
Organizations are amassing data at an exponential rate. According to the latest estimates, 328.77 million terabytes, or 0.33 zettabytes of data, is created every day. Over the past decade, businesses have harnessed this “big data” to unlock new possibilities and enhance analytical capabilities. Now, it’s time to accelerate those capabilities and move beyond experimentation toward mature investments or risk losing competitive edge.
How Can Splunk Enterprise Help Offset Challenges with Data Growth?
Splunk Enterprise enables organizations to make meaningful decisions quickly by helping them to unify data from disparate sources, analyze it to drive business resilience, then visualize it to unlock new and valuable insights. However, significant data growth still poses numerous challenges:
- Increased cost of infrastructure due to traditional distributed scale-out architecture where compute and storage are scaled dependently while maintaining multiple copies of data
- Dependent scaling of compute and storage, resulting in underutilized resources either at the compute or storage layers
- Operational overhead with the data management due to physical data movement that puts a strain on the servers and the network
- Lack of faster insights due to poor search performance
At Pure Storage, we help address these challenges head-on using the Splunk Operator for Kubernetes with Splunk SmartStore on S3-compatible object storage and cloud native persistent data storage. By running the Splunk Operator on the latest bare-metal servers using Pure Storage® FlashBlade® for object storage and Portworx®, the leading Kubernetes data services platform, application performance improves, server and storage utilization are maximized, and Splunk Enterprise management is simplified.
The Test: Ingest and Search on Bare Metal vs. Kubernetes Cluster on Bare Metal
To illustrate the benefits, we performed ingest and search tests in two ways:
- On bare-metal servers. As a baseline measure, we ran the tests with Splunk SmartStore on a six bare-metal server environment with four nodes hosting the indexer cluster and the other two hosting the cluster manager and a search head.
- On a Kubernetes cluster set up on top of the same bare-metal servers, using an increased number of indexer pods. In the case of Kubernetes, the Kubernetes cluster was set up on the same six bare-metal servers with four worker nodes dedicated to host 32 indexer pods while the other two worker nodes hosted the cluster manager and search heads.
Here is a glimpse of the ingest and search test results:
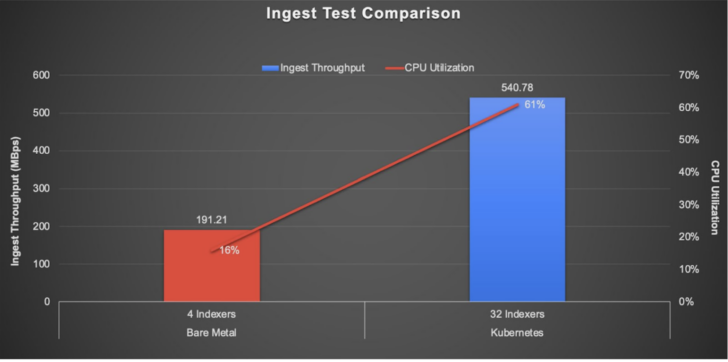
Ingest Test Results
Search Test Results
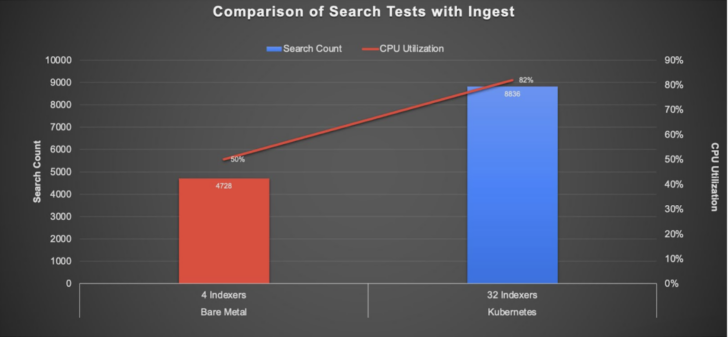
As you can see from the charts above, the performance on Kubernetes was three times better than bare-metal servers during ingest and had twice the improvement in running dense and sparse searches, all while maximizing server utilization by a factor of 1.6 times.
For more in-depth information on this solution, details covering the test environment and results, read our latest technical white paper, “Splunk SmartStore on Kubernetes with Portworx and Pure Storage FlashBlade.”
![]()



