


This article originally appeared on Medium.com. It has been republished with permission from the author.
Did you spend a few hours trying to debug why Apache Spark on FlashBladeⓇ is slower than expected, only to realize you have an underlying networking issue?
Flashblade-plumbing is a tool to validate NFS and S3 read/write performance from a single client to a FlashBlade array with minimal dependencies and input required. The only inputs required are the FlashBlade’s management IP and login token and, after a few minutes, it will output the read and write throughputs for both NFS and S3.
The alternative is to manually configure filesystems and S3 accounts, generate some test data, and then configure and use command line tools like “dd” and “s5cmd,” or even worse, slower alternatives like “cp” and “s3cmd.”
See the accompanying github repository for source code and instructions.
How the FlashBlade Plumbing Tool Works
This tool leverages three different APIs:
- A management REST interface on the FlashBlade
- User-space NFS
- AWS S3 SDK
First, the tool uses the FlashBlade REST API to discover data ports and to create test file systems, object store accounts, keys, and buckets. Second, user-space NFS and S3 libraries enable the generation of write and read workloads. Finally, the REST API is used to remove everything previously created and return the system to the original state. The data written to the FlashBlade is random and incompressible. Each test phase runs for 60 seconds.
In many FlashBlade environments there are multiple subnets and data VIPs configured, allowing access to clients in different parts of the network. In case of multiple data VIPs defined on the FlashBlade, the program will test against one data VIP per configured subnet; if a dataVIP is not accessible after a period of time, the plumbing tool proceeds to the next subnet.
How To Use FlashBlade Plumbing
Only two inputs are required: 1) the FlashBlade management VIP and 2) login token. Together, these allow the plumbing program to access the FlashBlade management API to collect and create the necessary information to run the plumbing tests. Specify these input parameters using environment variables FB_MGMT_VIP and FB_TOKEN.
There are multiple different ways to run these tests, depending on the environment: Kubernetes, Docker, or a simple Linux server.
First, the login token can be created or retrieved via the FlashBlade CLI:
> pureadmin [create|list] --api-token --expose
An example output looks like below, where the client can only reach the FlashBlade on one of the configured data VIPs:
dataVip,protocol,result,write_tput,read_tput
192.168.170.11,nfs,SUCCESS,3.1 GB/s,4.0 GB/s
192.168.40.11,nfs,MOUNT FAILED,-,-
192.168.40.11,s3,FAILED TO CONNECT,-,-
192.168.170.11,s3,SUCCESS,1.7 GB/s,4.3 GB/s
Three Different Ways to Run
Depending on your environment, choose the approach easiest for you: Kubernetes, Docker, or Linux executable.Kubernetes.
The tool can be run within Kubernetes via a simple batch Job. See the example below and insert your MGMT_VIP and TOKEN. The nodeSelector field is optional and can be used to constrain which Kubernetes worker node runs the plumbing test pod.
apiVersion: batch/v1
kind: Job
metadata:
name: go-plumbing
spec:
template:
spec:
containers:
- name: plumbing
image: joshuarobinson/go-plumbing:0.3
env:
- name: FB_MGMT_VIP
value: “10.6.6.20.REPLACEME”
- name: FB_TOKEN
value: “REPLACEME”
nodeSelector:
nodeID: worker01
restartPolicy: Never
backoffLimit: 2
Docker
The following docker run command invokes the plumbing tool. Use your values for the MGMT_VIP and TOKEN environment variables.
docker run -it --rm -e FB_MGMT_VIP=$FB_MGMT_VIP -e FB_TOKEN=$FB_MGMT_TOKEN joshuarobinson/go-plumbing:0.3
Binary Standalone
For systems without Docker installed or access to Docker hub, download and run directly the 14MB Linux binary from the release page:
wget https://github.com/joshuarobinson/flashblade-plumbing/releases/download/v0.3/fb-plumbing-v0.3
chmod a+x fb-plumbing-v0.3
FB_MGMT_VIP=10.1.1.1 FB_TOKEN=REPLACEME ./fb-plumbing-v0.3
Running on Multiple Servers
Ansible makes it easy to run the plumbing test on a group of servers, either one at a time or all together. Note that if running multiple instances of the tool in parallel, the test phases will not be fully synchronized.
The following Ansible ad hoc commands first copy the downloaded binary to all nodes and then run the tool one host at a time using the “ — forks” option to disable parallelism.
ansible myhosts -o -m copy -a "src=fb-plumbing-v0.3 dest=fb-plumbing mode=+x"
ansible myhosts --forks 1 -m shell -a "FB_TOKEN=REPLACEME FB_MGMT_VIP=10.2.6.20 ./fb-plumbing"
Code Highlights
The source code for this plumbing utility is open and available on github and interacts with the FlashBlade using three different APIs: management via REST API and data via user-space NFS and AWS S3.
FlashBlade REST API
The FlashBlade REST API has a Python SDK, which simplifies interacting with the management API. In order to have one binary for both management operations and data plane testing, I implemented a subset of the REST API calls in Golang. The primary elements to a working Golang REST client are 1) negotiating authentication and 2) making specific API calls.
First, the authentication section requires choosing a support API version and then POSTing the login token to the API and receiving a session authentication token back. This session token is added to the header of all subsequent API calls for authentication.
The code for this login process follows this pattern:
authURL, _:= url.Parse("https://" + c.Target + "/api/login")
req, _:= http.NewRequest("POST", authURL.String(), nil)
req.Header.Add("api-token", c.APIToken)
resp, _:= c.client.Do(req)
if resp.StatusCode >= 200 && resp.StatusCode <= 299 {
c.xauthToken = resp.Header["X-Auth-Token"][0]
}
Then every subsequent call the following header:
req.Header.Add("x-auth-token", c.xauthToken)
Second, the REST calls are made using a helper function to create the request with the provided parameters and request body. Example calls look this:
data, err := json.Marshal(filesystem)
_, err = c.SendRequest("POST", "file-systems", nil, data)
…
var params = map[string]string{"names": accountuser}
_, err := c.SendRequest("DELETE", "object-store-users", params, nil)
For the FlashBlade REST API, the request body data is encoded as JSON and request parameters are key/value pairs.
Note that creating the necessary parameters or request bodies required inspection of the REST API specification for the FlashBlade and a little reverse engineering of the Python SDK.
Userspace NFS
Traditionally, NFS leverages the NFS client in the Linux kernel. But this introduces extra dependencies in a plumbing test, i.e, the need to mount a filesystem using root privileges.
By using a userspace NFS library, the plumbing application does not require mounting from the host operating system. Instead the mount operation happens from within the Go code:
mount, err := nfs.DialMount("10.62.64.200", false)
…
auth := rpc.NewAuthUnix("anon", 1001, 1001)
target, err := mount.Mount("filesystem-name", auth.Auth(), false)
A key outcome of accessing NFS via userspace code is that the application operates the same inside and outside of container environments. This helps achieve the overall goal of eliminating dependencies for running the plumbing tool. For example, there is no need to configure a CSI driver inside of Kubernetes, or to have root privileges to mount on a bare-metal host. A second advantage is that multiple tcp connections are leveraged, resulting in higher performance similar to the nconnect kernel feature.
Reading and writing NFS files then follows the same Go patterns as writing to local files:
f, err := target.OpenFile(filename, os.FileMode(int(0744)))
n, _ := f.Write(srcBuf)
…
f, err := target.Open(filename)
<code”>n, err := f.Read(p)
AWS S3 SDK
The S3 protocol always leverages userspace code, meaning that I can simply use the AWS S3 SDK for Golang within the plumbing application. To use this library with FlashBlade, the S3 config object needs to include the endpoint parameter that corresponds to a data VIP on the FlashBlade.
s3Config := &aws.Config{
Endpoint: aws.String("10.62.64.200"),
Credentials: credentials.NewStaticCredentials(accessKey, secretKey, ""),
Region: aws.String("us-east-1"),
DisableSSL: aws.Bool(true),
S3ForcePathStyle: aws.Bool(true),
}
The operations to upload and download objects are the same as for any other S3 backend.
Example Results
Running the plumbing tool on a high-end client machine with 96 cores and 100Gbps networking results in client read throughputs averaging 6.2 GB/s for NFS and 7.7 GB/s for S3.

The corresponding GUI shows performance (throughput, IOPS, and latency) during the tests.
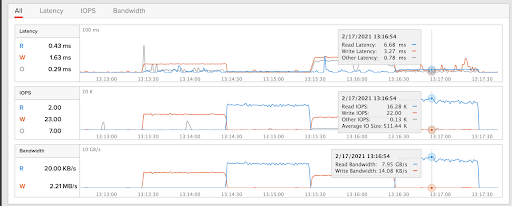
The FlashBlade itself can deliver more performance with more clients, and perhaps the client as well given that it has been tested and tuned on smaller client hardware profiles.
Conclusion
Most applications using high-performance file or object storage have bottlenecks either in the application or on the storage tier. But the first step in setting up an application is ensuring the underlying infrastructure is configured correctly and not introducing extra bottlenecks. I built the flashblade-plumbing tool to simplify the process of validating the networking layer between each client and FlashBlade with minimal dependencies or pre-configuration required. The result is a single program that requires two inputs, management VIP and login token, and automatically tests NFS and S3 throughput at multi-GB/s speeds.
![]()



