As you might’ve seen, Cormac Hogan just posted about an UNMAP fix that was just released. This is a fix I have been eagerly awaiting for some time, so I am very happy to see it released. And thankfully it does not disappoint.
First off, some official information:
Release notes:
https://kb.vmware.com/s/article/2148989
UNMAP Manual patch download:
Or you can run esxcli if you ESXi host has internet access to download and install automatically:
|
1 |
esxcli software profile update –p ESXi–6.5.0–20170304001–standard –d https://hostupdate.vmware.com/software/VUM/PRODUCTION/main/vmw-depot-index.xml |
Note, don’t forget to open a hole in the firewall first for this download. Of course, any time you open your firewall you create a security vulnerability, so if this is too much of a risk, go with the manual download method here:
|
1 |
esxcli network firewall ruleset set –e true –r httpClient |
Then close it again:
|
1 |
esxcli network firewall ruleset set –e false –r httpClient |
The UNMAP problem
This is about in-guest UNMAP, which I have blogged about quite a bit in the past:
- What’s new in ESXi 6.5 Storage Part IV: In-Guest UNMAP CBT Support
- (Windows) Direct Guest OS UNMAP in vSphere 6.0
- (Linux) What’s new in ESXi 6.5 Storage Part I: UNMAP
So the problem that was solved by this patch was the issue that guest OSes were not sending UNMAP commands down to ESXi that were aligned. ESXi requires that these commands be aligned to 1 MB boundaries and the vast majority of UNMAP commands that were sent down were simply not aligned. Therefore, every UNMAP would fail and no space would be reclaimed. Even if “part” of it was aligned. There were a variety of ways to work around this, such as in Windows:
Allocation Unit Size and Automatic Windows In-Guest UNMAP on VMware
Changing the allocation unit size in NTFS helped make UNMAPs much more likely to be aligned, but not always.
Linux fstrim command was almost completely useless though because of the alignment issue and not much could be done about that–luckily though the discard option in Linux generally issued aligned UNMAPs, so it didn’t matter as much. Let’s take a look a Windows in this post. I will post soon about Linux.
UNMAP Testing with Windows 2012 R2
Any Windows release Windows 2012 R2 and later supports UNMAP, but they all suffer from this granularity issue. So let’s do a quick test. Using Windows 2012 R2 on the original release of ESXi 6.5 (without the patch).
I have a VM with a thin virtual disk on a FlashArray VMFS datastore and I put a bunch of ISOs on it. About 25 GB worth.
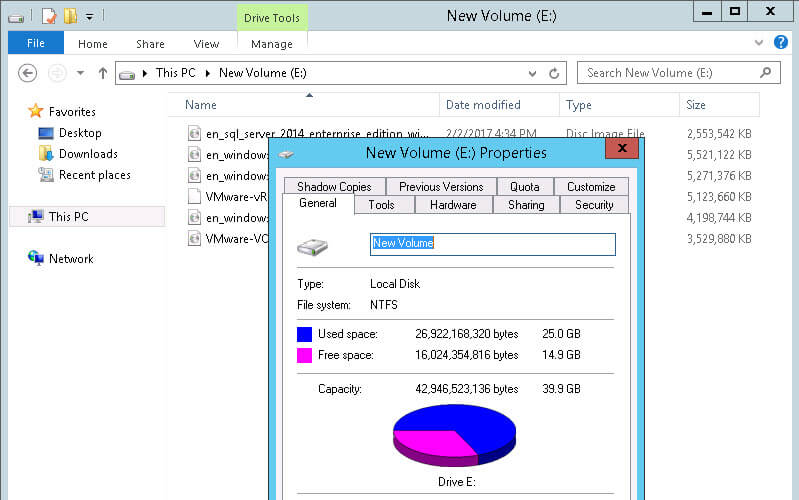
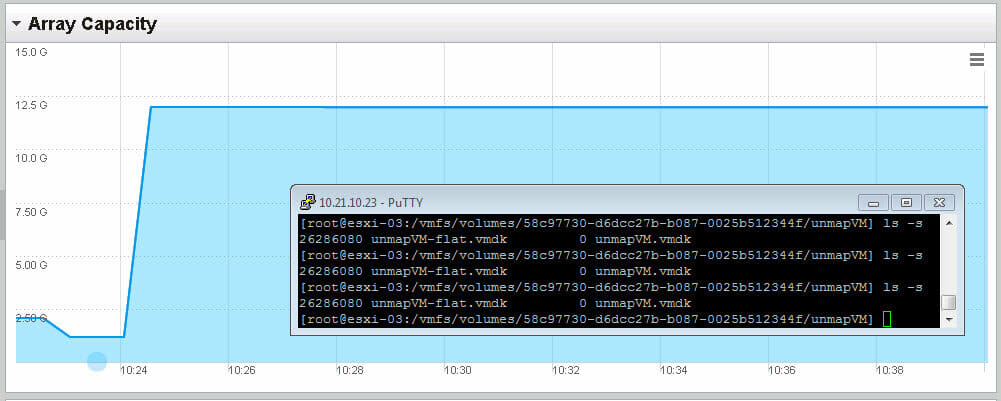
We can see my virtual disk is the same size (note the file unmapVM-flat.vmdk):

And the volume on the FlashArray reports about 12 GB (due to data reduction it is less than 25):
So now I will permanently delete the files. When a file is permanently deleted (or deleted from the recycling bin) NTFS is configured automatically to issue UNMAP. The problem here is that my allocation unit size is 4 K which means that most UNMAPs will be misaligned and nothing is going to get reclaimed.
So the delete:
After waiting a few minutes we can see nothing has happened. The virtual disk has not shrunk from UNMAPs and the FlashArray reflects no capacity returned.
To be sure, let’s try the disk optimize operation. This allows you to manually execute UNMAP against a volume.

Still nothing happens.
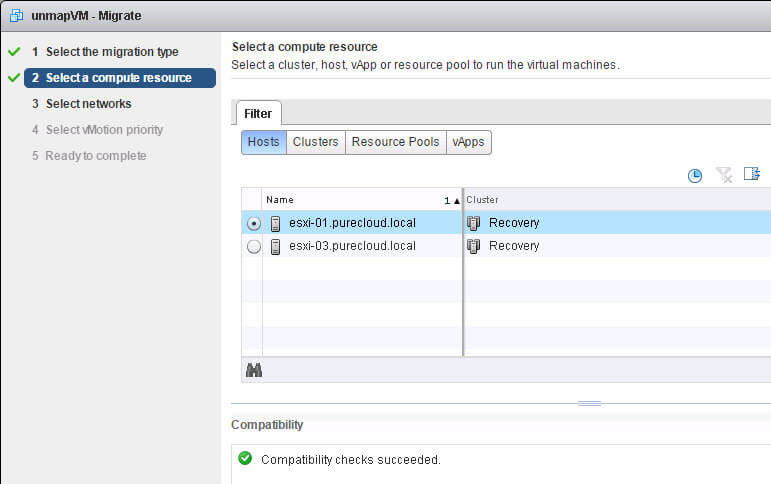
Okay, let’s vMotion this from my un-patched ESXi host to my patched ESXi host.
The vMotion, with no other reconfiguration other than moving the VM to this host:
Now we can run the optimize again with it on the patched host:

Wait a minute or two and we now see the virtual disk has shrunk:
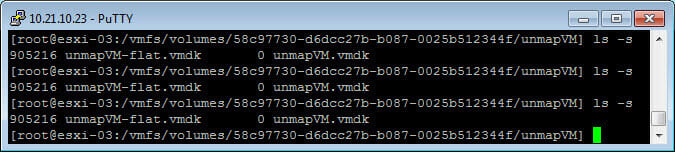
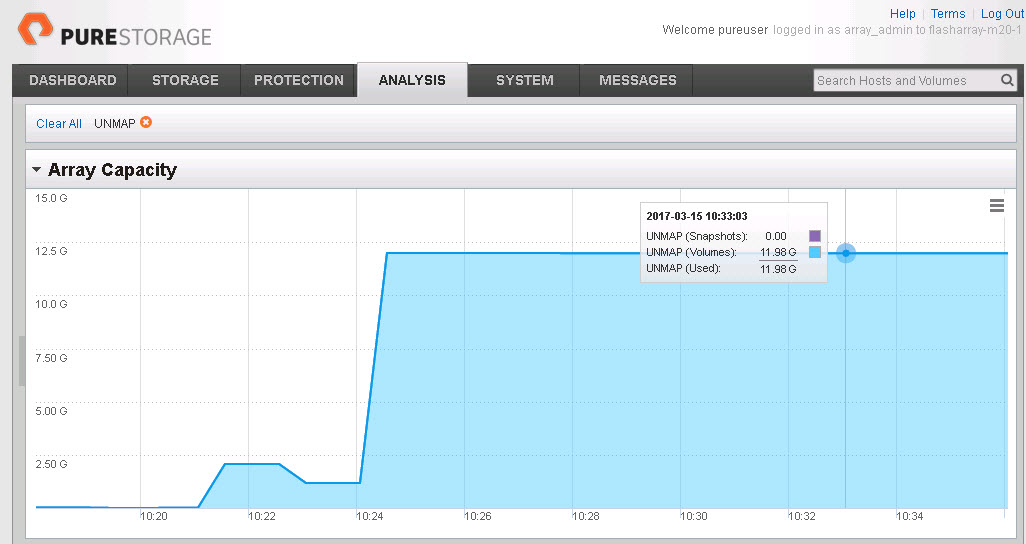
Now it is not down to zero, it is about 900 MB, but certainly smaller than 25 GB. The reason for this is that certain amount of UNMAPs were misaligned, so ESXi did not reclaim them. Instead, ESXi just zeroes that part out. But if we look at the FlashArray, we see ALL of the space was reclaimed:
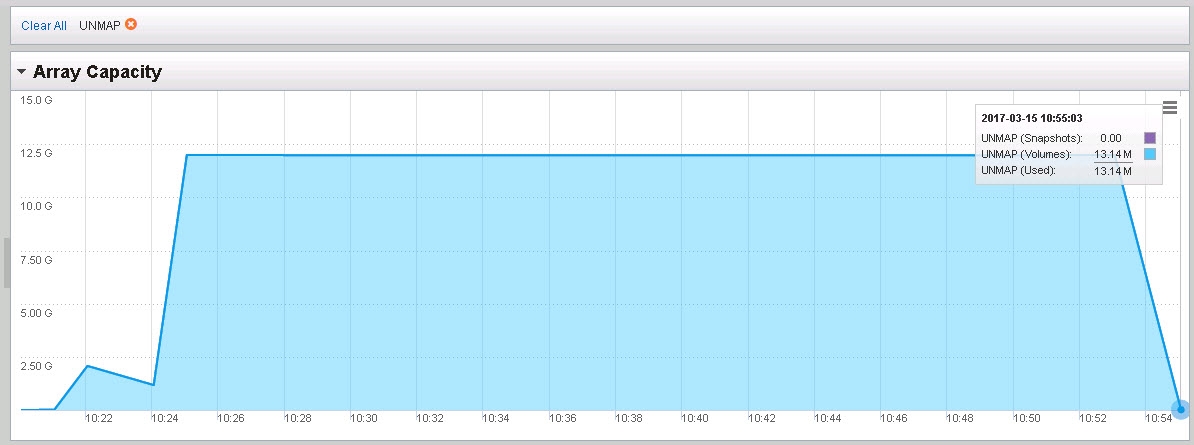
Sweet!! So why did the FlashArray reclaim it all and ESXi didn’t? Well because ESXi still wrote zeroes to the LBAs that were identified by the misaligned UNMAPs. The FlashArray discards contiguous zeros and removes any data that used to exist where the zeros were written. Which makes writing zeros to the FlashArray identical in result to running UNMAP. So this works quite nicely on the FlashArray or any array for that matter that removes zeroes on the fly.
So let’s test this now with automatic UNMAP in NTFS. I will keep my VM on the patched host and put some files back on the NTFS volume, so it is 25 GB again.
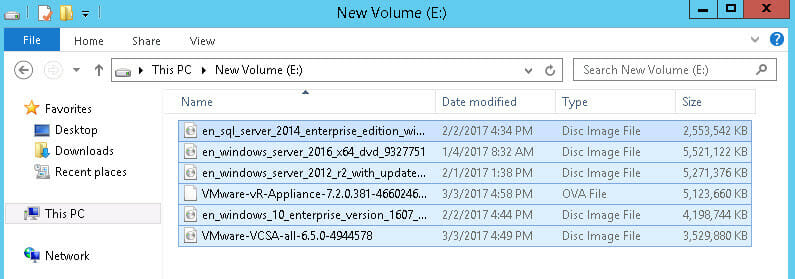
We see on our VMFS the space usage is back up and so is it on the FlashArray:
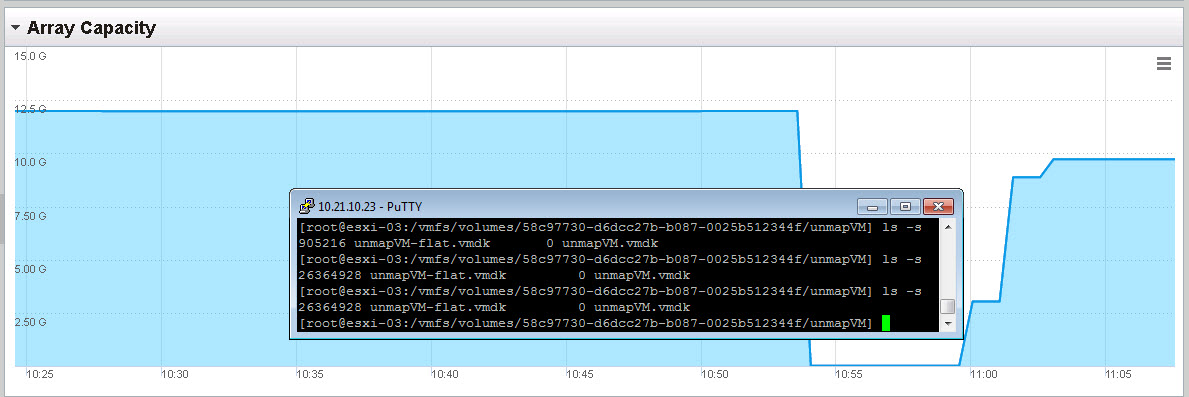
I will delete the files permanently again, but this time rely on automatic UNMAP in NTFS to reclaim the space, instead of using Disk Optimizer.

We can see the virtual disk is now shrunk (takes about 30 seconds or so)
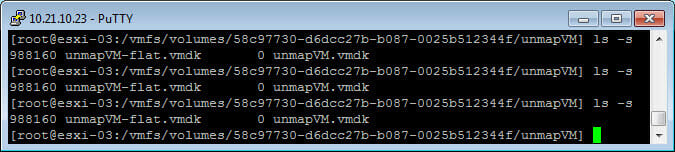
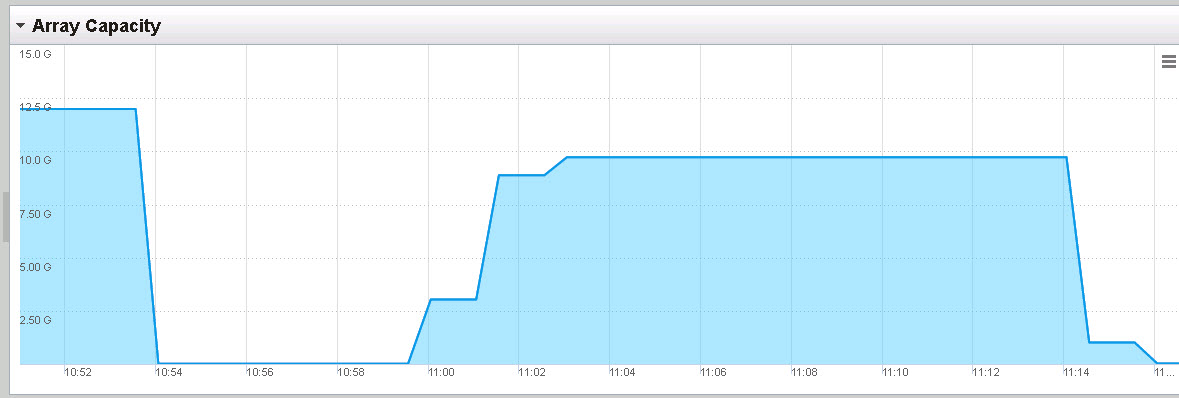
And we can see the FlashArray is fully reclaimed:
Does Allocation Unit Size Matter Now?
So do I need to change my allocation unit size now? You certainly do not have to. But there is still some benefit from the VMware side from doing so. This fix allows you to be 100% efficient from the underlying storage side regardless, but if you want the VMDK to be shrunk as much as possible, 32 K or 64 K will get you as close as possible to fully shrunk as more UNMAPs will be aligned.
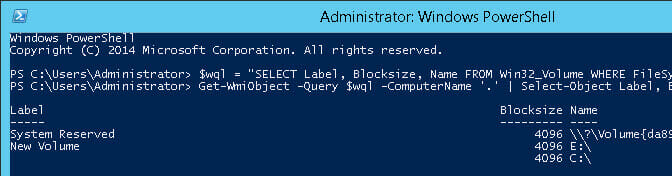
So if I add another thin VMDK and put 25 GB on it you see that reflected in the filesystem. Notice my original, reclaimed virtual disk is 900 MB after reclaim.
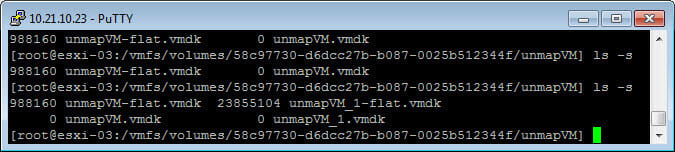
The original VMDK has a 4 K allocation unit size and my new one uses 64 K:
Now if I permanently delete the files, we see my virtual disk has shrunk a lot more than my 4 K NTFS formatted VMDK:
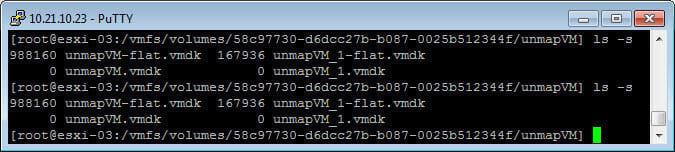
988 MB compared to 168 MB. A decent difference. So it might be still advisable to do this in general, to make VMFS usage as accurate as possible. But I will re-iterate, from a physical storage perspective, it does not matter what you use as an allocation format–all of it will be reclaimed on the FlashArray. There is just a logical/VMFS allocation benefit to 64 K.
Zeroing Behavior
For those who are curious, what does ESXi do during this shrunk? As I can see, it does the following:
- Receives the UNMAPs
- Shrinks the virtual disk
- Issues WRITE SAME to zero out the misaligned segments
This can be proven out with esxtop. Looking at the VAAI counters, specifically, ATS and WRITESAME (ATS and ZERO). We can see for the specific device (in this case naa.624a93704bfab20d4b694df700014cd1) the ATS counters first go up, then the zero ones do. This to me means that the virtual disk was shrunk first, and a filesystem allocation change like that will invoke ATS operations. Then we see WRITE SAME commands come down, which is zeroing out the blocks referred to by the misaligned UNMAPs.
Before:
After:
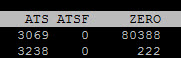
You can see both counters for that device have gone up. If you watch it live, you can see the order.
Lastly, can I manually remove the zeros that have been WRITESAME’ed to the virtual disk. The answer is yes, but it is an offline procedure. So you either need to power-down the virtual machine, or remove the virtual disk temporarily from the VM.
The procedure to do this is called “punching zeros” and can be done with the vmkfstools command:
|
1 |
vmkfstools –K /vmfs/volumes/UNMAP/unmapVM/unmapVM.vmdk |
So if we take our virtual disks again and I remove the first one which is currently 988 MB:
Then we run punch zero:

And now the virtual disk is down to 66 MB! It is offline, which isn’t great, but at least it is an option.

Final Notes on UNMAP
Now if you do not see anything on the FlashArray, this means you did not enabled the ESXi option “EnableBlockDelete” which is disabled by default. This is what allows ESXi to translate the UNMAPs down to the array level.
Because of everything above, I highly recommend applying this patch ASAP.



