


The primary responsibility of an Oracle database administrator is to ensure non-stop availability of an organization’s Oracle database systems. Oracle DBAs are responsible for normal day-to-day conditions as well as in the event of a disaster that could potentially take an entire data center out of service.
Protect against such unforeseen events by instituting a disaster recovery and business continuity plan. As a cornerstone, establish one or more disaster recovery (DR) sites. Carefully choose and architect DR sites with adequate geographical separation between the sites. At the same time, it’s important to make sure that the network pipe is fast with enough throughput to support the anticipated traffic.
Synchronous replication technologies like Purity ActiveCluster™ enable two FlashArray™ systems running at different sites to appear as a single FlashArray to the initiator. This enables the design of zero-RPO (recovery point objective) and zero RTO (recovery time objective) Oracle database business-continuity solutions. However, since each write operation has to be committed and acknowledged by each FlashArray, the network latency between the FlashArrays needs to be as low as possible (and no more than 11ms in any case) to minimize performance overhead, especially for write-intensive applications.
In some situations, the RPO and RTO requirements are a little more lax, which opens the possibility of using asynchronous replication for DR. Until recently, the only storage option for asynchronous replication was snapshot replication. But now there’s another option.
Announced last week, the next generation of Purity software is the biggest release to date and packed with some really cool technologies—my favorite being Purity ActiveDR™.
What Is ActiveDR?
ActiveDR delivers continuous, near-real-time, replication between two FlashArrays within or across disparate data centers, adding a valuable option to Pure’s overall data protection portfolio. The result is a near-zero RPO that ensures global data protection with minimal data loss. It enables fast failover, recovery, and easy testing of DR processes. Figure 1 depicts an example setup of ActiveDR to continuously replicate to the DR site.
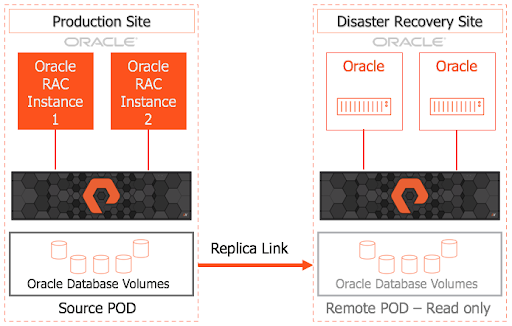
Figure 1
The unit of replication with ActiveDR is called a pod. Think of it as a pod as a logical container. Each pod is a separate namespace and can contain a mix of volumes, protection groups with member volumes, and volume snapshot history. A pod, when created, is in the promoted state, meaning it’s available to the host with read/write access. A demoted pod allows only read-only access to the host. A remote pod must be in a demoted state when a replica link is created.
How Do I Use ActiveDR?
First, create a pod on both the source and remote arrays. On the source array, create a protection group inside the new pod to easily take crash-consistent snapshots of the database’s volumes. Next, move the Oracle database volumes into this protection group within the pod.
Next, to initiate ActiveDR replication, create a replica link from the source pod at the source site to the demoted pod at the remote site.
After the pod is populated with all the volumes belonging to the production database, create a replica link from the source pod to the remote pod. The remote pod immediately starts receiving a stream of compressed data from the source and the items in the source pod start appearing in the remote pod. This initial step is called baselining.
As soon as baselining is complete, the replica link goes into a replicating state. The lag column (Figure 2) shows the lag differential between the pods.
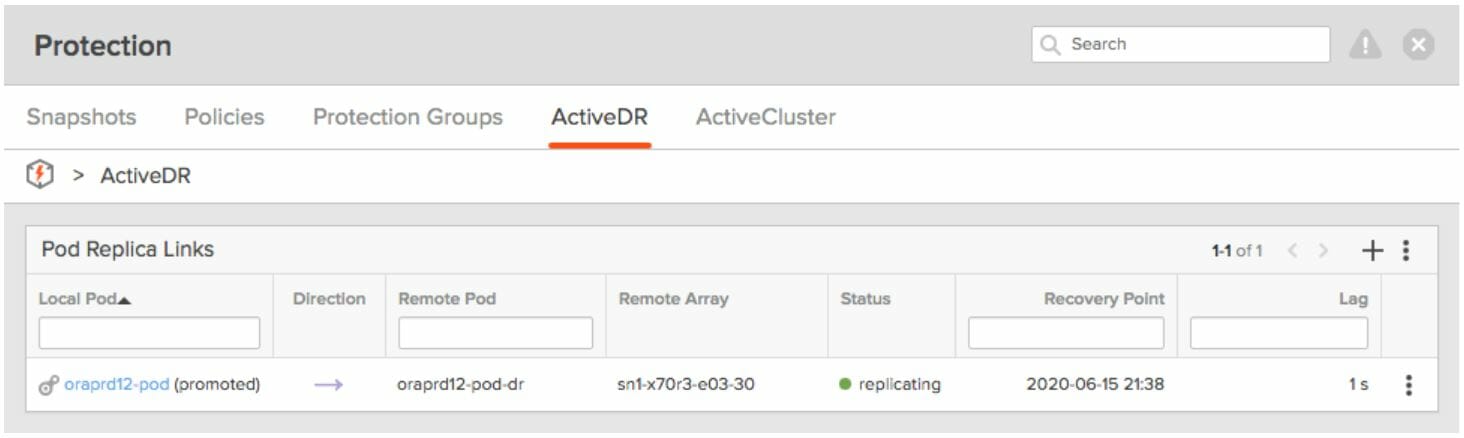
Figure 2
Each array tracks the stream of changes using Purity’s native deduplication and pointer reference technology to efficiently track changes without requiring the additional space of a traditional journal.
At any point, the remote pod can be promoted, which makes it writable by the host with the latest transferred transactions. The hosts can now mount the volumes and you can start the Oracle database at the DR site. The production database on the source array can be up while the database on the DR site is also brought up. This feature can be very useful for testing the DR site without having to do an actual failover. The replication stream will continue to get transferred as before when the remote pod was in a demoted (read-only) state. The changes received from the source array are staged in the journal device but are not applied to the pod while it is in the promoted state.
In case of a disaster at the production site, the administrator will promote the remote pod and the database and applications can be started there. When the primary site comes back online, you can choose either to do a failback or reverse the roles and continue with the DR site as the new production site. The replication direction is reversed by demoting the previously source pod. Note the direction column in Pod Replica Links screenshots (Figure 3).

Figure 3
The protection ActiveDR provides is similar to that provided by Oracle Data Guard running in maximum performance mode.
We have seen how ActiveDR allows the creation of a DR site for Oracle databases. Because ActiveDR replication is continuous and asynchronous, it does not require the remote array to acknowledge every write before confirming it to the host. Therefore there is no performance impact on Oracle database applications due to network latency between the arrays.
Additional Resources
- Proactive Data Protection with Purity
- ActiveDR Data Sheet
- ActiveDR Installation Planning and Best Practices
- ActiveDR FAQ



