

Dell EMC World highlights the strikingly different product vision, strategy, and architectural approaches that Pure and Dell EMC are taking in the digital and cloud era. And those differences create a sharp contrast for customers. In this blog, we’ll compare the newly announced XtremIO X2 and VMAX All-Flash 950F model to the new (and more orange) X in town, our FlashArray//X. We’ll illustrate the important differences and help you evaluate which products are ultimately deserving of your Tier 1 application workloads.
At a high-level, Dell EMC has refreshed and released two potentially overlapping products, and we applaud them for clarifying what each is for: VMAX for tier 1 workloads and consolidation, and XtremIO for point VDI and snapshot heavy environments like test & development (test/dev). In our view this is a rational position – VMAX where reliability trumps efficiency, and XtremIO where efficiency (via purpose-built data reduction) trumps reliability. The challenge now is that, in the cloud and digital era, enterprises (rightly) demand performance, reliability, and efficiency, without compromises, and without having to manage two independent silos of storage. With VMAX All-Flash and XtremIO, it seems you have to settle for two of the three. With Pure, you get all three.
Summed up in one word, this announcement feels incremental. The hardware upgrades are just point bumps to each product line, but nothing that actually changes the game. Both platforms get a bit bigger and faster, but in both cases, this new hardware bump didn’t bring NVMe, which is needed to unlock new levels of performance, density, and efficiency and is a gaping hole in a much anticipated 2017 hardware refresh.
Both product lines are still not Evergreen. The apparent lack of upgradability from previous models to the newly announced model means forklift upgrades once again remain an unfortunate and costly reality on both XtremIO and VMAX All Flash arrays. And, the implicit absence of XIOS 6.0 availability on X1 hardware, and the inability to mix X1 and X2 bricks, is frankly indefensible at this stage. It further erodes the investment protection of XtremIO’s Brick-based architecture by limiting access to software innovation to an install base that has tolerated a stand-still on hardware advances for the past two years. This has a direct and negative impact on the customer. It’s also striking that these releases left the software behind. No new VMAX features. XtremIO has a few, but all in “tech preview,” with no articulated dates for DA or GA delivery.
Net-net, neither product refresh seems to solve the core issues that are driving customers to alternatives:
- VMAX: Inefficient, complex, and expensive. It’s now just a bit bigger/faster version of the same thing.
- XtremIO: Apparently unreliable for Tier 1 workloads. Getting rid of the batteries isn’t enough.
- Both: Still not Evergreen, and no articulated upgrade path to NVMe.
At Pure – we recently introduced FlashArray//X – the new 100% NVMe version of FlashArray. It brings Tier 1 performance, reliability, and effortless efficiency – without compromise. And, not only is it available as an Evergreen upgrade to existing FlashArray customers, but also as an Evergreen on-ramp via our new NVMe NOW! program for Dell EMC customers who are seeking a modern storage ownership experience. You can take an //X for a spin, compare it head-to-head with the latest generation VMAX or XtremIO, and experience the difference for yourself!
For those interested in checking out our deeper evaluation, please read on…
Before we evaluate the products in detail, let’s first consider the product dimensions that are critical to truly modernize, support new and existing apps, and drive both business and IT transformation in the cloud era:
- Evergreen: Like IaaS and SaaS, you want a subscription to innovation that lets your storage continue to get better for a decade (or more) – without requiring any infrastructure re-buy, data migration, or disruption.
- Resiliency: Nothing less than always-on and always-fast will do for mission-critical applications.
- Scalability: Start small and grow capacity or performance, flexibly, non-disruptively and independently.
- Efficiency: Leverage data reduction to actually reduce the cost of storage and further extend the useful life of flash.
- Simplicity: Cloud demands simplicity. You must automate, and you can’t safely automate what’s complex.
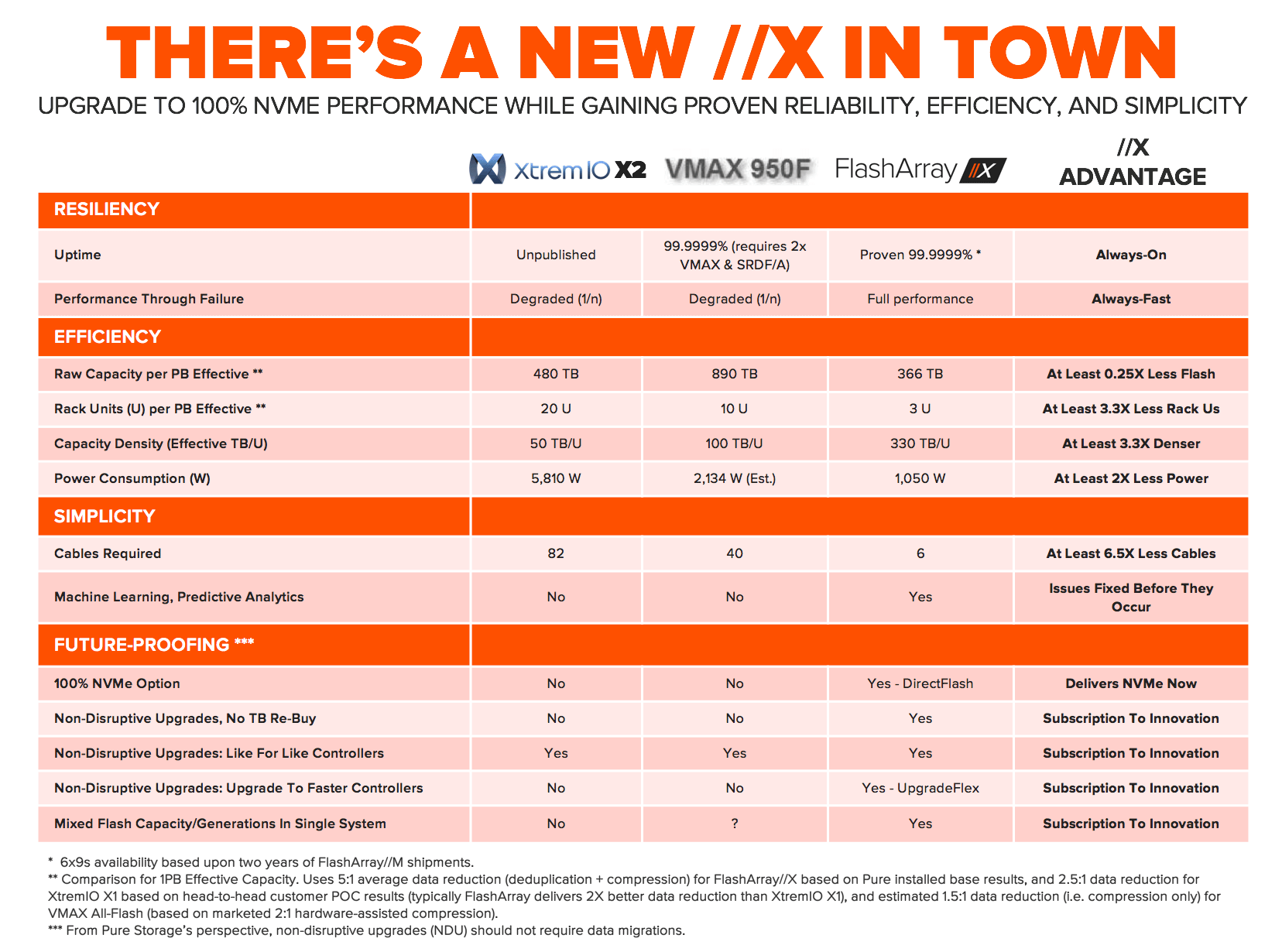
Providing a framework for the subsequent evaluation, Figure-1 below depicts a comparison, from Pure’s perspective, of the all-flash storage arrays discussed herein:

1. Still NOT Evergreen: Future proofing and forklift upgrades remain a costly challenge on both XtremIO and VMAX
X1 and VMAX do NOT appear to be upgradable to X2 and VMAX 950F. While not surprising as it has been the practice of Dell EMC since the inception of these products, it would mean that Dell EMC customers must continue to undertake “forklift” upgrades: re-buy hardware and software, start a new cluster, and migrate the data to upgrade to the new models. The silver lining is that every forklift is an opportunity for customers to evaluate industry-leading alternatives, such as FlashArray//X.
No NVMe support. In the cloud era, there’s no room for legacy disk protocols like SCSI and SAS. You need fast connections with fast protocols (NVMe) combined with global flash management to get to the next level of performance, density, and efficiency. With the recent termination of DSSD, many had wondered how VMAX (and XtremIO) might possibly leverage Dell EMC’s acquired NVMe knowhow and proprietary technology – “maybe in the future” seems to be the response. X2 and VMAX All-Flash still use SAS and SSDs. While the VMAX All-Flash models support NVMe-enabled vault drives, these are not in the normal IO path, where NVMe is needed to unlock its real benefits. In contrast, FlashArray//X offers 100% NVMe for mainstream Tier 1 deployments today. In 2017, buying an AFA without full NVMe support (or non-disruptive upgradability to full NVMe) is like throwing away your investment. Get to NVMe with the NVMe Now! program.
XIOS 6.0 does NOT appear to be backwards compatible to X1. According to the XtremIO X2 spec sheet, XIOS 6.0 is released on X2 hardware, implying it is not available on X1 hardware. This is atrocious and demonstrates a lack of commitment to their X1 customers, especially given EMC’s stated intentions after the data destructive upgrade from XIOS 2.4 to 3.0. It seems that many thousands of X1 customers may be stranded on XIOS 4.x software – unable to take advantage of the software enhancements (however minor) in XIOS 6.0 and future versions. Can you say (XpectMore) #XpectLess? Combined with the apparent lack of an upgrade path to X2, customers need to carefully consider the risks to buying X1 today. Existing X1 customers should ask Dell EMC when (or if) key XIOS 6.0 features will be back ported to XIOS 4.x. If not, we doubt Dell EMC will provide a free upgrade to X2 – but they should. In stark contrast, with our Evergreen Subscriptions, we can proudly say that not a single Pure customer has been left behind since the initial GA shipments in 2012 – and we’ve delivered five major software releases during that time.
Are VMAX 450F/850F models going EOL? VMAX 250F/950F models employ 7.68TB and 15.36TB SSDs, Intel Broadwell CPUs, and 12Gb/s SAS-3 back-end shelves, whereas the VMAX 450F/850F models, which GA’d just over a year ago, remain stuck on lower capacity SSDs, older CPUs, and 6Gb/s SAS-2 back-end shelves. Moreover, the featured video on Dell EMC’s All Flash webpage states that VMAX All-Flash is available in only two models: VMAX 250F and 950F, another indication that VMAX 450F and 850F are likely near the end of the sales cycle. And, with no upgrade path from VMAX 450F/850F models to the VMAX 950F without a hardware and capacity re-buy and data migration, buying a VMAX 450F/850F today is equivalent to firing up the forklift.
X2 remains stuck on two-generation old CPUs. Why release an array today that uses 3-year old CPUs? X2 will lag behind with its use of Haswell CPUs. Combined with the two year hiatus on new XtremIO hardware introductions, you should pause and ask Dell EMC if they are truly committed to XtremIO. We recommend you ask when Broadwell-based X-Bricks will be available, and whether a forklift upgrade will be required to get there. In comparison, the Pure FlashArray//X uses Intel Broadwell CPUs and we have a proven history of introducing newer Intel CPU-based controllers every 12 to 18 months. Combined with Evergreen Subscription, Pure customers have rapid access to advances in CPUs (and flash) – all non-disruptively.
2. Tier 1 resiliency unproven on XtremIO
99.9999% uptime seems elusive for XtremIO. While the Dell EMC website has continued to market XtremIO as a highly-available architecture, we have heard many customer stories of upgrade challenges, downtime, and basic resiliency issues with XtremIO in the past. This may be why XtremIO’s uptime stats remain unpublished.
IO path on X2 is completely new. With X2, IOs are committed to NV-RAM vs. flash with X1. The architecture appears to be so different that the XIOS 6.0 software may not even work on the previous-generation X1. This is a v1.0 product! Hardening storage products is hard, time-consuming work. It took X1 4+ years just to get where it is today, and it looks like the clock is resetting. In comparison, the Pure FlashArray//M has proven, measured 6 9s across our install base now coming up on two years, and it’s inclusive of maintenance and upgrades. Your applications are always-on with FlashArray.
3. Scaling with Brick-based scale-out is complex and costly
Each expansion Brick requires the same number of SSDs. While you can scale-up and scale-out on X2, the need to have the same number of SSDs on each X-Brick poses a major scaling challenge: scale-up the first X-Brick to 72 drives and then you must expand using “monster” (i.e. 72 drive, ~3x larger than X1) X-Bricks …or… scale-out first to multiple X-Bricks and pay the controller tax per X-Brick just to expand capacity. These exact same challenges apply when scaling V-Bricks on VMAX All-Flash models. While good for Dell EMC, either scaling option collects a “Brick-based scale-out tax” from you. With the Pure FlashArray, customers can expand capacity (by adding Flash Modules) or performance (by upgrading controllers) independently, non-disruptively, and without these tradeoffs.
Different Brick models are NOT mixable / upgradable to other Brick models. X2 is available in two models: X2S (uses 400GB SSDs) and X2R (uses 1.92TB SSDs). Similarly, VMAX All-Flash is available in four models: VMAX 250F, 450F, 850F, and 950F (assuming the 450F and 850F are not soon EOL’d). Once you start with a given Brick model, you can scale-out only with that Brick model. For example, if you start with X2-S, you scale with X2-S. Getting to X2-R is a forklift upgrade from X2-S. Similarly, if you start with VMAX 450F V-Brick, you scale with 450F V-Bricks. Getting to VMAX 950F is a forklift upgrade if you want to expand performance or capacity. Software migration packages are simply not equivalent.
To us this all reads like a complexity nightmare. Imagine the planning, execution, and budgetary difficulty of trying to manage a reasonable sized fleet! With the Pure FlashArray, you can start anywhere (even with the entry model //M10) and scale non-disruptively, without data migration, and in an investment protected manner all the way to //X. That’s what we mean by effortless – as infrastructure-as-a-service on your premises should be.
4. Over-promise and under-deliver: creative data efficiency claims
Dell EMC 4:1 Data Efficiency Guarantee requires thin provisioning and snapshots. Dell EMC claims that it will guarantee logical usable capacity of at least 4x the usable physical capacity, after applying deduplication, compression, RAID tiering, thin provisioning, and snapshots. Accounting for dual-parity RAID overhead, this guarantee equates to ~5.3:1 total reduction on VMAX All-Flash and ~4.5:1 total reduction on XtremIO, based on stated usable physical capacity. In comparison, FlashArray delivers average 11:1 total reduction (dedupe + compression + thin provisioning) and 5:1 data reduction (dedupe + compression) or 2x+ more than VMAX All-Flash or XtremIO. But, more importantly, it’s ridiculous to claim data efficiency with the inclusion of thin provisioning and snapshots. Little to no efficiency benefits can be gained in today’s already thin provisioned storage world. And, counting snapshots for data efficiency is simply misleading: the mere act of creating snapshots doesn’t increase data efficiency one iota. “Data efficiency” guarantees thus create significant risk of undersizing an array to hold the data it’s supposed to hold. This is why the Pure Right-Size Guarantee leverages data reduction (dedupe + compression), not total claimed efficiency – and guarantees your effective capacity in TBs, which is the outcome you need
Data reduction remains limited by metadata. While Dell EMC claims that compression has been enhanced, X2 uses the same 8K fixed metadata architecture as X1, which limits achievable data reduction results. Fixed metadata misses any duplicates that are not an exact 8K match. Even 8K duplicates are missed unless the database / VM / file system has been tuned to align at the 8K boundary. And, while compression was introduced on VMAX All-Flash last fall with the use of bolt-on compression I/O modules, VMAX All-Flash metadata was simply not designed for data reduction. As a result, dedupe still remains notably absent on VMAX All-Flash. With the FlashArray’s 512Byte variable data reduction, customers achieve average 5:1 data reduction (dedupe + compression) across the install base – that’s typically 2x better data reduction than XtremIO based on customers comparing real-world workloads. And, while we compete and win plenty against VMAX All-Flash, we have yet to see customers turning on VMAX All-Flash compression. Net-net, the Pure FlashArray can deliver up to 5x better data reduction than VMAX All-Flash. The end result is Pure saves you a lot of flash.
Capacity density at the cost of performance. Unlike the 450F/850F models, VMAX 250F and the new VMAX 950F support “Big SSDs” (i.e. 7.68TB and 15.36TB SSDs), which are used to increase capacity density (TB/U). However, Dell EMC performance best practices specifically state that:

Consequently, Big SSDs, like the 15.36TB SSD, compromise tier 1 workload and consolidation performance to deliver capacity density. XtremIO’s CTO has said that “[p]eople don’t realize, [that] the larger the drive capacity gets, the worse the performance gets” and that the XtremIO team was “not willing to sacrifice our predictable performance.” X2-R avoids the performance density challenge (with support for 1.92TB SSDs only) at the sacrifice of capacity density. In comparison, FlashArray//X will be 6x denser than both VMAX 950F and X2, and the DirectFlash technology that powers //X means the capacity density is delivered with full performance. Overall, the density journey on the FlashArray has been phenomenal: whereas it used to take 6 racks for 1PB effective in 2012, //X delivers 1PB effective in 3U – at full performance, with no trade-offs.
5. Retrofit complexity abounds on VMAX All-Flash
While EMC has made efforts to simplify VMAX All-Flash, it’s like managing a VMAX because it is a VMAX. Here’s a sampling of examples that illustrate the VMAX complexity:
- RAID 5 vs. RAID 6 choice has to be decided at time of purchase
- Data-at-Rest Encryption needs to be configured before the VMAX ships, otherwise it requires a system wipe to enable encryption
- BIN files are still present, just hidden from you via out-of-factory configuration
- Compression “ratio” (whatever that means) must be configured by Dell EMC in the BIN file dependent on upfront conversation about application workloads. The point-in-time compression ratio can and (likely) will be mismatched over time with the level of efficiency possible as your application workloads change over time.
- Compression is not always-on; it must be configured manually on a per group level
- Expansions require careful choice between scaling-out or scaling-up at each upgrade period
We hope that we provided an informative perspective. In the cloud and digital era, enterprises demand performance, reliability, and efficiency, without compromises. With the Dell EMC XtremIO and VMAX platforms, customers are asked to settle for two of these three. With Pure, they can get all three with the new (Orange) //X. And, with our Evergreen on-ramp via our new NVMe NOW! program for Dell EMC customers, you can get onto a modern storage ownership experience and make it your last forklift upgrade.



