


From self-driving cars and financial transactions to transit systems, many use cases require the ability to process data locally in near real-time. Because speed is critical, there’s no time to transfer all that data back to the public cloud.
As a result, many organizations are extending their public-cloud projects to private, on-premises locations and building a hybrid-cloud solution.
AWS Outposts enables you to meet local data-processing or low-latency requirements. With an Outpost rack, you can deploy Amazon Web Services compute hardware in your data center.
Hybrid-cloud Models for AI Deployments
As data-science teams ramp up their models to production, they have to support larger-scale data ingestion and data processing as part of inference.
Often the performance penalty (or cost) of transferring large data sets into the public cloud is prohibitive. In addition, the connection from edge to public cloud may be unreliable. Because of these limitations, teams with massive data ingest are relocating AI inference from the public cloud to edge data centers.
Note: In this case, we use “edge” to mean the distributed computing model where service delivery is performed at multiple edge sites such as colocation facilities.
Teams may centralize model development in the public cloud and then deploy finalized models into edge data centers for inference. Teams can perform initial analytics at the edge to identify anomalies or interesting data points to send back to the public cloud for further analysis or retraining.
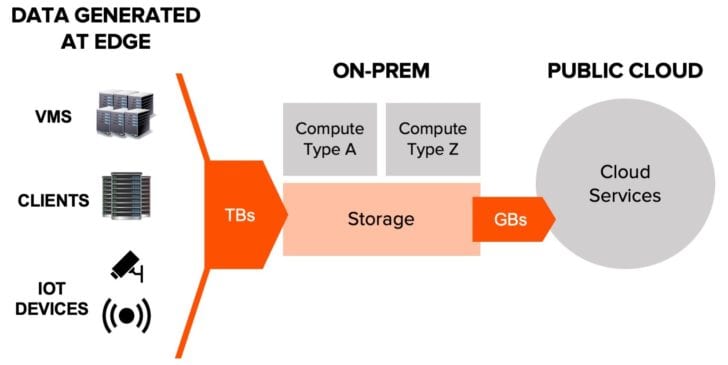
Example hybrid-cloud deployment.
For example, an autonomous-vehicle company might have a fleet of cars driving around generating 2TB logs of data per vehicle each day. Yet, their computer vision training datasets might not have enough samples of a specific signpost variant (or other things the cars might cross paths with). So, the company’s data scientists might perform inference at the edge location to pull out data points with these high-value anomalies that they can then feed into model retraining.
The full datasets are ingested into local servers, and AWS Outposts—maybe even a GPU Outpost configuration—can be used as the edge compute for inference.
Access Data on Local Servers from Outpost EC2 Instances
A senior solutions architect at AWS, Josh Coen, wrote a great article that highlights the simplicity of the networking paths between an Outpost and an adjacent storage device.
After setting up connectivity, it’s easy to start using those external datasets. EC2 instances inside an Outpost can interact with on-prem file and object data.
Prerequisites:
- Outpost configuration: Launch an EC2 instance within the Outpost via the AWS Outposts Console. Verify that the instance can ping devices on your local network.
- FlashBlade® configuration: Create a subnet, a data VIP, and a filesystem for file testing. Create an Object Store user and a bucket for object testing.
Connect to File Storage
Use the data vip to mount the filesystem to a directory inside the instance. Example:
|
1 2 |
mkdir -p /mnt/datasets mount -t nfs 10.21.239.11:/datasets /mnt/datasets |
That’s it!
Confirm via 'ls' that the contents of the mounted filesystem appear as expected from within the EC2 instance.
Connect to Object Storage
Like the process for in-Region instances, an IAM role with Amazon S3 access must be associated with the instance before users can access S3. (For more information, refer to the AWS Command Line Interface User Guide.)
Use the 'aws configure' command to add the Access Key ID and Secret Access Key for the FlashBlade object storage user.
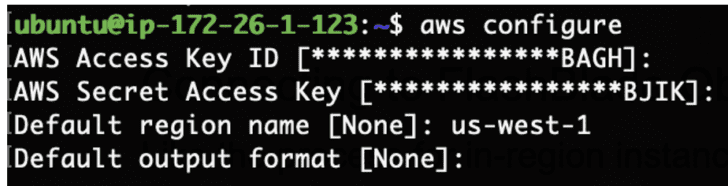
That’s it!
Use the 'aws s3 ls' command to verify that the EC2 instance has access to buckets on the FlashBlade. Because the system is using a custom endpoint instead of the default AWS S3, specify an '--endpoint-url' with the previously-created data VIP on FlashBlade.
|
1 |
aws --endpoint-url https://10.21.239.11 s3 ls |
At this point, the Outpost EC2 instance is ready to consume both file and object data stored on FlashBlade.
Access Local Data Sets from EMR Clusters inside the Outpost
It’s often insufficient only to perform inference directly from raw data at the edge. Organizations frequently choose to preprocess the data or otherwise manipulate it before running inference. You can use a service like AWS EMR to perform preprocessing steps inside the Outpost.
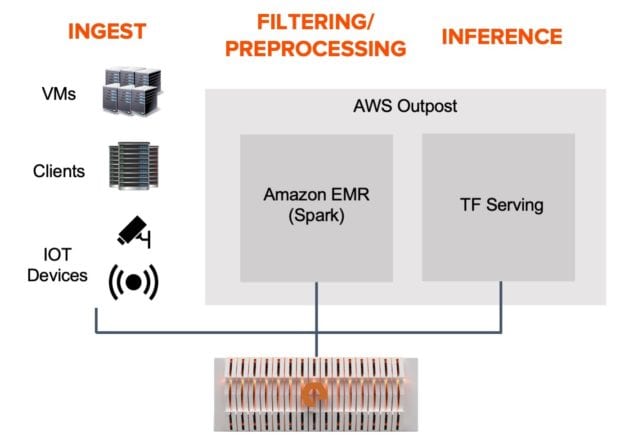
Example on-prem inference pipeline. Both file and object protocol workloads are supported.
To simplify infrastructure, utilize the same shared storage across the entire edge analytics pipeline.
Deployment
Note: For instructions on launching Amazon EMR clusters into an Outpost, see my post “Create Amazon EMR Clusters on AWS Outposts.”
Once you have the cluster instance(s) running, it’s easy for cluster workloads to access data on the local storage server. To access objects on FlashBlade S3 from this cluster, submit a job with the FlashBlade endpoint and credentials included.
Example:
|
1 2 3 4 5 6 7 |
spark-submit --conf spark.hadoop.fs.s3a.endpoint=https://10.21.239.11 \ --conf "spark.hadoop.fs.s3a.access.key=#########################################" \ --conf "spark.hadoop.fs.s3a.secret.key=#########################################" \ --master yarn \ --deploy-mode cluster \ wordcount.py \ s3a://emily-outpost-bucket/sample.txt |
Alternatively, document the FlashBlade specs in the spark-defaults.conf file to use them by default automatically.
vi /etc/spark/conf.dist/spark-defaults.conf
Add the following lines to the bottom of the file:
|
1 2 3 4 5 6 7 8 9 10 |
spark.hadoop.fs.s3a.endpoint 10.21.239.11 # YOUR FLASHBLADE DATA VIP spark.hadoop.fs.s3a.access.key=######################################### spark.hadoop.fs.s3a.secret.key=######################################### # Suggested tuning for FlashBlade performance. spark.hadoop.fs.s3a.fast.upload true spark.hadoop.fs.s3a.connection.ssl.enabled false spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version 2 spark.hadoop.mapreduce.input.fileinputformat.split.minsize 541073408 |
You can now submit jobs without specifying the FlashBlade specs in-line:
|
1 2 3 4 |
spark-submit --master yarn \ --deploy-mode cluster \ wordcount.py \ s3a://emily-outpost-bucket/sample.txt |
Takeaways
Hybrid-cloud deployments are becoming more common, especially to support edge analytics. Using FlashBlade as a storage server, we demonstrated the quick steps to use local file and object storage with AWS Outpost EC2 instances. This enables data scientists to deploy edge inference pipelines that can consume large datasets and perform analytics locally.
Using performant local storage with Outposts helps eliminate the latency of sending analytics queries to the public cloud and the transfer time incurred by pushing all edge data to the public cloud. (And it might even help in complying with data-governance mandates.) By pairing simple-to-manage compute and storage infrastructures, you can make hybrid-cloud deployments easier.
Learn more about Pure Storage hybrid-cloud solutions and Pure’s partnership and Pure’s partnership with AWS.
To get started right away, contact aws@purestorage.com.



