

We are very excited to introduce DirectFlash™ Fabric which extends the DirectFlashTM family outside of the array and into the fabrics via RDMA over converged Ethernet (also known as RoCEv2). DirectFlash Fabric completely revolutionizes the way applications access a FlashArray and delivers on the requirements for direct attached storage dis aggregation. DirectFlash Fabric is generally available as of January 16, 2019 with a non-disruptive firmware upgrade and installation of a RDMA capable NIC in the storage controlleras.
To learn more, read below.

WHY ENTERPRISES NEED TO DELIVER RESULTS AT THE SPEED OF THOUGHT
In this digital, mobile, modern world, our expectations have increased dramatically and continue to increase day by day. As a society, we expect “results at the speed of thought.” But it has not always been this way. Applications of the past were very serial in nature. Data was inputted, later processed, and then maybe reported later. Today’s applications incorporate parallel processing, machine learning and artificial intelligence. In modern applications data is processed as it it inputted in parallel (such as a Google search), which gives us results in real-time results. This application shift requires a new type of infrastructure that is concurrent and parallel, super low latency and high performance. In the world of storage, this shift is from SCSI (or Small Computer System Interface) created in the 1990s for disk to NVMe (or Non-Volatile Memory Express) created for Flash. This shift brought data closer to the processing unit and in turn closer to the application as an enabler of real-time access to data. But unfortunately for enterprises, most storage arrays available today are legacy SCSI solutions built on disk technology for serial applications. This fact makes delivering real-time instant access to data is very challenging for the enterprise.
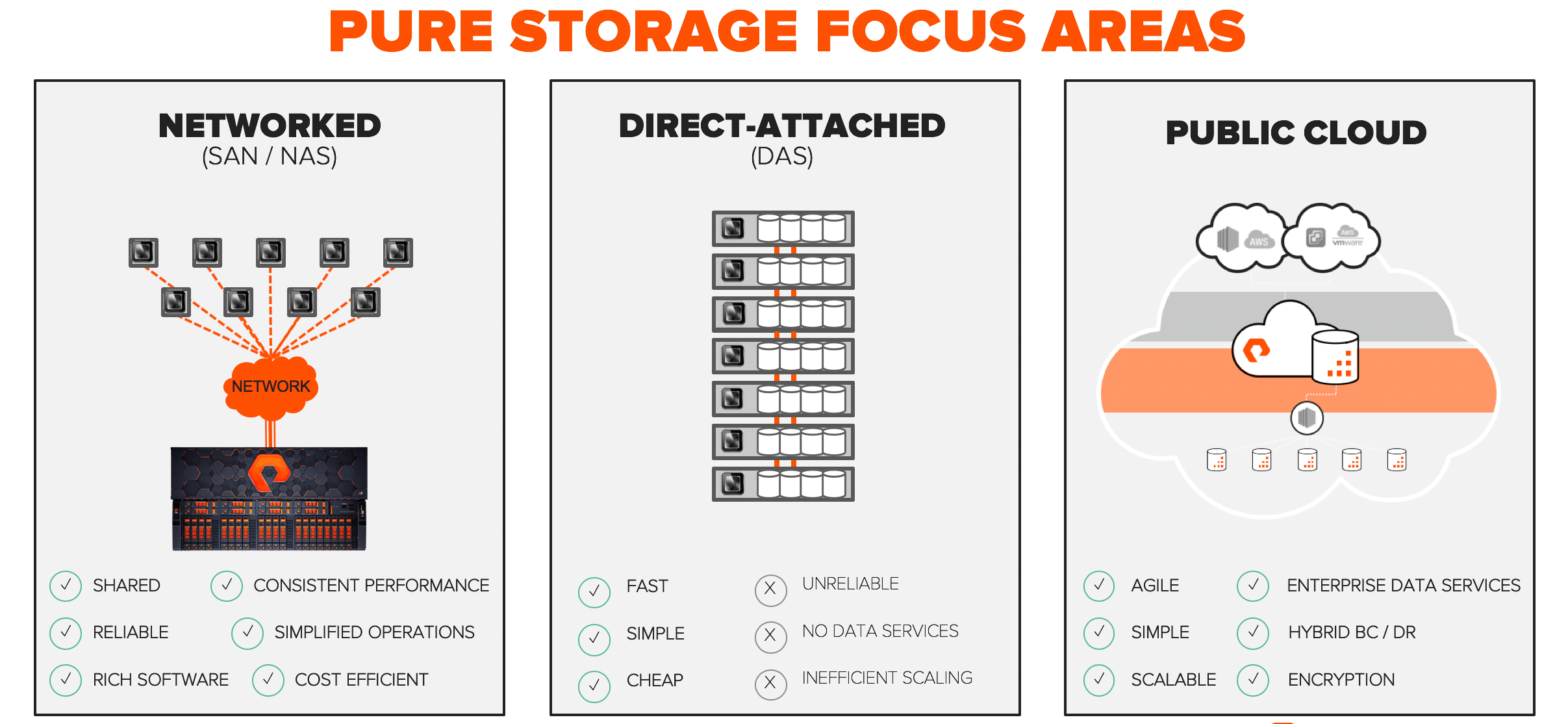
Worse yet, applications that process this data have very different requirements, which created silos. Each application required it’s own tailored storage architecture resulting in different user experiences. At Pure we focused on alleviating the challenges of networked storage (SAN and NAS) with FlashArray™ and FlashBlade™ by building a product from the ground up on flash, not disk. We recently debuted Cloud Block Store, a new series of cloud data services to enhance the public cloud. But, we didn’t focus much on DAS which runs many of the analytics and highly concurrent applications of today.
DAS PRESENTS MANY CHALLENGES, HYPERSCALERS MOVED TO DISAGGREGATION

DAS is typically deployed on standardized servers in a web-scale like fashion. Standardization makes deployment easy, but unfortunately applications come in different spaces and size of compute and storage which results in stranded capacity and CPU everywhere. Stanford and Facebook produced a flash disaggregation study based on Facebook’s infrastructure, in 2015. This study detailed utilization of flash capacity, read throughput, and CPU across their infrastructure and found huge inefficiency. Data services such as snapshots, replication, global deduplication, and thin provisioning don’t exist in DAS architecture leading to further inefficiencies in capacities and operations.
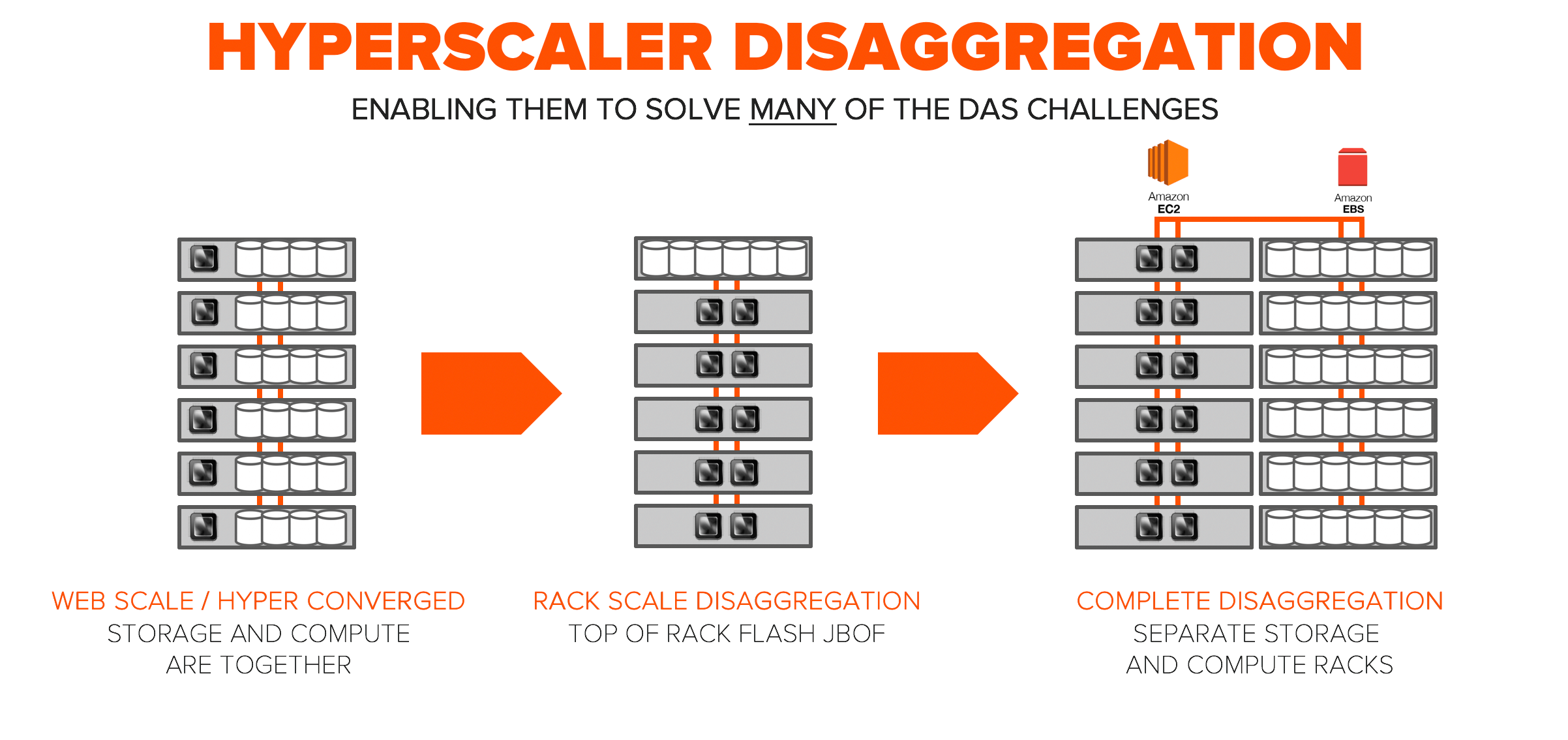
At hyperscale, efficiency is a requirement. In the beginning, there was “web-scale”. This was the simple and easy way to scale. Our hyper-converged friends are still in this early evolution. As you saw with the Stanford Flash Storage Disaggregation study, this type of architecture was immature and equates to high levels of inefficiency at scale. To enable independant scale of compute and storage many hyperscale environments went to “rack-scale disaggregation.” This kept the ability to stamp out a standard rack for scale, but brought in new efficiencies. Complete disaggregation is moving storage and compute to completely separate racks which is accessed by highly optimized protocols and give them the best efficiencies at ultra-scale.
While disaggregation might sound obvious now, there has always been a huge hurdle in place for shared storage:
- Delivering the same performance results as direct attached storage (sub 300 microseconds)
- Provide low latency over fast Ethernet, as fibre channel is not an option in most of these hyperscale solutions.
DIRECT FLASH FABRIC OPTIMIZES APPLICATION ACCESS
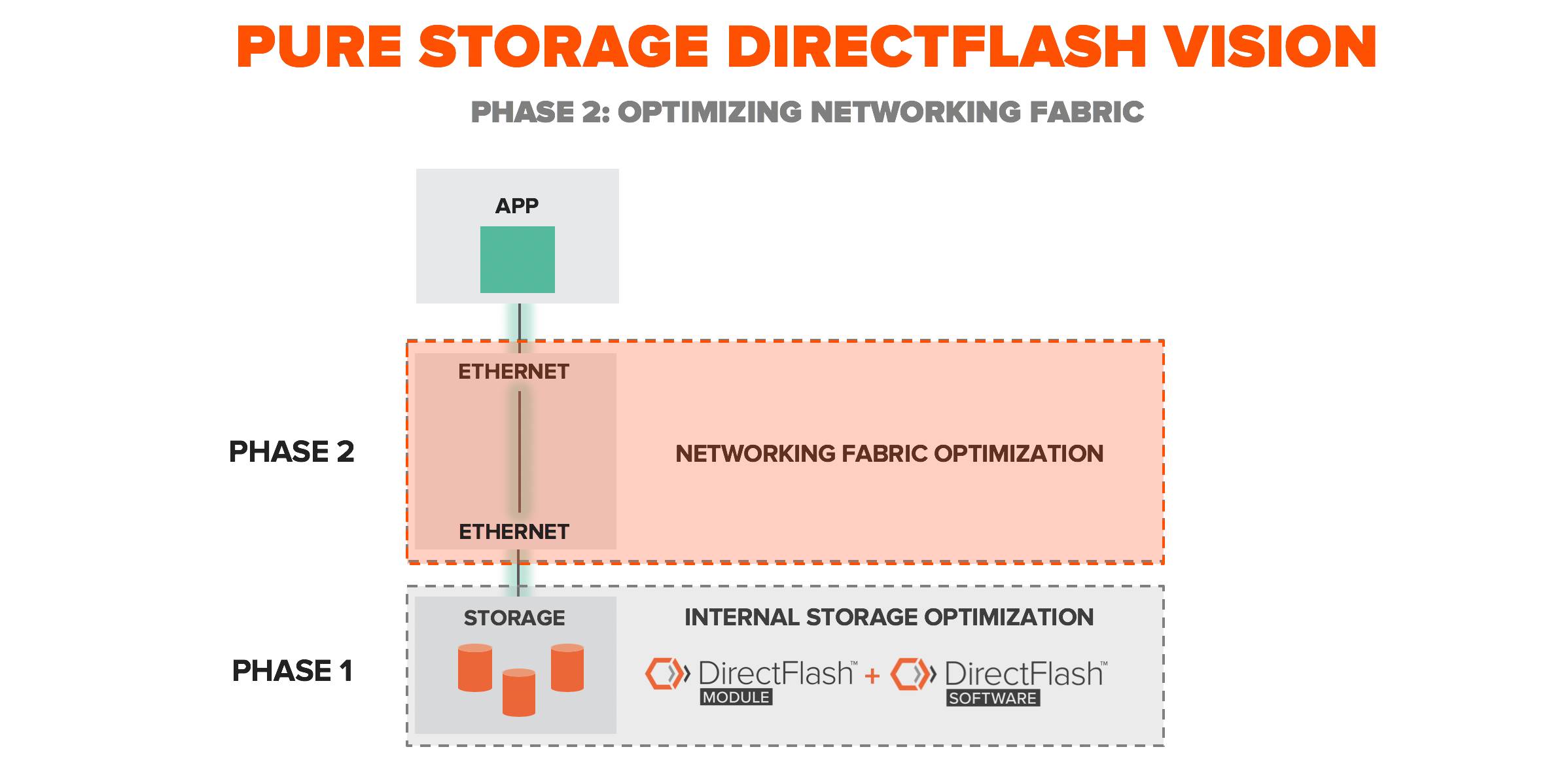
Getting to super low latency isn’t easy with enterprise class data services. Our vision at Pure was to remove all the legacy protocols out of the array first, as this is where the biggest bottle neck exists. We developed two new innovations to support this, DirectFlash™ Module (our own custom NVMe based SSD) and our DirectFlash Software (which is a software defined way of interfacing with NAND directly). These brough huge performance gains inside the array and massive benefits to applications. For more information on DirectFlash check out DirectFlash – enabling software and flash to speak directly and DirectFlash Deep Dive. Now, the only thing left between us and the application is the networking fabric.

We are very excited to introduce DirectFlash™ Fabric which extends the DirectFlashTM family outside of the array and into the fabrics via RDMA over converged Ethernet (also known as RoCEv2). This delivers on the requirements for flash disaggregation with super low latency (200 – 300 microsecond access) and end-to-end NVMe which completely revolutionizes the way applications access a FlashArray. DirectFlash Fabric is generally available as of January 16, 2019 with a firmware upgrade and installation of a RDMA capable NIC in the storage controllers. All of which can be completed on an existing FlashArray non-disruptively, with no performance impact, or maintenance window required. We are seeing results that are up to 50% lower latency compared to iSCSI and up to 20% faster than fibre channel, which is known as the fastest fabric for enterprise applications. With the RMDA offload we are seeing 25% CPU offload which gives more CPU to the application for more results.

DirectFlash Fabric is the continuation of Pure’s industry leading NVMe innovation. We were first in the market to create the groundwork for NVMe natively within our platform in 2015 with our NVRAM devices as an enabler to our stateless architecture. In 2017, we were the first to deliver a 100% NVMe all flash array. In 2018, we were the first to delivery an expansion shelf which is NVMe over Fabrics as well as a 100% NVMe portfolio of products at the same cost as our non-NVMe product line. Today, we are delivering the first enterprise class array with NVMe over fabrics via RDMA over converged Ethernet with full data services.

Network fabric optimization with NVMe over fabrics is an evolution. Today, Linux has a solid ratified driver for NVMe over fabrics. Cloud-native applications such as MongoBD, Cassandra, MariaDB, Hadoop, and Splunk have the following characteristics:
- Traditionally deployed on Linux
- Mostly leverage direct attached storage (DAS)
- Run on fast Ethernet networking
- Have lots of inefficiencies at scale
These apps are great initial candidates for NVMe over Fabrics and is why we at Pure decided to focus on RDMA over Converged Ethernet first. Right now, this is where customers will see the greatest benefit and the market is ready for it. Fibre channel will be next when enterprise applications and operating systems are fully supported. Today unfortunately there is minimal support, which makes it less relevant now. We plan to deliver NVMe over fibre channel at the end of 2019 when VMware and other enterprise applications are ready for it. NVMe over TCP will be last and is planned to be delivered in 2020 to bring NVMe to everyone else.
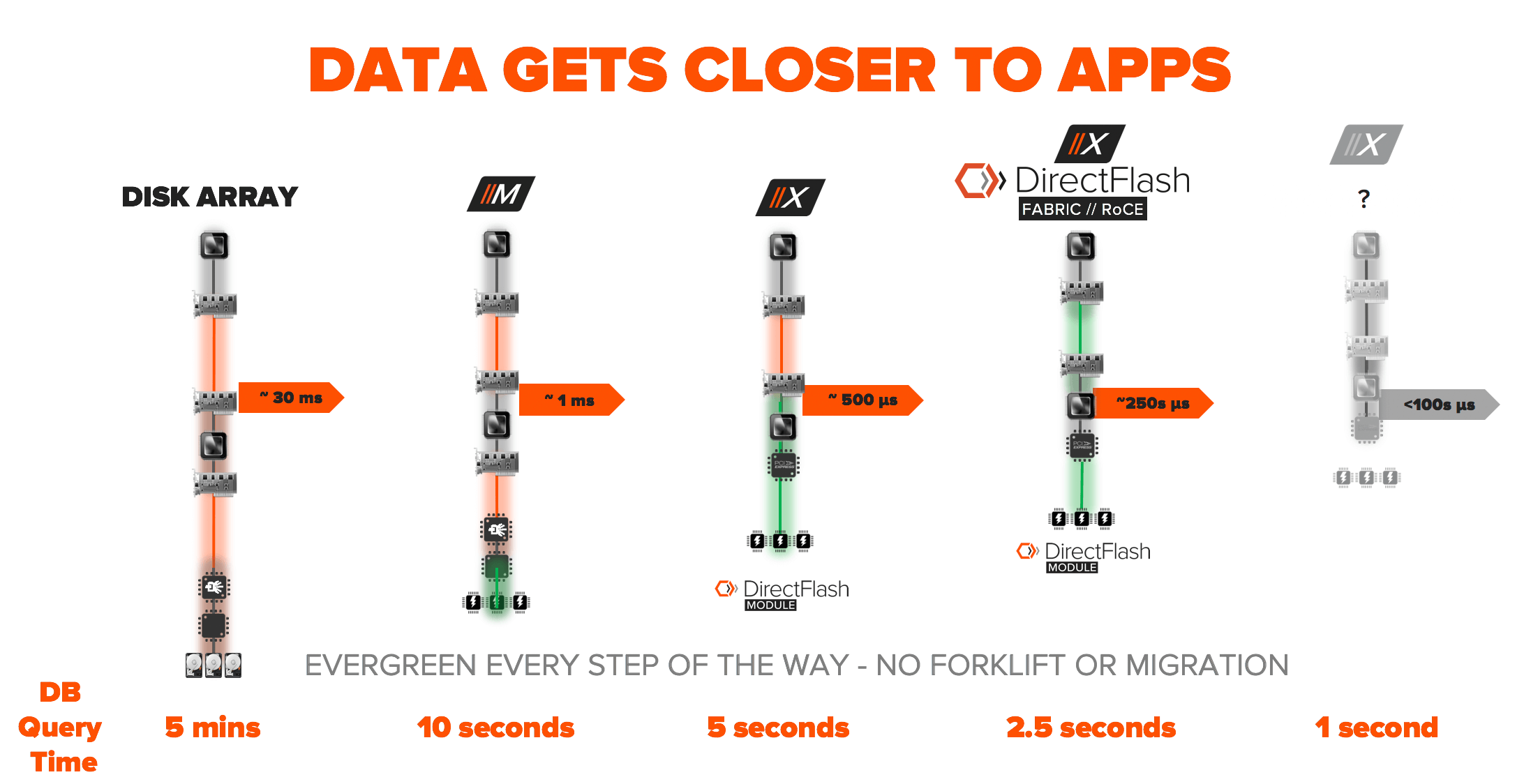
DIRECTFLASH FABRIC BENEFITS APPLICATIONS AND OPERATIONS
Delivering results at the speed of thought is all about getting the data closer to the application. Let’s look at the results of Pure’s technology revolution of completely removing legacy SCSI access and optimizing the entire stack with next generation NVMe technology. Image if you have a database running your backend application, check out the evolution of query response time.
- Disk Array = 5 minutes @ 30 milliseconds of latency.
- All Flash Array = 10 seconds @ 1 milliseconds of latency
- Internal DirectFlash Module / Software = 5 seconds @ 500 microsecond of latency
- External DirectFlash Fabric = 2.5 seconds @ 250 microseconds of latency
This is not the end of the story, we expect that we can get this result down to 1 second (real-time) in the coming year all with full enterprise class data service running at all times. The great part about all of this, is our customers got all the benefits of this evolution without a forklift upgrade or migration. Our Evergreen™ storage consumption model enables customers to get these new features with a firmware upgrade or controller replacement (only paying incremental cost).

Cloud-native applications can realize a serious boost in performance with end-to-end NVMe over fabrics even in comparison to SAS DAS solutions. In our testing, we are seeing:
- Up to 50% better operations per second on MongoDB
- Up to 30% better latency and 30% better operations per second on Cassandra
- Up to 33% more maximum transactions on MariaDB
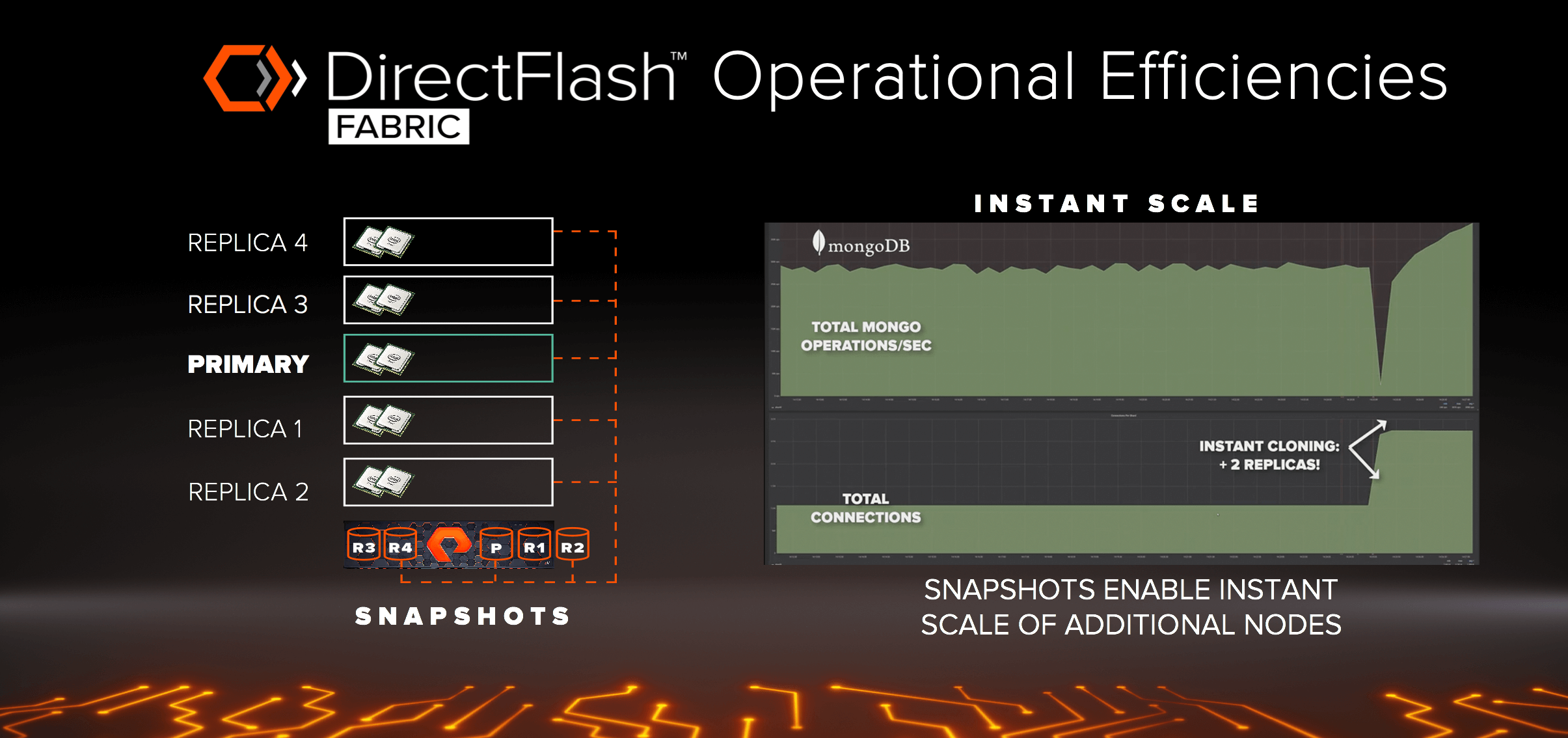
It’s not just about performance. The operational efficiencies with enterprise class shared storage enables new processes that were never possible with DAS. Imagine if you need more read performance and choose to spin up additional nodes for additional performance during a peak period. With DAS, your only option is to add a few more nodes, create new replicas, then wait for hours for them to sync up. With DirectFlash Fabric you can leverage instant snapshots, mount them to the additional nodes, and get instant scale. No additional capacity is required, as the snapshots are space efficient and changes to the snapshot are deduplicated and compressed against the global population of data on the array.
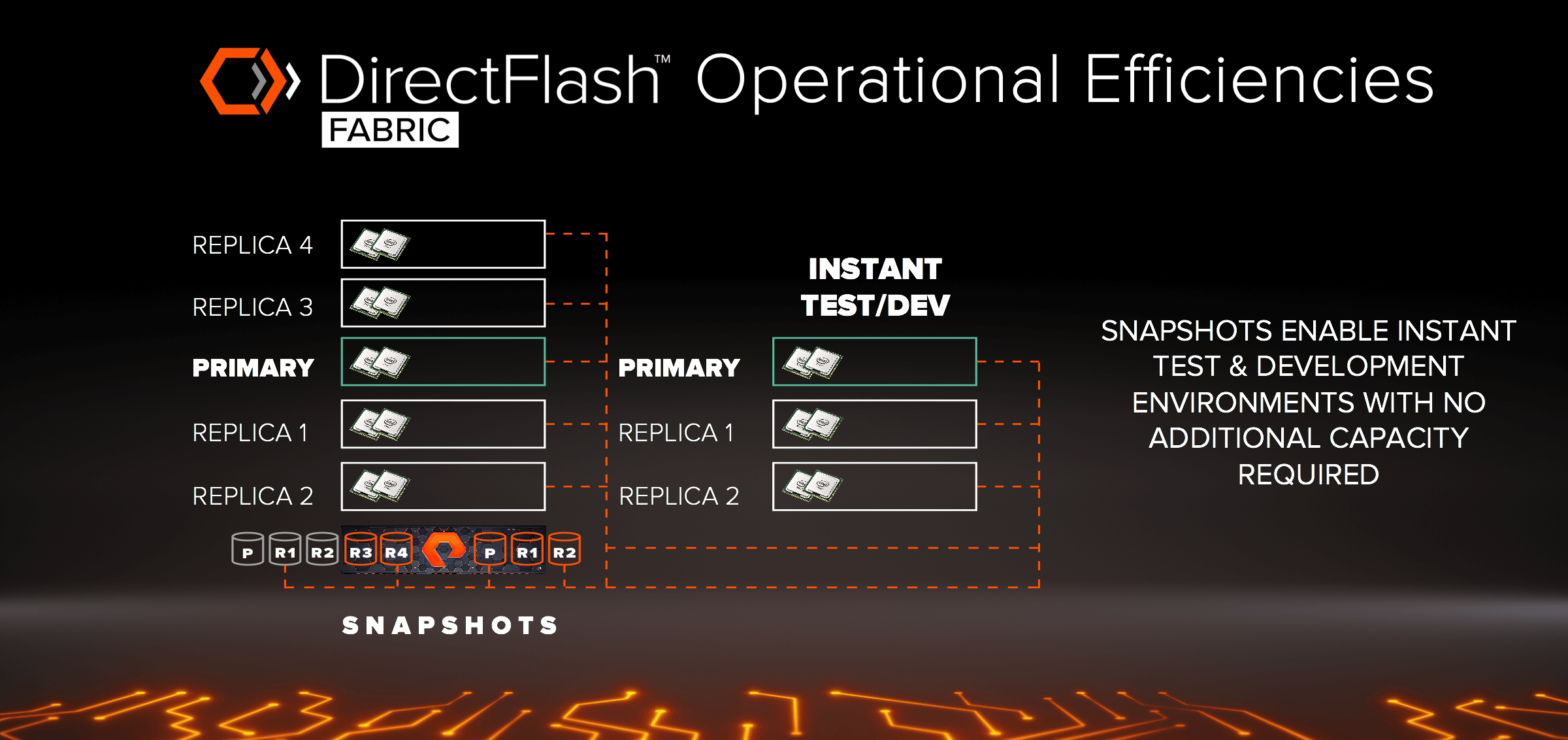
What about spinning up a new testing or development environments based on the current production MongoDB data? With DAS you would have to copy the data or restore from a backup. But with DirectFlash Fabric, you can spin up instances instantly from a snapshot without any impact on production or additional capacity required as well. All of this can be automated via our REST API.

With the disaggregation of DAS with DirectFlash Fabric you can consolidate and remove the stranded CPU and capacity typically found in DAS. This efficiencies include:
- 2 – 4X CPU density with moving from 2 to 4 rack unit servers to 1 rack unit or blade servers. This increases the density of compute to get more results faster.
- 4 – 10X capacity density per rack. FlashArray can pack 3PB of capacity in 6 rack units.
- With a 25% CPU offload makes the density of compute ever more efficient by offloading much of the storage IO work to hardware.
All this is wrapped with enterprise class data services to reduce datasets to the most efficient form reducing costs.

For customers that like to deploy applications via converged infrastructure, we are excited to announce an end-to-end NVMe over Fabric FlashStack™. This includes Cisco Nexus switching, FlashArray//X storage, and Cisco UCS C-Series servers. This makes deploying hyperscale architecture in your private cloud simple and easy to deploy.
ENTERPRISES ARE NOW HYPERSCALE READY

Now all applications can get the benefits of FlashArray and help enterprises delivery results at the speed of thought. For the traditional enterprise applications, our backend NVMe optimization results in huge benefits. For cloud-native apps, our end-to-end NVMe optimizations not only result in serious performance gains, but also brings hyperscale architecture to the enterprise.
To learn more about DirectFlash Fabric, our partner ecosystem, and the benefits to applications, read the blogs below:
- Pure delivers DirectFlash Fabric: NVMe-oF for FlashArray
- Analyzing the Possibilities of MariaDB and DirectFlash Fabric
- Beyond DAS: MongoDB on FlashArray with NVMe-oF RoCE
- Hello Big Data!!! Pure Storage FlashArray with DirectFlash is now Certified with Hortonworks Data Platform v3.0.0
- Benefits of running Cassandra on FlashArray with DirectFlash Fabric
- NVMe-oF Support is Now Released!
- Performance Consistency with FlashArray NVMe-oF and SQL Server Linux
- Oracle 18c runs faster on Pure DirectFlash Fabric
- DirectFlash Fabric vs iSCSI with Epic Workload



