
What is NVMe-oF?
NVMe over Fabrics (NVMe-oF) is an emerging storage technology that is beginning to take hold in the data center. This protocol is set to disrupt the storage networking space thanks to its ability to provide low latency and high data transfer speeds.
Before we dig deeper into NVMe-oF, let’s first take a quick look at its history and how it evolved.
Hard disk drives (HDD) were the storage medium of choice until recently, and used interfaces like SCSI/SAS or SATA to communicate with the host bus adapter. As the price of flash memory dropped, SSDs started becoming more common place. Since SSDs do not contain any moving parts, they are much faster than HDDs. Because of that SSD’s performance started exceeding the speed of the data bus, which was developed for use with HDDs. It became evident that a new set of protocols and standards were needed that would be designed specifically to take advantage of solid-state technology.
NVMe is a host controller interface and storage protocol that was created by an industry body called “NVM Express Inc” as a replacement for SCSI/SAS and SATA. It enables fast transfer of data over a computer’s high-speed Peripheral Component Interconnect Express (PCIe) bus. It was designed from the ground up for low-latency solid state media, eliminating many of the bottlenecks seen in the legacy protocols.
NVMe devices are connected to the PCIe bus inside a server. The natural next step is to bring the benefits of NVMe to storage networks. NVMe-oF extends the high-performance and low-latency benefits of NVMe across network fabrics that connect servers and storage. NVMe-oF takes the lightweight and streamlined NVMe command set, and the more efficient queueing model, and replaces the PCIe transport with alternate transports, like Fibre Channel, RDMA over Converged Ethernet (RoCE), TCP.
Why is NVMe-oF better?
NVMe is a great way to exchange data with direct attached storage (DAS), but DAS has its disadvantages. Disk and data are siloed and available capacity cannot be used efficiently. Moreover, data services that are included with any enterprise class storage array are missing.
Pure’s FlashArray//X with NVMe-oF provides the best of both worlds – efficiency and performance of NVMe, and the benefits of shared accelerated storage with advanced data services like redundancy, thin provisioning, snapshots and replication.
NVMe-oF provides better performance for the following reasons:
- Lower latency
- Higher IOPs
- Higher bandwidth
- Improved protocol efficiency by reducing the “I/O stack”
- Lower CPU utilization on the host by offloading some processing from the kernel to the HBA.
Oracle on NVMe-oF
A large number of FlashArray customers are running Oracle databases. DBAs are under constant pressure to deliver fast response time to user applications. Oracle databases already benefit from the exceptional performance of the FlashArray//X family of arrays, but with DirectFlash Fabric, it gets even better. In order to demonstrate the performance and efficiency achieved by DirectFlash Fabric, we ran SLOB and HammerDB tests to compare performance of iSCSI vs NVMe-oF.
Test Environment Setup
Oracle database 18c Enterprise edition was installed on two identical servers running RedHat 7.6. The servers were commodity x86 servers with two Intel Xeon CPU E5-2697 v2 @ 2.70GHz with 12 cores each (totaling 24 cores) and 512GB of RAM.
Each server was connected to FlashArray//X90R2 using 2 Mellanox ConnectX-4 Lx (Dual Port 25GbE) adapters. Multipathing was enabled on both hosts.
Database DBTEST01 was configured with iSCSI as the transport and database DBTEST02 was configured with NVMe-oF. The load tests were carried out on each database server sequentially. Both databases had identical database configuration. The SGA was set to 5GB to minimize caching and maximize stress on the IO subsystem.
Oracle Performance test with SLOB : iSCSI vs NVMe-oF
We used the industry-respected SLOB benchmark kit to compare the performance of DirectFlash (NVMe-oF over RoCE) vs iSCSI. Multiple tests were performed with following SLOB settings:
- Think time set to 0
- Scalability test with 128 and 256 users
- Varying the read/update mix of workloads
- 100% reads
- 90% reads, 10% updates
- 70% reads, 30% updates
- 50% reads, 50% updates
While NVMe-oF resulted in higher bandwidth and lower latency as compared to iSCSI, the most significant gains were seen in the CPU utilization.
The following chart shows a comparison of the CPU utilization on the database server by various workloads with 128 concurrent users.
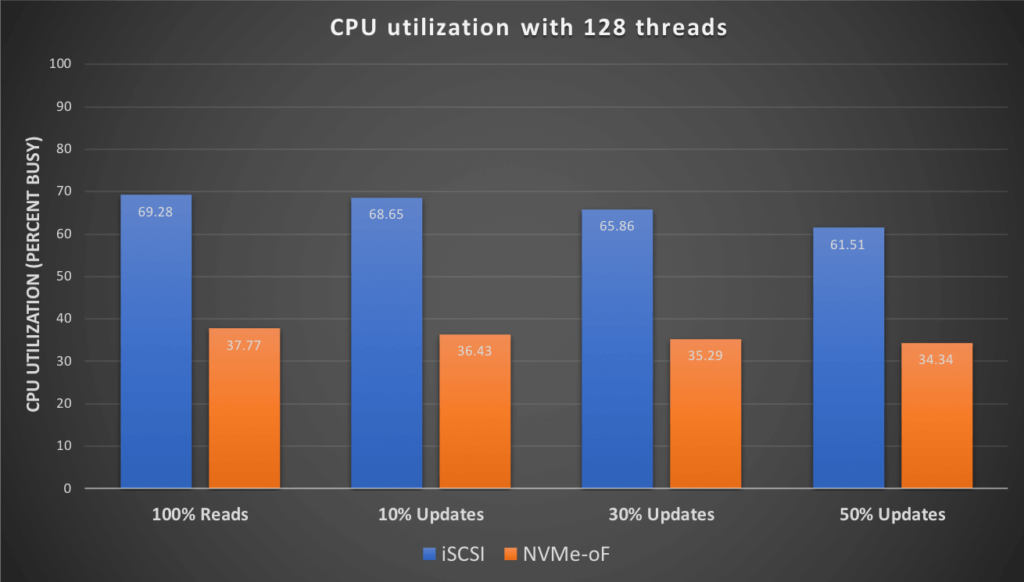
Similar results were seen when the load tests were run for 256 users.
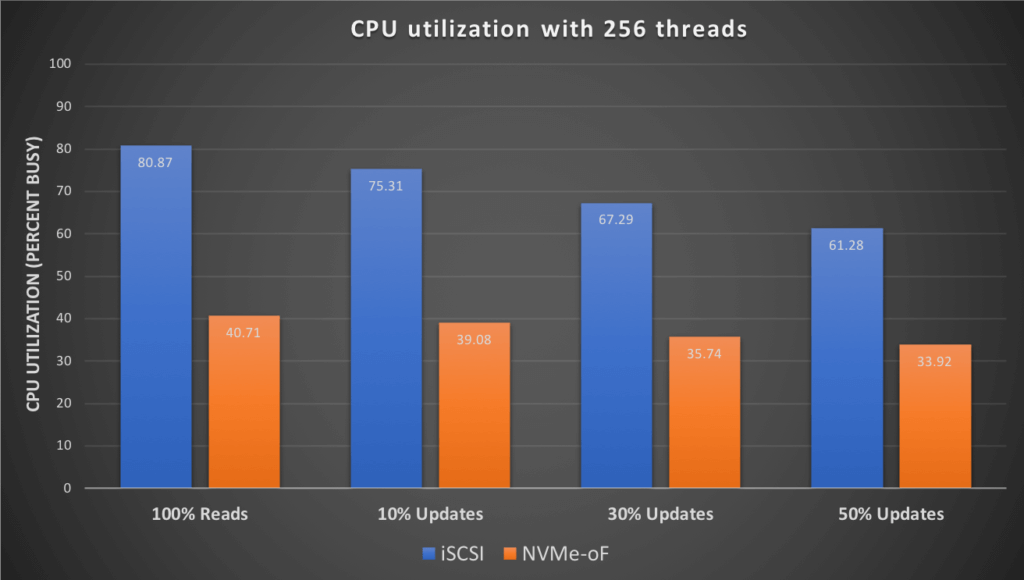
We see that there is a significant reduction in CPU utilization when using NVMe-oF as the transport. In our tests the average improvement was in the range of 40-45%. Note that these tests were designed to stress the IO by reducing the size of the buffer cache, and may not represent the typical production environment IO profile, your individual results may vary.
Oracle Performance test with HammerDB : iSCSI vs NVMe-oF
HammerDB program was used to execute a TPCC-like load test against both database servers.
This is how the test was set up:
- Four hosts were configured to generate load using the HammerDB program.
- Load generator hosts connected to the database servers over SQL*Net.
- Each load generator host had 24 cores.
- Each load generator was configured to run 96 vUsers.
- Each vUser executed 10 iterations with 1000 transactions per iteration.
- User Delay and Repeat Delay was set at 500 ms.
The following table summarizes the improvements that were observed:
| Improvement | |
| Test Completion Time | 7% |
| CPU Utilization % | 33% |
| Read IOPS | 9% |
| Write IOPS | 12% |
| Read Bandwidth (MB/s) | 9% |
| Write Bandwidth (MB/s) | 8% |
| Read Latency (ms) | 5% |
| Write Latency (ms) | 23% |
We can see that the NVMe-oF test exhibited lower latency, higher IOPs, higher bandwidth, and above all, much more efficient CPU utilization as compared to iSCSI.
Conclusion
These test results demonstrate that Pure’s DirectFlash Fabric built on NVMe-oF and FlashArray//X delivers higher performance and optimizes the use of CPU resources on the Oracle database server. As Oracle database servers are typically licensed per CPU core, this gives our customers one more reason to optimize their Oracle licenses by consolidating their workloads on fewer hosts, thereby resulting in lower TCO.
DirectFlash Fabric brings the low latency and high performance of NVMe technology to the storage network. It is available right now on RoCE transport starting with Purity 5.2. Support for other transports like Fibre Channel and TCP to follow.



