small or large. Hive offers a SQL-like interface that results in random, not sequential, accesses. And the list goes on.

The mother lode of modern analytics is machine learning and AI. Jeff Bezos, CEO of Amazon, stated, “AI will empower and improve every business. Basically there’s no institution in the world that cannot be improved with machine learning.” New tools like TensorFlow and Caffe2 give data scientists new superpowers they did not have access to before.
The driving force behind this sea change in big data is a simple truth. The explosion of new technologies, industries, and perhaps the fourth industrial revolution, is fueled by novel tools built around the singular fact that unstructured data is indeed unstructured- it takes on many different and ever-changing forms. Big data is no longer large, sequential, batched, and fixed, as mandated by the DDAS model. For machine learning training, the assumptions about data are the polar opposite of those underlying the traditional HDFS and DDAS architecture. Training data must be accessed randomly, not sequentially, and files are often small in size.
Data is now truly dynamic. And a new class of data platform is needed, one that is built for the needs of modern, dynamic data – and architected for the unknown.
Your Data Scientists (and Your Business) Deserve Modern Tools
Infrastructure is a tool for data scientists and engineers. It drives innovation in products and insights in business data. However, picking an outdated tool is analogous to using pots and pans to mine for gold today.
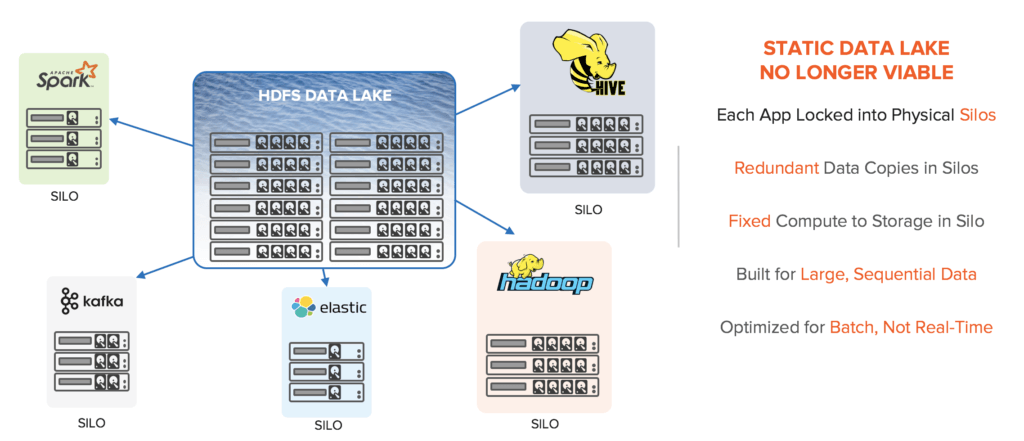
Unfortunately, most IT organizations are stuck in the middle of this transition. Their data scientists want to benefit from modern tools but their infrastructure is outdated – built with HDFS on DDAS and yielding a sprawling, complex network of application silos. With DDAS, data scientists are ill-prepared for modern workloads like machine learning and Spark. In fact, DDAS is the antithesis of what one would build for machine learning because data needs to be accessed randomly across the entire dataset with consistent latency and throughput.
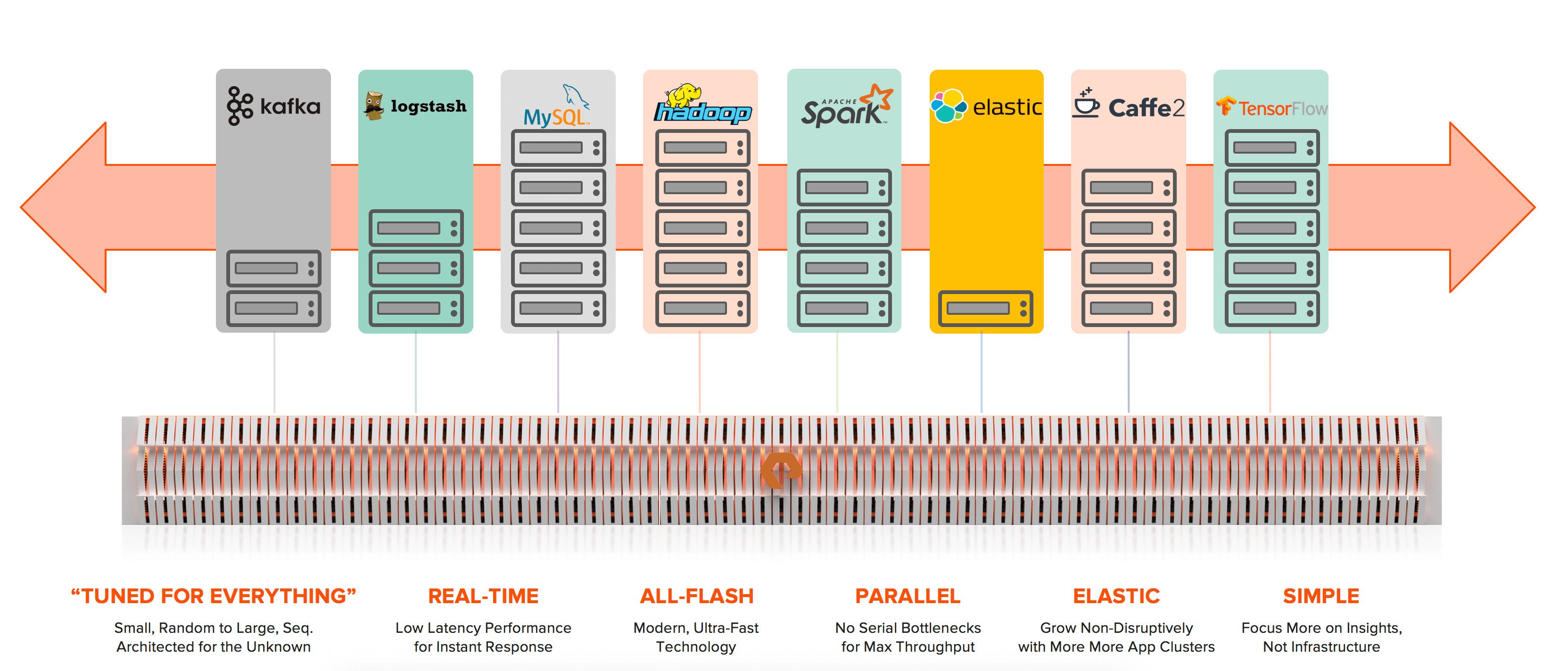
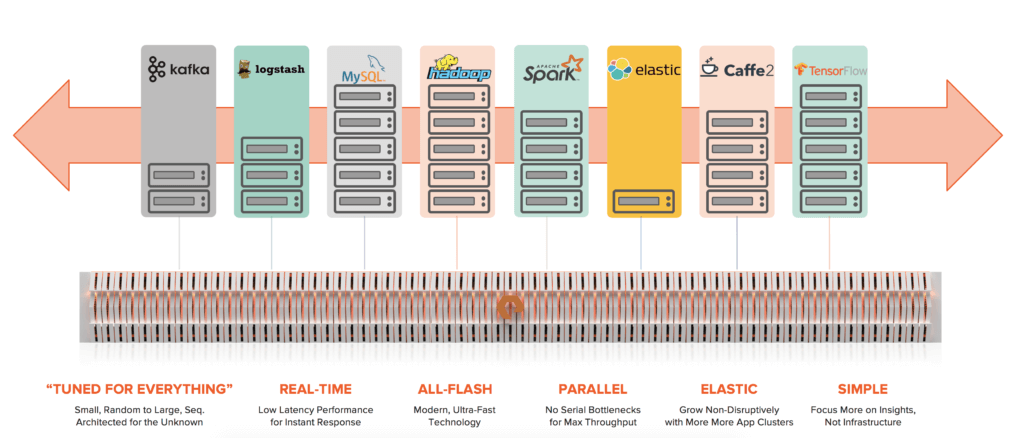
The modern era requires a dynamic data hub on which any workload can grow on-demand, in compute or in capacity, delivering the highest performance for any unstructured data. It must have these six key qualities:
- Tuned for Everything: unstructured data can have any size, form, or access pattern and the data hub must deliver uncompromised performance for any data
- Real-Time: many modern applications, like Spark, are designed for streaming data
- All-Flash: dramatically faster than spinning, mechanical disks, with random, low-latency access
- Parallel: from software to hardware, data hub should be massively parallel end-to-end, without any serial bottlenecks
- Elastic: today’s tools are built cloud-first and assume infrastructure is agile and elastic like cloud
- Simple: researchers and engineers want to focus on data, not managing infrastructure. This means easy administration, but also rock-solid, proven reliability, resilience and availability.
Data analytics toolsets are evolving rapidly. By the time an infrastructure is built out to support them, it may already be outdated. In just a few years, three different approaches have been designated the standard of big data.

What if you could simply deploy a new type of storage infrastructure able to handle the dynamic nature of modern data and analytics? Such a storage system had never been invented before, simply because architecting for the unknown is a difficult, if not a nearly impossible, proposition.
FlashBlade®: Industry’s First Data Hub for Modern Analytics
FlashBlade is the industry’s first and only purpose-built, dynamic data hub for modern analytics.
FlashBlade is tuned for everything. It handles small, metadata-heavy to large files, random or sequential access patterns, up to 10s of thousands of clients all requiring real-time response, without the need to constantly retune the storage platform. From the ground-up, hardware to software, it is built with a massive parallel architecture to deliver maximum performance for any modern workload today and in the future.

FlashBlade allows data pipelines to grow dynamically with the needs of the data science and engineering team. By disaggregating compute from storage, each application can grow elastically with just the right amount of compute and storage, like one would expect from a cloud service. Teams can quickly spin up, or tear down, application clusters in minutes, without waiting weeks for a new DDAS silo to be built out. FlashBlade performance eliminates data access bottlenecks and data duplication across silos.
10x Faster Apache Spark for Man AHL
Man AHL is a quantitative systematic investment management company, with more than $19 billion in assets under management. The firm’s investment decisions are based on mathematical models running on computers, without human involvement. With roughly 50 data scientists relying on the tools that IT provides, they decided to build their infrastructure on FlashBlade.

“Many of our researchers have found that the introduction of FlashBlade has made it easier to use Spark for performing multiple simulations. One of them experienced a 10x improvement in throughput for his Spark workloads compared to the previous storage system,” said James Blackburn, Head of Data Engineering. It is a game-changer that creates time-to-market advantage for the company.
Try FlashBlade for Data Analytics
While DDAS architectures were appropriate in the early days of big data and analytics, the modern era requires a new class of dynamic, scale-out storage, a data hub built for unstructured workloads with cloud-service-like agility and simplicity. FlashBlade is purpose-built for modern analytics, powered by a massively parallel architecture from end-to-end.
To learn more, please visit us here or contact us with any questions. We’re excited to see how you will modernize your infrastructure, and empower your data scientists and researchers to push the limits of what’s possible for your organization.



