


Like many gamers, I used to build my own systems. I loved picking out the CPU, the video card, which ISA-based modem (that’s a real thing) I was going to use, and why. You could spend your money on precisely what you wanted whether that was more money on graphics for games or a faster modem for getting online. Or maybe, it was all about the sound card.
With enterprise storage deeply hidden amongst the racks in some data center, we don’t always get to see the absolutely awesome hardware inside. If you were to take a peek inside a FlashArray™ system, you’d find custom-made flash, in a custom chassis, with hot-swappable controllers and custom software to optimize all of it.
So, as a hardware geek, I was excited when I found out about Pure’s new hardware release called DirectCompress Accelerator (DCA). Pure’s data reduction is already the best in the industry, leveraging Purity software running through conventional CPUs. But, our engineering teams weren’t content to just stop there and wanted to squeeze out more value. They felt they could do better by moving data reduction to a specialized offload card.
And we can now see the success of this plan. Today, we start shipping DCA free of additional charge in every FlashArray//XL™, our highest performing, biggest beast FlashArray to improve its cost-per-effective capacity.
DirectCompress Accelerator Increases FlashArray Value
The DCA is a CPU offload card, installed into a PCI slot, that takes over inline data reduction and allows the array CPUs to focus on other tasks. By taking over inline compression of incoming data, the DCA brings more bang for the buck with the following benefits:
- Frees up array CPUs for important tasks such as replication, array management, or garbage collection during demanding workloads.
- Increases storage space. We’re seeing an average of about 6% more, but it will greatly vary depending on the workload and type of data being written. Much like interest in a savings account, it can add up over time. Who wouldn’t like additional capacity on their FlashArray//XL?
- Has greater energy efficiency on a per effective TB basis.
- Streamlines high-speed migrations by improving inline compression by 30%. With DCA, ingested data is deeply compressed immediately, which keeps capacity use as low as possible during the migration.
- Since data is deep-compressed before it is written to flash, compared to the previous state, less data is written to flash. This in turn could improve the NAND wear rates, improving flash durability and lifespan.

How Data Reduction Works
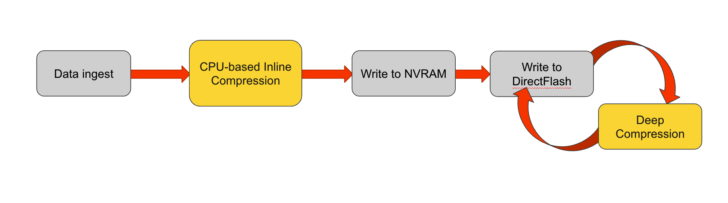
To better understand where, or how the DCA fits into a Pure Storage® FlashArray, let’s explore how our data reduction works. The data reduction flow is straightforward enough. Data comes in from various applications through Fibre Channel or iSCSI connections. CPUs immediately get to work to remove empty space, patterns in data, then deduplicates redundant data, creating metadata (pointers) that represent the removed patterns and duplicated bytes.
Next, a lightweight compression (LZO compression) is applied. The initial inline reduction is not exhaustive; its goal is reasonable efficiency with minimal latency. LZO compression algorithms minimize CPU consumption at the expense of thoroughness. This entire process is referred to as “inline data reduction.”
Finally, the data flows into NVRAM and is then written to flash. It’s important to understand two details here:
- Incoming data is reduced and compressed by “best effort.” This process is dependent on the power of the CPUs, number of CPUs, and how busy these CPUs are. Even with lots of power, if the array is servicing millions of requests, replicating data, reporting metrics to management apps, etc., it’s limited on a moment-to-moment basis with how effectively data is reduced. This is why, after data is written to flash, we perform a background post-process “deep compression.”
- For data migrations, it’s therefore possible to overrun data reduction since it’s best effort. This can complicate data migrations when data being migrated is highly reducible and without reduction would exceed the capacity of the target array. The DCA mitigates this by offloading the entire process.
 The Final Step: Deep Compression and the Shrinking Array
The Final Step: Deep Compression and the Shrinking Array
Data reduction, using its various methods, such as removal of zeros (thin provisioning), pattern removal, and deduplication, can take, for example, 1TB of data and reduce it to 500GBs for a generic data set. For VDI infrastructure, it might be reduced 10 fold before compression given the similarities of virtual disks housing the same operating system.
Next, we take 500GBs of the remaining data and compress it; compression typically halves the volume of data, so the initial 1TB of data is now about 250GBs, giving us 4 to 1 data reduction. Compression is a critical process since it impacts all of the data and not just select strings of data like with pattern removal.
After, we perform an initial reduction. Later, during less busy periods, we initiate “deep compression” using Huffman-type compression. This is very effective but can take considerable time.
The payoff of post-process deep compression is watching the array shrink down over the weekend or over a holiday break. But the caveat here is that you need stretches of time of little activity so that the array can switch gears and start to perform the deep compression. With DCA, you don’t need to wait for the array to be less busy to get deep compression rates.
How DirectCompress Accelerator Delivers Deep Compression in One Step
We know the benefits of DCA, how it fits into the FlashArray, and that I love hardware. Speaking of which, the DCA leverages FPGAs, which are programmable CPUs that can execute code very, very fast. There are many powerful advantages to FPGAs over CPUs. Due to simpler instruction sets, the compression algorithm runs much more efficiently, both in terms of computational speed and energy usage. So take this specific PCIe hardware, using custom code sets with specialized processors, the FPGAs, and then give it a specific job: compress data.
Oh, and we also retain post-process compression in the background for even deeper compression.
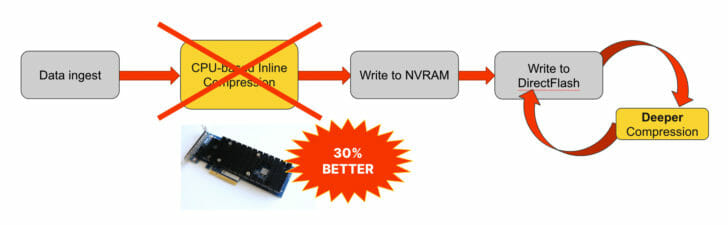
Offloading compression to DCA gives your FlashArray//XL more value. It frees up the controller’s CPUs for more processing power. It delivers faster migrations from competitor arrays to FlashArray because the compression happens immediately on ingest. And, of course, it stretches your storage capacity by boosting overall compression rates and stretches your storage lifespan by writing less data.
With DCA, you’re getting more bang for your buck: more effective space, more processing power, and a longer life for your storage media.
To learn more about how the DirectCompress Accelerator can stretch your storage capacity, watch the lightboard video.
![]()



