In the Beyond DAS: MongoDB on FlashArray™ with NVMe-oF RoCE blog post published in February of 2019, we explored the advantages of running MongoDB on FlashArray products such as performance, efficient storage and failure management. We also provided analysis of MongoDB disk space consumption. In this post we will explore in greater detail how much storage space FlashArray can save you compared to Direct-Attached Storage. We will also look at FlashArray’s data reduction (compression and deduplication) and weigh it against compression offered by MongoDB.
MongoDB
MongoDB with WiredTiger engine can compress data collections, indexes and journals. By default, WiredTiger uses snappy compression. The zlib compressor is also available. Generally, compression will consume more CPU cycles but it will lower disk space utilization. MongoDB provides an easy means of controlling which database objects will be compressed and which compression library to use. Detailed documentation describing how to make MongoDB compression changes is available at https://docs.mongodb.com/manual/core/wiredtiger/#compression and a partial mongod.conf file is listed in the appendix below showing required database parameters to disable index, journal, and collection compression.
FlashArray
FlashArray data reduction services are always enabled. FlashArray compresses and deduplicates data globally (array-wide) rather than on a per-volume basis, which usually results in better data reduction rates. Additionally, FlashArray will periodically rescan volumes for “deeper” deduplication, frequently resulting in higher data reduction ratios over time. For this test we used a FlashArray //M20 with Purity (FlashArray operating system) version 5.2.1. Because the Purity version is the same for all supported FlashArrays the data reduction ratios are independent of the FlashArray model. See a live data reduction and total efficiency average ticker across the entire Pure Storage FlashArray installed base at https://www.purestorage.com/products.htmlstorage-software/purity/store.html.
Methodology
The data reduction rate depends on the type of data stored on FlashArray. Because of the array-wide data reduction, the FlashArray under test contained only a sample data set. All other volumes and snapshots were deleted and eradicated. Applications such as offload and WFS were uninstalled as these objects may also impact the data reduction. The sample data set was a 457 GB database with over 1 billion documents. This data was loaded into a single MongoDB 4.0.7 node installed on CentOS 7. The xfs formatted database volume (dbpath) corresponded to a dedicated FlashArray LUN.
The test data set we used is publicly available from the New York City Taxi And Limousine Commission at https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page and includes taxi trip information from 2009 to 2014.
After loading data, the standalone MongoDB instance was converted to a three node, five node and seven node replica set. Each replica set node was configured with a dedicated volume on FlashArray. The data deduplication ratios on FlashArray were obtained at least an hour after the data was loaded. The same tests were repeated with MongoDB compression disabled.
Data Load
The New York City taxi trip data is distributed in CSV format which can be easily imported into MongoDB using mongoimport command, for example:
mongoimport -h mongo01 -j 8 –headerline –type csv -d nyc -c yellow ./yellow_tripdata_2009-01.csv
where h is the mongoDB host, j the number of insert operations, d the database name to import to, c the collection name and finally, yellow_tripdata_2009-01.csv the data file name to import, –headerline instructs the mongoimport tool to use the column names in the first line as field names.
Results
To increase the accuracy of the collected data, data reduction results were obtained using show dbs and df -h commands on MongoDB host and purevol list –space command on FlashArray. The purevol list –space command reports data reduction and size on a per-volume basis, the average data reduction ratio and the average disk space consumed values are listed in the tables below. For an example of the purevol list –space command output see Appendix.
MongoDB Compression Enabled
| Replica Set Size | One node | Three nodes | Five nodes | Seven Nodes |
| MongoDB show dbs | 135.155 GB | 135.155 GB | 135.155 GB | 135.155 GB |
| Linux df -h | 136 GB | 136 GB | 136 GB | 136 GB |
| FlashArray purevol list –space | 92.55 GB | 91.59 GB | 87.82 GB | 85.77 GB |
| FlashArray Data Reduction Ratio from purevol list –space command | 1.5:1 | 1.5:1 | 1.6:1 | 1.6:1 |
MongoDB Compression Disabled
| Replica Set Size | One Node | Three Nodes | Five Nodes | Seven Nodes |
| MongoDB show dbs per node | 456.77 GB | 456.77 GB | 456.77 GB | 456.79 GB |
| Linux df -h per node | 458 GB | 458 GB | 458 GB | 458 GB |
| FlashArray purevol –space Average per node | 87.2 GB | 78.07 GB | 73.46 GB | 72.15 GB |
| FlashArray Data Reduction Ratio from purevol list –space command | 5.3:1 | 5.7:1 | 6.0:1 | 6.1:1 |
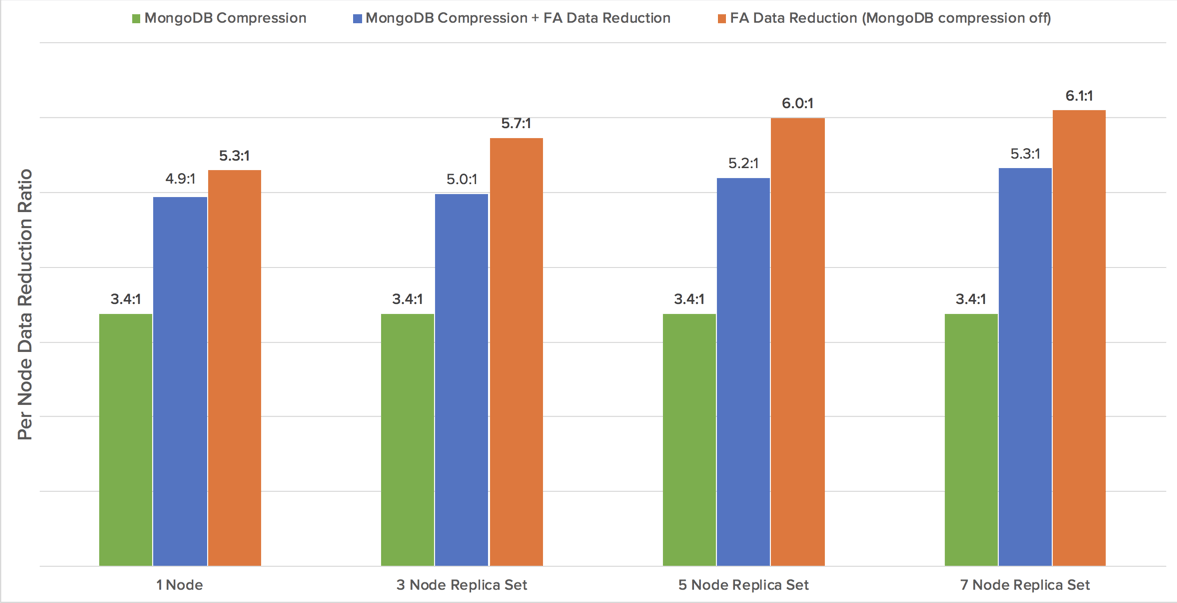
A comparison of the data reduction ratios for MongoDB compression, FlashArray data reduction with MongoDB compression and FlashArray data reduction without MongoDB compression is shown in the chart below.
Conclusion
Based on the collected data, FlashArray with MongoDB compression disabled resulted in the highest data reduction. For hosts with Direct-Attached Storage for this data set we can expect a 3.4:1 MongoDB compression ratio. For FlashArray, data reduction ranged from 5.3:1 to 6.1:1 as the number of nodes in a replica set increased.
Besides lowering disk space consumption, FlashArray also provides proven 99.9999% availability and consistent, low-latency, high performance storage. With FlashArray data reduction services your MongoDB servers will require less storage AND less compute power, resulting in lower cost of ownership.
In the next blog I will compare performance of MongoDB on FlashArray with and without the database compression.
Appendix
Partial mongod.conf file with compression disabled:

Sample output of purevol list –space command: