


Recently, Pure Storage and Equinix introduced a new joint offering: Pure Storage® on Equinix Metal™. You can read more about the solution on the Pure Storage on Equinix Metal product page.

In short, the solution enables you to deploy compute on demand with automated OS build processes. They charge in a similar fashion to the public cloud:

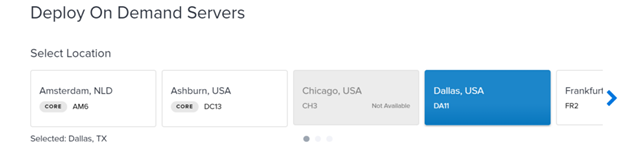
To get started, choose a data center:
Select a server size:
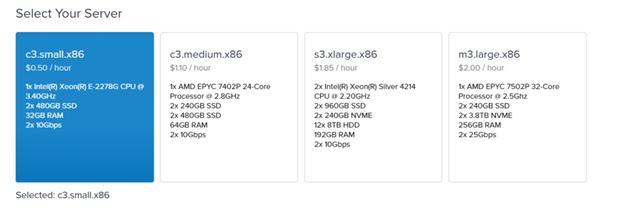
Then, select a compute type:

Then, enter how many servers you have and add their names:
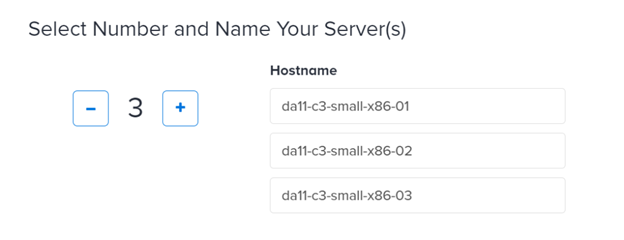
There are also optional parameters, such as whether you want to load custom SSH keys automatically or use specific network assignments. You can automate all this through the Equinix Metal API. Many automation kits such as Terraform are available in the Equinix Metal Github repository.
Use Cases
I think there’s a lot of opportunity here. Not everything can and will go into the public cloud, but that doesn’t make the on-demand model unattractive. Being able to stand up bare metal only when you need it—and most importantly, only pay for it when you need it—makes a lot of sense. That’s especially true for environments that might have predictably or unpredictably changing workload needs, such as:
- Disaster Recovery: Keep a small pilot light footprint running a management host with some services (like a vCenter VM and Site Recovery Manager), and deploy and expand compute upon failover. Reduce footprint if/when you fail back.
- Remote Sites: Use their global footprint to bring services closer to end users.
- VDI: VDI demands rise and fall, not only over time but also over the course of a day for a given region. For locality, bring the VDI closer to the end user by deploying multi-site.
- Upgrades/lifecycle: Instead of buying and sunsetting new compute, you don’t even need to upgrade. You can deploy new and then jettison the old servers. This approach is particularly useful for virtualized environments where there is little to no state in the “OS” like ESXi.
- Dealing with Hardware: With Equinix, you won’t have to. You get full access and control of the hardware, but Equinix handles the power, cables, and switching infrastructure. You consume the end result.
The use cases grow from there. One of the most interesting deployments is vSphere. On-demand, movable, and rebalance-capable compute is something vSphere does well. Matching it with on-demand physical resources is quite compelling. The benefit for this deployment versus VMware Cloud on AWS, for example, is that it isn’t locked down. You can use all of the integrations and tools you’re used to working with. Things that work in your own data center will work here, too.
However, one thing required to make this work much better is external storage. If you need to copy/restore/rebalance data every time you add or remove compute, the process would be greatly slowed—reducing the usefulness of the more elastic use cases. And for situations like disaster recovery, having the storage in the compute requires the compute to be sitting there waiting. The “pilot light” needs to be large enough to offer the capacity needed to store the full infrastructure. And when it expands, how will the other servers share that data?
This is where FlashArray™ comes in. FlashArray is offered with Pure as-a-Service™ licensing (you pay for what you use) through Equinix and it sits in the Equinix Metal data centers. You can replicate from your own data center or another Equinix datacenter. You can also replicate your data from a FlashArray via CloudSnap™ to object storage like AWS S3 or Microsoft Azure Blob (Equinix Metal also offers cloud access via ExpressRoute or DirectConnect) and restore to FlashArray.
VMware on Pure
Take advantage of all of the Pure Storage VMware features like our vSphere Plugin, vVols, SRM, vRealize, VAAI, Tanzu, and more. And with the on-demand compute of Equinix Metal. From a network perspective, Equinix offers a few modes:
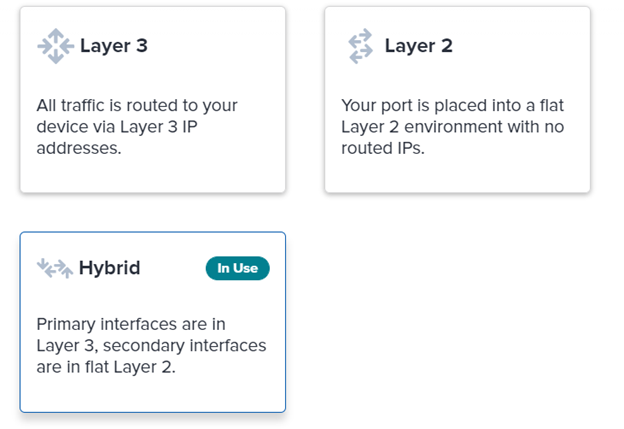
- Layer 3: Has externally routable addresses with no VLANs.
- Layer 2: Internally routable addresses: It will use VLAN tagging when there’s more than one network in use.
- Hybrid: Support for both layer 2 and 3 at once.
Equinix Metal generally gets deployed with two physical NICs (larger compute instances come with four). Each of the options above also has two flavors (except layer 3, which is only bonded):
- Bonded: Link Aggregation Control Protocol (LACP) is used at the switch and both NICs are configured identically so you must use Link Aggregation Groups (LAGs) in the OS.
- Unbonded: The NICs aren’t engaged in LACP, and no LAGs are required.
Currently, if the NICs are unbonded, you cannot assign the same VLAN to both NICs. For network redundancy, you want to go with the bonded route. You’ll have to use LAGs. For vSphere, you’ll need virtual distributed switches with LAGs that are configured with both NICs. Basically, you’ll need to set up non-redundant standard switches then migrate over to a LAG-based VDS. There are different opinions on using LACP in vSphere, but I think it works quite well and is fairly easy to configure. But, there are benefits to port binding instead. In general, vSphere provides great support when using multiple NICs at once for redundancy that don’t require LACP/LAGs. In particular, VCF requirements don’t permit it. But if you look at the Equinix public roadmap, a solution for unbonded shared VLAN support is coming soon.
Basically, you’ll need to set up non-redundant standard switches then migrate over to a LAG-based VDS. There are different opinions on using LACP in vSphere, but I think it works quite well and is fairly easy to configure. But, there are benefits to port binding instead. In general, vSphere provides great support when using multiple NICs at once for redundancy that don’t require LACP/LAGs. In particular, VCF requirements don’t permit it. But if you look at the Equinix public roadmap, a solution for unbonded shared VLAN support is coming soon.
So, more flexibility in network configuration is coming. In the meantime, check out my documentation on setting up Equinix vSphere environments.
![]()



