

Resumo
This article shows how to seed a database from a SQL instance that is in a Windows availability group into a SQL instance running in a pod in a Kubernetes cluster using a distributed availability group.


Este artigo sobre os grupos de disponibilidade distribuída do SQL Server apareceu originalmente no blog de Andrew Pruski. Ela foi republicada com o crédito e o consentimento do autor.
Há algum tempo, escrevi sobre como usar um grupo de disponibilidade entre plataformas (ou sem cluster) para semear um banco de dados de uma instância do Windows SQL em um pod no Kubernetes.
Eu estava conversando com um colega na semana passada e ele perguntou: “E se a instância existente do Windows já estivesse em um grupo de disponibilidade?”
Essa é uma pergunta justa, pois é bastante raro (na minha experiência) executar uma instância SQL autônoma na produção… a maioria das instâncias está em alguma forma de configuração HA, seja uma instância de cluster de failover ou um grupo de disponibilidade.
As instâncias de cluster de failover funcionarão com um grupo de disponibilidade sem cluster, mas é uma história diferente quando se trata de grupos de disponibilidade existentes.
Não é possível adicionar um nó Linux a um grupo de disponibilidade existente do Windows (confie em mim, tentei por mais tempo do que vou admitir). Portanto, a única maneira de fazer isso é usar um grupo de disponibilidade distribuída.
Então, vamos passar pelo processo!
Aqui está o grupo de disponibilidade existente do Windows:
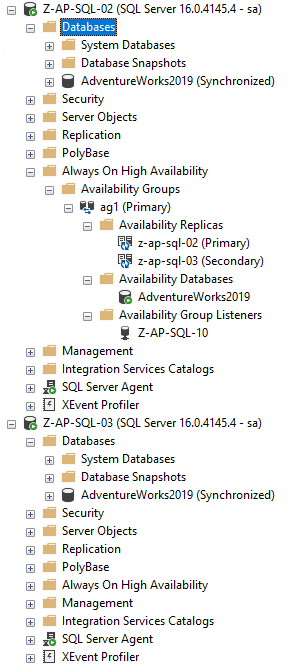
Apenas um AG padrão de dois nós com um banco de dados já sincronizado entre os nós. É esse banco de dados que vamos semear para o pod em execução no cluster Kubernetes usando um grupo de disponibilidade distribuída.
Aqui está o cluster Kubernetes:
nós de obtenção kubectl
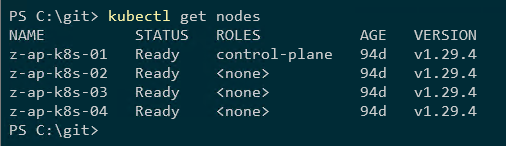
Quatro nós, um nó de plano de controle e três nós de trabalhador.
A primeira coisa a fazer é implantar um statefulset executando um pod do SQL Server (usando um arquivo chamado sqlserver-statefulset.yaml):
kubectl apply -f .\sqlserver-statefulset.yaml
Aqui está o manifesto do statefulset:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465
apiVersion: aplicativos/v1kind: StatefulSetmetadata: nome: mssql-statefulsetspec: serviçoNome: réplicas "mssql": 1 podManagementPolítica: Seletor paralelo: matchLabels: nome: modelo mssql-pod:metadados: rótulos: nome: Anotações mssql-pod:stork.libopenstorage.org/disableHyperconvergence: especificação "verdadeira": segurançaContexto: fsGroup: 10001 hostAliases: - ip: "10.225.115.129" nomes de host: - contêineres "z-ap-sql-10": - nome: Imagem do mssql-container: mcr.microsoft.com/mssql/server:2022-CU15-ubuntu-20.04portas: - contêinerPorta: Nome do 1433: mssql-port env: - nome: MSSQL_PID value: "Desenvolvedor" - nome: ACCEPT_EULA value: "Y" - nome: MSSQL_AGENT_ENABLED value: "1" - nome: MSSQL_ENABLE_HADR value: "1" - nome: MSSQL_SA_PASSWORD value: "Teste1122" volumeMontagens: - nome: sqlmontagem do sistemaCaminho: /var/opt/mssql - nome: sqlmontagem de dadosCaminho: /var/opt/sqlserver/volume de dadosReivindicaçõesModelos: - metadados: nome: sqlespecificação do sistema: acessoModos: - ReadWriteRecursos: solicitações: armazenamento: 1GistorageClassName: mssql-sc - metadados: nome: sqldata spec: acessoModes: - ReadWriteRecursos: solicitações: armazenamento: 25GistorageClassName: mssql-sc
Como a minha última publicação, isso é bem despojado. Sem limites de recursos, tolerâncias, etc. Ela tem dois volumes persistentes: um para os bancos de dados do sistema e um para os bancos de dados do usuário de uma classe de armazenamento já configurada no cluster.
Uma coisa a observar:
1234 hostAliases:- ip: "10.225.115.129" hostnames: - "z-ap-sql-10"
Aqui, uma entrada no arquivo hosts do pod está sendo criada para o ouvinte do grupo de disponibilidade do Windows.
A próxima coisa a fazer é implantar dois serviços: um para que possamos nos conectar à instância SQL (na porta 1433) e um para o AG (porta 5022):
kubectl apply -f .\sqlserver-services.yaml
Veja o manifesto dos serviços:
12345678910111213141516171819202122232425 apiVersão: v1kind: Servicemetadata: nome: mssql-servicespec: portas: - nome: portas mssql: destino 1433Porta: seletor 1433: nome: tipo de grupo mssql: LoadBalancer---apiVersão: v1kind: Servicemetadata: nome: mssql-ha-servicespec: portas: - nome: porta mssql-ha-ports: destino 5022Porta: seletor 5022: nome: tipo de grupo mssql: LoadBalancer
Observação: Poderíamos usar apenas um serviço com várias portas configuradas, mas estou mantendo-as separadas aqui para tentar manter as coisas o mais claras possível.
Como usar o backup de snapshot T-SQL: Recuperação pontual
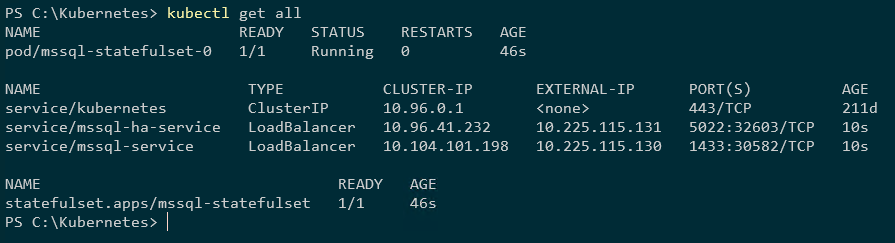
Verifique se tudo parece bem:
kubectl obter tudo
Agora, precisamos criar a chave mestra, o login e o usuário em todas as instâncias:
123 CRIE A CRIPTOGRAFIA PRINCIPAL POR SENHA = '
Em seguida, crie um certificado na instância SQL no pod:
CRIAR CERTIFICADO dbm_certificate COM ASSUNTO = 'Mirroring_certificate', EXPIRY_DATE = '20301031'
Faça backup desse certificado:
123456 CERTIFICADO DE BACKUP dbm_certificatePARA ARQUIVO = '/var/opt/mssql/data/dbm_certificate.cer'COM CHAVE PRIVADA ( ARQUIVO = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION POR SENHA = '
Copie o certificado localmente:
12 kubectl cp mssql-statefulset-0:var/opt/mssql/data/dbm_certificate.cer ./dbm_certificate.cer -n prodkubectl cp mssql-statefulset-0:var/opt/mssql/data/dbm_certificate.pvk ./dbm_certificate.pvk -n prod
Depois, copie os arquivos para as caixas do Windows:
1234 Copy-Item dbm_certificate.cer \\z-ap-sql-02\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.pvk \\z-ap-sql-02\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.cer \\z-ap-sql-03\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.pvk \\z-ap-sql-03\E$\SQLBackup1\ -Force
Assim que os arquivos estiverem nas caixas do Windows, podemos criar o certificado em cada instância do Windows SQL:
1234567 CRIAR dbm_certificate AUTORIZAÇÃO DE CERTIFICADO dbm_user A PARTIR DE ARQUIVO = 'E:\SQLBackup1\dbm_certificate.cer' COM CHAVE PRIVADA (ARQUIVO = 'E:\SQLBackup1\dbm_certificate.pvk', DECRYPTION POR SENHA = '')
OK, ótimo! Agora, precisamos criar um endpoint de espelhamento na instância SQL no pod:
123456789101112 CRIAR [Hadr_endpoint]ESTADO DE ENDPOINT = INICIADOCOMO TCP ( LISTENER_PORT = 5022, LISTENER_IP = TODOS)PARA DATA_MIRRORING ( FUNÇÃO = TODOS, AUTENTICAÇÃO = CERTIFICADO WINDOWS [dbm_certificate], CRIPTOGRAFIA = ALGORITMO NECESSÁRIO AES );ALTERAR [Hadr_endpoint] ESTADO DE ENDPOINT = INICIADO;CONECTAR-SE AO ENDPOINT:[Hadr_endpoint] PARA [dbm_login];
Já existem endpoints nas instâncias do Windows, mas precisamos atualizá-los para usar o certificado para autenticação:
12345678910 ALTERAR [Hadr_endpoint]ESTADO DO PONTO DE EXTREMIDADE = INICIADOCOMO TCP ( LISTENER_PORT = 5022, LISTENER_IP = TUDO)PARA DATABASE_MIRRORING (AUTENTICAÇÃO = CERTIFICADO DO WINDOWS [dbm_certificate], CRIPTOGRAFIA = ALGORITMO NECESSÁRIO );CONECTAR NO PONTO DE EXTREMIDADE: [Hadr_endpoint] PARA [dbm_login];
Agora, podemos criar um grupo de disponibilidade sem cluster de um nó na instância SQL no pod:
12345678910111213 CRIE UM GRUPO DE DISPONIBILIDADE [AG2]COM (CLUSTER_TYPE=NONE) FORREPLICA ON'mssql-statefulset-0' COM ( ENDPOINT_URL = 'TCP://mssql-statefulset-0.com:5022', FAILOVER_MODE = MANUAL ,AVAILABILITY_MODE SYNCHRONOUS_COMMIT ,BACKUP_PRIORITY = 50 ,SEEDING_MODE = AUTOMATIC ,SECONDARY_ROLE(ALLOW_CONNECTIONS = = NÃO) )
Não há ouvinte aqui; vamos usar o mssql-ha-service como ponto de extremidade para o grupo de disponibilidade distribuída.
OK, assim, no nó primário do grupo de disponibilidade do Windows, podemos criar o grupo de disponibilidade distribuída:
1234567891011121314151617 CRIE UM GRUPO DE DISPONIBILIDADE [DistributedAG]COM (DISTRIBUÍDO) GRUPO DE DISPONIBILIDADE NO 'AG1' COM ( LISTENER_URL = 'tcp://Z-AP-SQL-10:5022', AVAILABILITY_MODE ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = = AUTOMÁTICO ), 'AG2' COM ( LISTENER_URL = 'tcp://10.225.115.131:5022', AVAILABILITY_MODE ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = = AUTOMÁTICO );
Poderíamos usar uma entrada de arquivo host para a URL no AG2 (fazi isso na publicação anterior), mas aqui usaremos apenas o endereço IP do mssql-ha-service.
Certo, quase lá! Agora temos que entrar no grupo de disponibilidade na instância SQL no pod:
1234567891011121314151617 ALTER AVAILABILITY GROUP [DistributedAG]JUNTE-SE A AVAILABILITY GROUP ON'AG1' COM ( LISTENER_URL = 'tcp://Z-AP-SQL-10:5022', AVAILABILITY_MODE ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = = AUTOMÁTICO ), 'AG2' COM ( LISTENER_URL = 'tcp://10.225.115.131:5022', AVAILABILITY_MODE ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMÁTICO );
E isso deve ser feito! Se agora nos conectarmos à instância SQL no pod, o banco de dados estará lá!
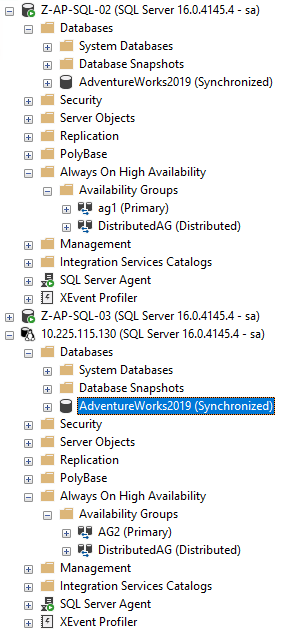
Aí está! OK, uma coisa que não passei aqui é como fazer a semeadura automática trabalhar no Windows em uma instância SQL do Linux. Eu percebi como isso funciona na minha publicação anterior, mas o ponto principal é que, desde que os dados do banco de dados e os arquivos de log estejam localizados no caminho de log e dados padrão da instância do Windows SQL, eles serão automaticamente semeados para os caminhos de log e dados padrão da instância do Linux SQL.
É assim que separa um banco de dados de uma instância SQL que está em um grupo de disponibilidade do Windows em uma instância SQL em execução em um pod em um cluster Kubernetes usando um grupo de disponibilidade distribuída.

Stellar Storage
Boost performance for SQL Server with Pure Storage.



