
Python is the de facto language for data science because of its ease of use and performance. But performance comes only because libraries like NumPy offload computation-heavy functions, like matrix multiplication, to optimized C code. Data science tooling and workflows continue to improve, data sets get larger, and GPUs get faster. So as object storage systems, like S3, become the standard for large data sets, the retrieval of data from object stores has become a bottleneck.
Slow S3 access results in idle compute, wasting expensive CPU and GPU resources. Almost all Python-based use of data in S3 leverages the Boto3 library, an SDK that enables flexibility but comes with the performance limitations of Python. Native Python execution is relatively slow and especially poor at leveraging multiple cores due to the Global Interpreter Lock (GIL).
There are other projects, such as a plugin for PyTorch or leveraging Apache Arrow via PyArrow bindings, that aim to improve S3 performance for a specific Python application. I have also previously written about issues with S3 performance in Python: cli tool speeds, object listing, Pandas data loading, and metadata requests.
This blog post points in a promising direction for solving the Python S3 performance problem: replacing Boto3 with equivalent functionality written in a modern, compiled language. My simple Rust reimplementation FastS3 results in 2x-3x performance gains versus Boto3 for both large object retrieval and object listings. Surprisingly, this result is consistent for both fast, all-flash object stores like FlashBlade®, as well as traditional object stores like AWS’s S3.
Experimental Results
Python applications access object storage data primarily through either 1) object store specific SDKs like Boto3 or 2) filesystem-compatible wrappers like s3fs and fsspec. Both Boto3 and s3fs will be compared against my minimal Rust-based FastS3 code to both 1) retrieve objects and 2) list keys.
S3fs is a commonly used Python wrapper around the Boto3 library that provides a more filesystem-like interface for accessing objects on S3. Developers benefit because file-based Python code can be adapted for objects with minimal or no rewrites. Fsspec provides an even more general interface that provides a similar filesystem-like API for many different types of backend storage. My FastS3 library should be viewed as a first step toward an fsspec-complaint replacement for the Python-based s3fs.
In Boto3, there are two ways to retrieve an object: get_object and download_fileobj. Get_object is easier to work with but slower for large objects, and download_fileobj is a managed transfer service that uses parallel range GETs if an object is larger than a configured threshold. My FastS3 library mirrors this logic, reimplemented in Rust. S3fs enables reading from objects using a pattern similar to standard Python file opens and reads.
The tests focus on two common performance pain points: retrieving large objects and listing keys. There are other workloads that are not yet implemented or optimized, e.g., small objects and uploads.
All tests are run on a virtual machine with 16 cores and 64GB DRAM and run against either a small FlashBlade system or AWS S3.
Result 1: GET Large Objects
The first experiment measures retrieval (GET) time for large objects using FastS3, s3fs, and both Boto3 codepaths. The goal is to retrieve an object from FlashBlade S3 into Python memory as fast as possible. All four functions scale linearly as the object size increases, with the Rust-based FastS3 being 3x and 2x faster than sf3s-read/boto3-get and boto3-download respectively.
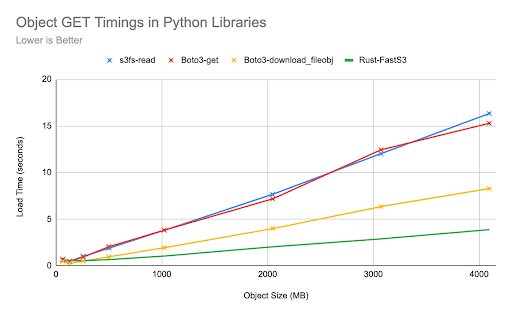
The relative speedup of FastS3 is consistent from object sizes of 128MB up to 4GB.
Result 2: GETs on FlashBlade vs. AWS
The previous results focused on retrieval performance against a high-performance, all-flash FlashBlade system. I also repeated the experiments using a traditional object store with AWS’s S3 and found similar performance gains. The graph below shows relative performance of FastS3 and Boto3 download(), with values less than 1.0 indicating Boto3 is faster than FastS3.
For objects larger than 1GB-2GB, the Rust-based FastS3 backend is consistently 2x faster at retrieving data than Boto3’s download_fileobj function, against both FlashBlade and AWS. Recall that download_fileobj is significantly faster with large objects than the basic Boto3 get_object function. As a result, FastS3 is at least 3x faster than Boto3’s get_object. The graph compares FastS3 against download_fileobj because it is Boto3’s fastest option, though it is also the least convenient to use.
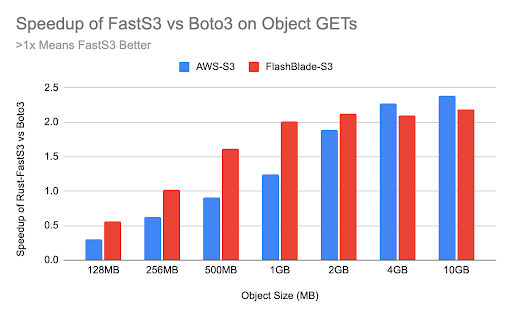
For objects smaller than 128MB-256MB, the FastS3 calls are slower than Boto3, indicating that there are still missing optimizations in my FastS3 code. FastS3 currently uses 128MB as the download chunk size to control parallelism, which works best for large objects but clearly is not ideal for smaller objects.
Result 3: Listing Objects
Performance on metadata listings is commonly a slow S3 operation. The next test compares the Rust-based implementation of ls(), i.e., listing keys based on a prefix and delimiter with a prefix, with Boto3’s list_objects_v2() and s3fs’s ls() operation. The objective is to enumerate 400k objects with a given prefix.
Surprisingly, FastS3 is significantly faster than Boto3 at listing objects, despite FastS3 not being able to leverage concurrency. The FastS3 listing is 4.5x faster than Boto3 against FlashBlade and 2.7x faster against AWS S3.
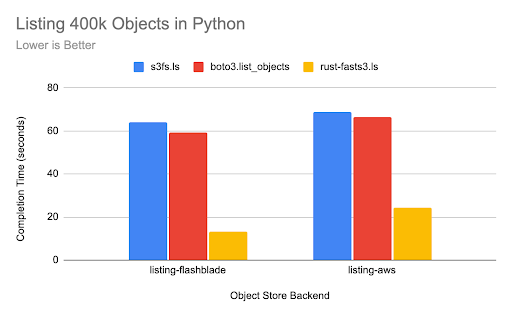
The s3fs implementation of ls() also introduces a slight overhead of 4%-8% when compared to directly using boto3 list_objects_v2.
Code Walkthrough
All the code for FastS3 can be found on GitHub, including the Rust implementation and a Python benchmark program.
I leverage the Pyo3 library to create the bindings between my Rust functions and Python. I also use the official AWS SDK for Rust, which at the time of this writing is still in tech preview at version 0.9.0. The Rust code issues concurrent requests to S3 using the Tokio runtime.
Build the Rust-FastS3 library using maturin, which packages the Rust code and pyo3 bindings into a Python wheel.
maturin build --release
The resulting wheel can be installed as with any Python wheel.
python3 -m pip install fasts3/target/wheels/*.whl
Initialization logic for Boto3 and FastS3 are similarly straightforward, using only an endpoint_url to specify FlashBlade data VIP or an empty string for AWS. The access key credentials are found automatically by the SDK, e.g., as environment variables or a credentials file.
<code">import boto3
import fasts3
s3r = boto3.resource('s3', endpoint_url=ENDPOINT_URL) # boto3
<code">s = fasts3.FastS3FileSystem(endpoint=ENDPOINT_URL) # fasts3 (rust)
And then FastS3 is even simpler to use in some cases.
# boto3 download_fileobj()
bytes_buffer = io.BytesIO()
s3r.meta.client.download_fileobj(Bucket=BUCKET, Key=SMALL_OBJECT, Fileobj=bytes_buffer)
# fasts3 get_objects
contents = s.get_objects([BUCKETPATH])
FastS3 requires the object path to be specified as “bucketname/key,” which maps to the s3fs and fsspec API and treats the object store as a more generic file-like backend.
The Rust code for the library can be found in a single file. I am new to Rust, so this code is not “well-written” or idiomatic Rust, just demonstrative. To understand the flow of the Rust code, there are three functions that serve as interconnects between Python and Rust: new(), ls(), and get_objects().
pub fn new(endpoint: String) -> FastS3FileSystem
This function is a simple factory function for creating a FastS3 object with the endpoint argument that should point to the object store endpoint.
pub fn ls(&self, path: &str) -> PyResult<Vec<String>>
The ls() function returns a Python list[] of keys found in the given path. The implementation is a straightforward use of a paginated list_objects_v2. There is no concurrency in this implementation; each page of 1,000 keys is returned serially. Therefore, any performance advantage of this implementation is strictly due to Rust performance gains over Python.
pub fn get_objects(&self, py: Python, paths: Vec<String>) -> PyResult<PyObject>
The get_objects functions take a list of paths and concurrently download all objects, returning a list of Bytes objects in Python. Internally, the function first issues a HEAD request to all objects in order to get their sizes and then allocates the Python memory for each object. Finally, the function concurrently starts retrieving all objects, splitting large objects into chunks of 128MB.
A key implementation detail is to first allocate the memory for the objects in Python space using a PyByteArray and then copy downloaded data into that memory using Rust, which avoids needing a memory copy to move the object data between Rust and Python-managed memory.
As a side note, dividing a memory buffer into chunks so that data can be written in parallel really forced me to better understand Rust’s borrow checker!
What About Small Objects?
Notably lacking in the results presented are small objects retrieval times. The FastS3 library as I have written it is not faster (and sometimes slower) than Boto3 for small objects. But I am happy to speculate this is nothing to do with the language choice but largely because my code is so far only optimized for large objects. Specifically, my code does a HEAD request to retrieve the object size before starting the downloads in parallel, whereas with a small object, it is more efficient to just GET the whole data in a single remote call. Clearly, there is opportunity for optimization here.
Summary
Python prominence in data science machine learning continues to grow. And the mismatch in performance between accessing object storage data and compute hardware (GPUs) continues to widen. Faster object storage client libraries are required to keep modern processors fed with data. This blog post has shown that one way to significantly improve performance is to replace native Python Boto3 code with compiled Rust code. Just as NumPy makes computation in Python efficient, a new library needs to make S3 access more efficient.
While my code example shows significant improvement over Boto3 in loading large objects and metadata listings, there is still room for improvement in small object GET operations and more of the API to be reimplemented. The goal of my Rust-based Fasts3 library is to demonstrate the 2x-3x scale of improvements possible to encourage more development on this problem.
![]()



