

Resumo
FlashBlade//EXA is the newest member of the FlashBlade family. Optimized for AI workloads, this ultra-scale data storage platform provides massive storage throughput and operates at extreme levels of performance and scale.


Competidores, liguem seus motores! A Pure Storage tem o prazer de anunciar o FlashBlade//EXA (uma plataforma de armazenamento de dados de ultraescala otimizada para cargas de trabalho de AI que oferece taxa de transferência de armazenamento massiva e opera em níveis extremos de desempenho e escala.
O que os fabricantes de carros de alto desempenho e a Pure Storage têm em comum? Assim como as montadoras de alto nível projetam modelos de carros de corrida de última geração que superam os limites de velocidade e eficiência, o FlashBlade//EXA foi desenvolvido para oferecer desempenho de alto nível para cargas de trabalho de AI e HPC. O FlashBlade//EXA é semelhante a esses exemplos, pois é um sistema FlashBlade® com Purity//FB altamente otimizado para fornecer desempenho de nível superior para as cargas de trabalho de AI mais exigentes. Ele complementa os modelos FlashBlade//S . e FlashBlade//E . de alta densidade que foram comprovados no mercado corporativo e reconhecidos no Quadrante Mágico . . do Gartner® . .Plataformas de armazenamento de arquivos e objetos como líderes por quatro anos consecutivos.
O desafio de negócios dos avanços rápidos da AI
À medida que a inovação da AI se expande, muitas empresas estão rapidamente descobrindo valor para aumentar ou revolucionar suas operações existentes com treinamento e inferência de modelos. Esse crescimento acelerado aumentou a adoção de fluxos de trabalho de AI em pré-processamento, treinamento, teste, ajuste e implantação, cada um se beneficiando de GPUs mais potentes e conjuntos de dados maiores e multimodais.
Essa expansão também introduziu novos desafios de infraestrutura. A escalabilidade do armazenamento legado, a verificação, o gerenciamento e as limitações de desempenho de metadados em grande escala estão criando gargalos e prejudicando a utilização total de infraestruturas caras orientadas por GPU e retardando o progresso e a inovação. Isso afeta muito as pressões financeiras agressivas de ROI da AI. Qualquer infraestrutura dedicada a ela precisa funcionar com desempenho máximo para garantir o valor mais rápido possível para treinamento e inferência de modelos. Tempo perdido é dinheiro perdido.
Os desafios de negócios são ampliados com fluxos de trabalho de AI em larga escala
Esse desafio de negócios de GPUs ociosas equivale a tempo e dinheiro perdidos é ampliado exponencialmente em escala, por exemplo, provedores de nuvem de GPU e laboratórios de AI, por dois motivos. Primeiro, a eficiência operacional massiva em grande escala é essencial para sua lucratividade e vai muito além do que a maioria das operações de datacenter locais/internas gerencia. Um blog que publicamos no ano passado ofereceu insights sobre como os provedores de serviços pensam e como a automação e a padronização brutal são essenciais para suas operações. Segundo, os provedores de serviços se inscrevem no princípio principal de evitar qualquer recurso que esteja inativo. Para eles, as GPUs ociosas em qualquer modelo de AI são uma oportunidade de perda de receita. As ineficiências de armazenamento em seu nível de operações podem ser prejudiciais.
As arquiteturas tradicionais de armazenamento de alto desempenho foram desenvolvidas em sistemas de arquivos paralelos e foram desenvolvidas e otimizadas para ambientes tradicionais dedicados de computação de alto desempenho (HPC, High-Performance Computing). As cargas de trabalho de HPC são previsíveis, portanto, os sistemas de armazenamento paralelo podem ser otimizados para uma expansão específica do desempenho. Os fluxos de trabalho e modelos baseados em AI em grande escala são diferentes dos tradicionais HPC porque são mais complexos, envolvendo muito mais parâmetros que também são multimodais, incluindo arquivos de texto, imagens, vídeos e muito mais, todos os quais precisam ser processados simultaneamente por dezenas de milhares de GPUs. Essas novas dinâmicas estão provando rapidamente como as abordagens tradicionais de armazenamento baseado em HPC têm dificuldade para ter um desempenho maior. Mais especificamente, o desempenho dos sistemas tradicionais de armazenamento paralelo se torna controverso com o serviço de metadados e dados associados do mesmo plano de controladora de armazenamento.
Esse gargalo emergente exige novas ideias para o gerenciamento de metadados e otimizações de acesso a dados para gerenciar com eficiência diversos tipos de dados e alta simultaneidade de cargas de trabalho de AI em uma escala de provedor de serviços.
Requisitos extremos de expansão de armazenamento com evolução da carga de trabalho de AI
À medida que os volumes de dados aumentam, o gerenciamento de metadados se torna um gargalo crítico. O armazenamento legado tem dificuldade para expandir metadados com eficiência, levando à latência e degradação do desempenho, especialmente para cargas de trabalho de AI e HPC que exigem paralelismo extremo. Arquiteturas tradicionais, desenvolvidas para acesso sequencial, não conseguem acompanhar. Eles frequentemente sofrem de rigidez e complexidade, limitando a escalabilidade. Superar esses desafios requer uma arquitetura de metadados em primeiro lugar que se expanda sem problemas, ofereça suporte a paralelismo massivo e elimine gargalos. À medida que a oportunidade de AI e HPC evolui, os desafios só se agravam.

O núcleo comprovado de metadados disponível no FlashBlade//S ajudou os clientes corporativos a lidar com requisitos exigentes de treinamento, ajuste e inferência de AI superando desafios de metadados, como:
- Gerenciamento simultâneo: Lidar com grandes volumes de solicitações de metadados em vários nós com eficiência
- Prevenção de hotspot: Evitar gargalos de um único servidor de metadados que possam degradar o desempenho e exigir ajustes e otimizações contínuos
- Consistência em grande escala: Garantir sincronização entre cópias de metadados distribuídos
- Gerenciamento de hierarquia eficiente: Otimização de operações complexas do sistema de arquivos enquanto mantém o desempenho
- Escalabilidade e resiliência: Manter o alto desempenho conforme os volumes de dados aumentam exponencialmente
- Eficiência operacional: Garantir que o gerenciamento e a sobrecarga sejam minimizados e automatizados para dar suporte à eficiência em grande escala
O FlashBlade//EXA aborda os desafios do desempenho de AI em grande escala
A Pure Storage tem um histórico comprovado de suporte aos clientes em uma ampla gama de casos de uso de alto desempenho e em todas as etapas de sua jornada de AI. Desde que introduzimos a AIRI® (infraestrutura pronta para inteligência artificial) em 2018, continuamos liderando com inovações como certificações para NVIDIA DGX SuperPOD e NVIDIA DGX BasePOD . Além de soluções prontas para uso, como GenAI Pods. O FlashBlade ganhou confiança no mercado corporativo de AI e HPC, ajudando organizações como a Meta a expandir suas cargas de trabalho de AI com eficiência. Nosso núcleo de metadados é construído em um banco de dados transacional altamente distribuído, e a tecnologia de armazenamento de valor-chave garantiu alta disponibilidade de metadados e expansão eficiente. Ao aplicar insights de hiperescaladores e aproveitar nosso núcleo avançado de metadados comprovado com o FlashBlade//S, a Pure Storage tem a capacidade exclusiva de oferecer armazenamento de desempenho extremo que supera os desafios de metadados de AI e HPC em grande escala.
Insira o FlashBlade//EXA.
À medida que fluxos de trabalho extremos de AI ultrapassam os limites da infraestrutura, a necessidade de uma plataforma de armazenamento de dados que corresponda a essa escala nunca foi tão grande. O FlashBlade//EXA amplia a família FlashBlade, garantindo que ambientes de inteligência AI e HPC de grande escala não sejam mais limitados por limitações de armazenamento legadas.
O FlashBlade//EXA foi desenvolvido para fábricas de AI e oferece uma arquitetura de processamento extremamente paralela que desagrega dados e metadados, eliminando gargalos e complexidade associados a sistemas de arquivos paralelos legados. Desenvolvido com base nos pontos fortes comprovados do FlashBlade e com suporte da arquitetura avançada de metadados do Purity//FB, ele oferece taxa de transferência, escalabilidade e simplicidade inigualáveis em qualquer escala.
Seja dando suporte a nativos de AI artificial, titãs de tecnologia, empresas orientadas por AI, provedores de nuvem com tecnologia de GPU, laboratórios de HPC ou centros de pesquisa, o FlashBlade//EXA atende às demandas dos ambientes mais intensivos de dados. Seu design de última geração permite produção, inferência e treinamento contínuos, oferecendo uma plataforma abrangente de armazenamento de dados até mesmo para as cargas de trabalho de AI mais exigentes.
Nossa abordagem inovadora sobre como modificamos o Purity//FB, que envolveu dividir a I/O baseada em rede de taxa de transferência de alta velocidade em dois elementos distintos:
- O array FlashBlade armazena e gerencia os metadados com seu banco de dados de chave/valor distribuído de expansão horizontal líder do setor.
- Um cluster de nós de dados de terceiros é onde os blocos de dados são armazenados e acessados em alta velocidade a partir do cluster de GPU por acesso remoto direto à memória (RDMA, Remote Direct Memory Access) usando protocolos de rede padrão do setor.
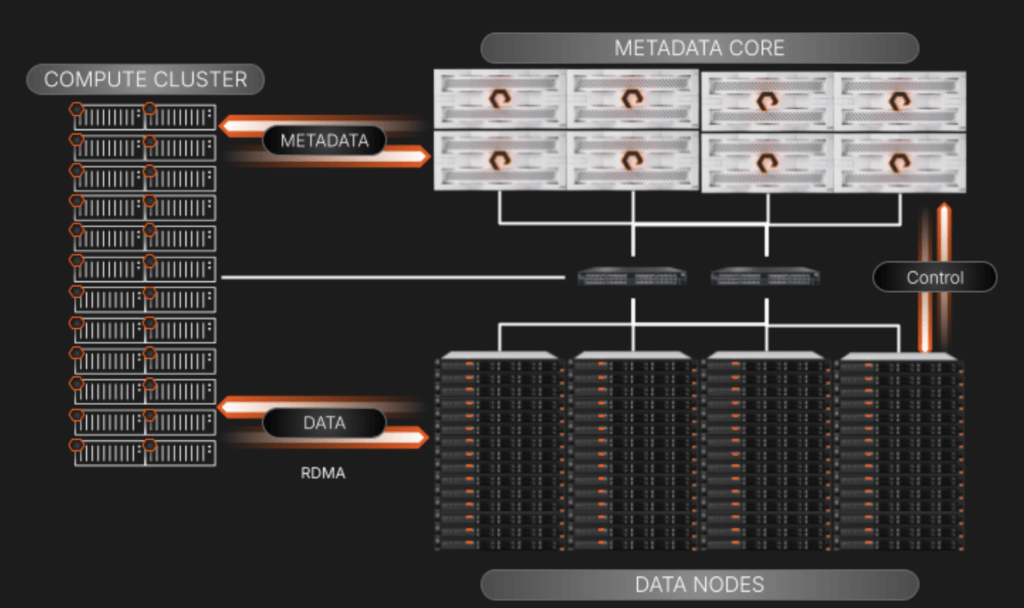
Essa segregação fornece acesso a dados sem bloqueio que aumenta exponencialmente em cenários de computação de alto desempenho, onde as solicitações de metadados podem ser iguais, se não forem maiores, às operações de I/O de dados.
Por que servidores prontos e SSDs para nós de dados?
Ambientes de AI de grande escala podem ter um investimento estabelecido de servidores 1U e 2U com SSDs como blocos de construção de infraestrutura. O FlashBlade//EXA aproveita servidores prontos para uso para o plano de dados, facilitando a adaptação à arquitetura do cliente alvo (neste caso, ambientes de grande escala). Isso destaca um ponto importante sobre nossa plataforma de armazenamento de dados:
*Purity da Pure, como o coração da nossa plataforma, está em sua capacidade de ser modificada para lidar com novos casos de uso, mesmo que isso signifique expandir para operar fora do nosso próprio hardware. Resolver desafios com nosso software é um princípio essencial para nós, pois é uma abordagem mais elegante e oferece um tempo de retorno mais rápido para os clientes.
Esses nós de dados prontos para uso dão aos clientes a flexibilidade de se adaptar ao longo do tempo e podem ser orientados pela evolução dos clientes sobre como eles aproveitam o flash NAND em seus datacenters.
Uma visão de alto nível dos componentes e I/O do FlashBlade//EXA
Ao separar os planos de metadados metadados e serviços de dados, nos concentramos em manter os elementos no diagrama acima simples de expandir e gerenciar:
- Núcleo Metadata: Isso atende a todas as consultas de metadados do cluster de computação. Quando uma consulta é atendida, o nó de computação solicitante será direcionado para o nó de dados específico para fazer seu trabalho. O array também supervisiona a relação dos nós de dados com os metadados por meio de uma conexão de plano de controle que está nos bastidores de seu próprio segmento de rede.
- Nós de dados de terceiros: São servidores padrão prontos para garantir ampla compatibilidade e flexibilidade. Os blocos de dados residem nas unidades NVMe nesses servidores. Eles executarão um OS e um kernel “finos” baseados em Linux com gerenciamento de volume e serviços de destino RDMA que são personalizados para trabalhar com metadados residentes no array FlashBlade//EXA. Incluiremos um manual do Ansible para gerenciar a implantação e os upgrades nos nós para eliminar qualquer preocupação com a complexidade em grande escala.
- Acesso paralelo aos dados usando o ambiente de rede existente: O FlashBlade//EXA emprega uma abordagem elegante que aproveita uma rede de núcleo único altamente disponível usando o BGP para rotear e gerenciar o tráfego entre clientes de metadados, dados e carga de trabalho. Esse design permite integração contínua às redes de clientes existentes, simplificando a implantação de ambientes de armazenamento altamente paralelos. É importante ressaltar que todos os protocolos de rede aproveitados são padrão do setor; a pilha de comunicação não contém elementos proprietários.
Descubra os desafios do armazenamento legado de alto desempenho com sistemas de arquivos paralelos e modelos desagregados
Muitos fornecedores de armazenamento visando à natureza de alto desempenho de grandes cargas de trabalho de AI resolvem apenas metade do problema de paralelismo, oferecendo a maior largura de banda de rede possível para os clientes chegarem aos destinos de dados. Eles não abordam como os metadados e os dados são atendidos em uma taxa de transferência massiva, que é onde surgem os gargalos em larga escala. Isso faz sentido, pois a intenção do design da NFS quando a Sun Microsystems o criou em 1984 era simplesmente preencher a lacuna entre o acesso local e remoto a arquivos, onde o foco do design era a funcionalidade em vez da velocidade.
Desafios de expansão com NAS legado
O design e a escala do NAS legado proíbem o suporte ao armazenamento paralelo devido ao seu design de finalidade única para atender aos compartilhamentos de arquivos operacionais e à incapacidade de expandir I/O linearmente conforme mais controladores são adicionados.
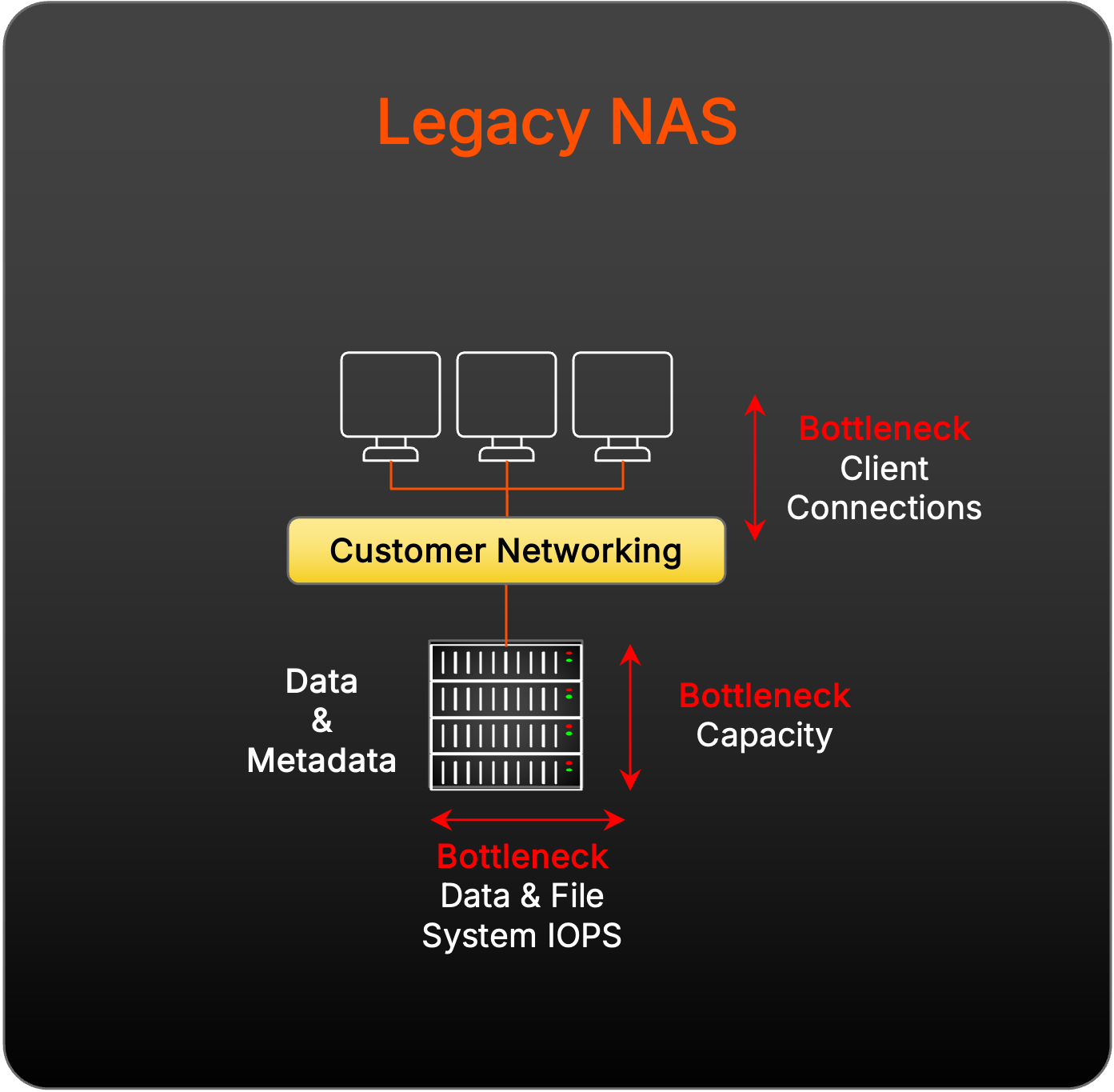
Desafios do dimensionamento com sistemas de arquivos paralelos tradicionais
Mesmo antes do aumento atual da AI, alguns provedores de armazenamento legado aproveitaram sistemas de arquivos paralelos especializados, como o Lustre, para oferecer paralelismo de alta taxa de transferência para necessidades de computação de alto desempenho. Embora isso tenha funcionado para vários ambientes grandes e pequenos, ele é propenso à latência de metadados, à rede extremamente complicada e à complexidade do gerenciamento, muitas vezes relegado a PhDs que supervisionavam suas arquiteturas de HPC e aos custos flexíveis associados ao dimensionar para necessidades maiores.
Desafios das soluções desagregadas de dados e computação
Outros fornecedores de armazenamento arquitetaram suas soluções não apenas para confiar em um sistema de arquivos paralelos desenvolvido especificamente, mas também para adicionar uma camada de agregação de computação entre clientes de carga de trabalho e os metadados e destinos de dados:
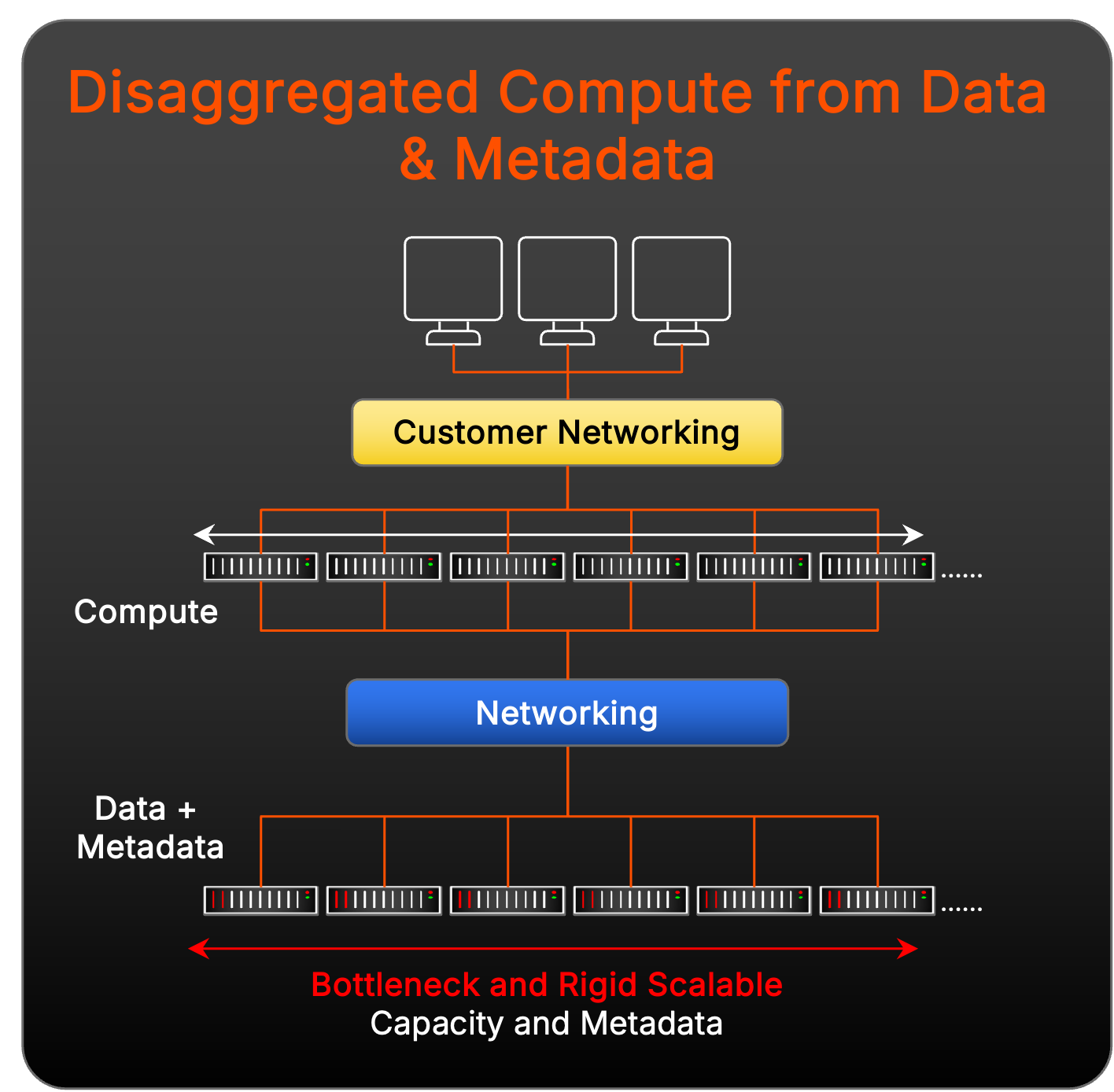
Esse modelo sofre com a rigidez de expansão e mais desafios de complexidade de gerenciamento do que o pNFS ao expandir para um desempenho massivo porque envolve adicionar mais peças móveis com nós de agregação de computação. Há outro desafio potencial: a implantação de funções de acesso a dados desagregados neste modelo corre o risco de latência inesperada na pilha porque sua rede se torna muito mais complicada no gerenciamento do endereçamento, cabeamento e conectividade com três camadas distintas em comparação com o que é necessário para pNFS.
Além disso, cada nó de dados e metadados recebe uma quantidade fixa de cache onde os metadados são sempre armazenados. Essa rigidez força os dados e metadados a expandirem em lockstep, criando ineficiências para cargas de trabalho multimodais e dinâmicas. E, conforme as demandas de carga de trabalho mudam, essa abordagem de expansão linear pode levar a gargalos de desempenho e superprovisionamento desnecessário da infraestrutura, complicando ainda mais o gerenciamento de recursos e limitando a flexibilidade.
Estamos apenas começando também
Nosso anúncio do FlashBlade//EXA revoluciona o desempenho, a escalabilidade e a simplicidade para cargas de trabalho de AI em grande escala. E estamos apenas começando.
Entre em contato com sua equipe da Pure Storage para saber mais sobre como estamos, mais uma vez, revolucionando o pensamento convencional em um dos segmentos de rápido crescimento do setor!
Encontre-se conosco no NVIDIA GTC 2025, de 17 a 21 de março. Agende uma reunião.
Explore pure.ai e nossa página de soluções de AI para saber mais.

FlashBlade//EXA
Experience the World’s Most Powerful Data Storage Platform for AI
Join the Webinar
Discover the power of FlashBlade//EXA for AI workloads. April 24, 2005.



