


This post is part 1 in a series on architecting Apache Kafka on Kubernetes with Portworx® by Pure Storage®.
Apache Kafka is an event-streaming platform that runs as a cluster of nodes called “brokers.” Initially developed as a messaging queue, you can use Kafka to process and store a massive amount of information. Kafka is extremely fast. We’ve benchmarked Kafka write speeds at 5 million messages/sec on Flasharray. Kafka seamlessly allows applications to publish and consume messages, storing them as records within a “topic.” Kafka allows applications to react to streams of data in real time, provide a reliable message queue for distributed systems, and stream data to IoT and AI/ML applications.
It’s challenging to provide this service at scale in production on Kubernetes. Be sure to carefully consider how to ensure persistence, data protection, security, data mobility, and capacity management for Kafka. Nevertheless, Kubernetes is becoming a standard across organizations for running cloud-native applications. There are many reasons why architecting Kafka on Kubernetes with Portworx can be appealing:
- All major clouds support Kubernetes, so it’s future-proof, enabling portability across many environments, providing flexibility without vendor lock-in.
- It can attract new DevOps skill sets for fueling innovation.
- Technology maturation has led to widespread adoption—even in production environments—cementing its place as the de facto leader.
- It provides built-in automation, high availability, rolling updates, role-based access control, and more—right out of the box.
These are all great reasons to run Kafka on Kubernetes. However, Kubernetes alone doesn’t solve all enterprise obstacles when it comes to cloud-native data management. Kubernetes does provide a pluggable system to allow for dynamic provisioning for stateful workloads, but it doesn’t provide all the capabilities needed to run complex data services in production environments. These include automated capacity management capabilities, data and application disaster recovery, application-aware high availability, migrations, and backup and restore.
This is where Portworx comes in. Portworx is the most complete Kubernetes data services platform. GigaOm called Portworx “the gold standard for cloud-native Kubernetes storage for the enterprise.” With Portworx, you can run data services like Kafka in production at scale with all of the enterprise capabilities mentioned above.
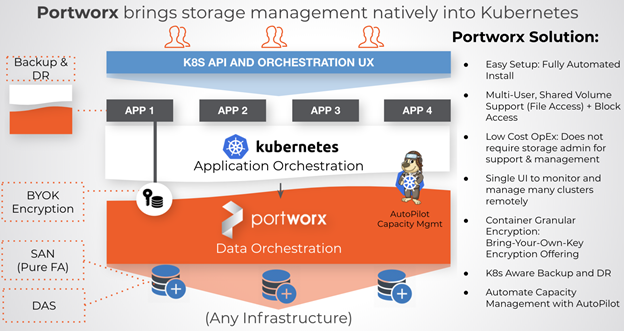
Figure 1: An overview of the Portworx data management platform for Kubernetes.
The operational challenges architects could encounter include monitoring and expanding disk space or migrating actual data from production to test. Other challenges may include figuring out how to recover quickly from failure with automated broker recovery or how to provide tenant-based container-granular encryption for Kafka brokers.
Before we dive into these topics, let’s review how Kafka uses Portworx on Kubernetes.
How Does a Kafka Deployment on Kubernetes Use Portworx?
We’ll focus on some of the key benefits of Portworx and Kafka (so we won’t cover the installation of Kubernetes or Portworx in this post). As a refresher, you can easily install Portworx on Kubernetes using the Portworx spec generator. You can use various backing stores, from directly attached SSD storage to on-prem SANs such as Pure FlashArray™ to cloud-based block storage such as Amazon EBS or Azure Disk. Portworx can provide the same abstraction and benefits for your Kafka on Kubernetes architecture regardless of the cloud or infrastructure.

Figure 2: The overall technology stack for running Kafka on Kubernetes with Portworx.
When you deploy Portworx to your Kubernetes environments, it can provide specialized data management capabilities, such as high availability, placement strategies, encryption, migrations, fast-failover, and more. First, let’s explore the storage classes that work best for Kafka and strategies around configuring Kafka and Portworx replication.
Kubernetes StorageClass Design With Kafka and Portworx
For Kafka to consume Portworx volumes, we must start with a StorageClass. A StorageClass allows Kubernetes operators to define the type of storage offerings available within a Kubernetes cluster. For Portworx and Kafka, it may look something like this:
Note: All examples are available in this GitHub repository to try on your own.
|
1 2 3 4 5 6 7 8 9 10 |
kind: StorageClass apiVersion: storage.k8s.io/v1beta1 metadata: name: px-storageclass-kafka provisioner: kubernetes.io/portworx-volume allowVolumeExpansion: true parameters: repl: "2" priority_io: "high" io_profile: "db_remote" |
Portworx offers a variety of parameters, including snapshot scheduling, labels, replication, snapshot types, and more. We’ll focus on the principle parameters to use for Kafka deployments. Let’s look at the above parameters one by one.
- repl: This setting provides the numbers of full replicas of broker data that Portworx will distribute across the cluster and allows values between 1 and 3. A replica setting of 3 for a Portworx broker PVC means there will be three copies of your broker data across failure domains in the Portworx cluster. The Portworx cluster can sustain up to two storage node failures that hold the replica. With a replica setting of 1, node failure of the replica-owning node can cause downtime. In the next section, we’ll discuss the design and how many replicas for Kafka are best for the use case.
- priority_io: This setting instructs Portworx to place the replicas for your broker on the fastest backend disks it has available within its storage pools. Ultimately, when designing Kafka on Portworx, you should provide the Kafka-recommended type of fast backing storage per node to Portworx. Portworx will then create a virtual pool from this and provide Kafka brokers with a virtual block device from this “high” priority storage pool.
- io_profile: Portworx offers various IO profiles to allow operators to tailor the IO interaction on the Portworx storage pools. IO profiles help with the overall performance of the volumes used by applications. For Kafka, db_remote should be used to implement write-back flush coalescing for optimal performance of Kafka brokers.
Configure Kafka Replication on Portworx
Now that we have a StorageClass that defines Portworx replication, you may be asking yourself, Kafka and Portworx both provide replication, so how do I best configure Kafka on Portworx?
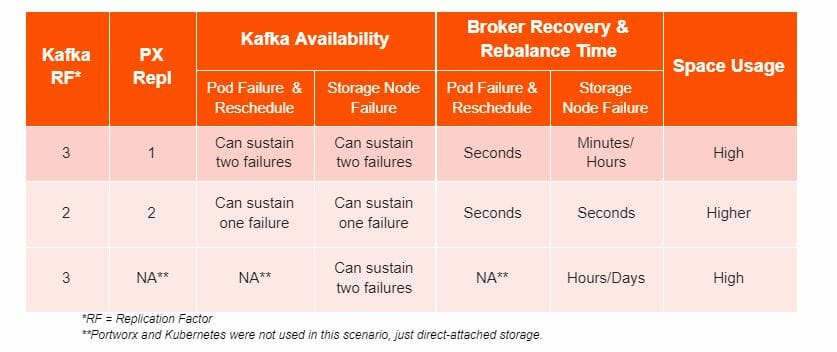
*RF = Replication Factor **Portworx and Kubernetes were not used in this scenario, just direct-attached storage. Figure 3: The trade-off of availability and recovery time when configuring Kafka and Portworx replication factors.
The outcomes of testing all replication factor combinations show us that the main decisions when architecting Kafka on Kubernetes are around availability, recovery times, and disk space usage. Our testing showed that two options were ideal for running Kafka, depending on your business requirements around tolerance to failures.
When Portworx creates more than one volume replica, it replicates the volume at the storage layer. As a result, it can very quickly recover from pod-, node-, network-, and disk-level failures and quickly bring up the failed broker on another Kubernetes node for maximum uptime. Portworx also keeps data within the virtual volume. As a result, the broker doesn’t need Kafka admins to issue rebuilds of data over the network after hard failures. These are significant availability, resilience, and operational efficiency gains when running Kafka.
Broker downtime can result in an under-replicated Kafka cluster. For businesses that want maximum performance and have more tolerance for broker downtime, you can allow Portworx to keep a single replica while Kafka uses three. Then, during pod failure—or when PX nodes don’t hold the only replica—Portworx can still reattach its virtual volumes from the nodes with failed brokers to another node.
However, if the Portworx node that fails owns the replica, the broker will be unavailable until recovery occurs. Keep in mind that when you have storage directly on the hosts, it’s still operationally better to use Portworx. That’s because Portworx can move and reattach its virtual volumes to any other Portworx node. This is possible as long as it has an available replica—even if the failed node running the broker is unavailable. However, you won’t be able to do this with directly attached storage.
Kafka Broker Failures and Sync Times with Portworx
The benefits of Portworx replication include improved operations and recovery times when it comes to recovering from hard broker failures. When a broker fails on a host due to hardware, network, disk, or node failure, the remaining healthy brokers will take over topic leadership. You’d need to recover the failed Kafka broker.
Suppose the broker is using direct-attached storage and the node fails permanently. In that case, you have to set up a new broker and manually reassign the data at the partition level using the kafka-reassign-partitions utility. Doing so requires manual effort from Kafka admins and special monitoring. It can be fairly slow with large data sets, and the cluster will remain under-replicated until this occurs. Portworx can significantly improve these operations because the data can be made available to a broker recovering on other worker nodes.
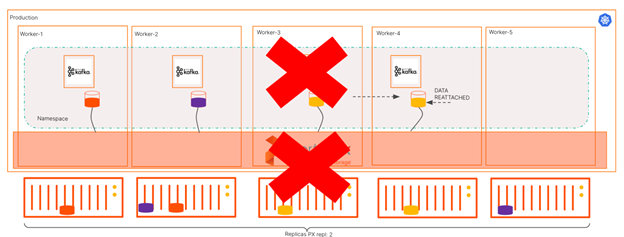
Figure 4: Kafka uses Portworx and Kubernetes to easily recover on a healthy node with a Portworx replica when using repl=2 settings for Portworx.
With Portworx providing storage-level replication, the broker is scheduled onto a healthy node and reattached to the original Portworx virtual volume it was using. This allows the broker to come online with the original data and participate in the cluster right away. The broker then syncs any new messages after the failure occurred instead of rebuilding all data from other in-sync partitions that weren’t affected by the failure.
Portworx provides an 83% reduction in Kafka broker rebuild times.
Portworx provided rebuild times around two to three minutes with hundreds of gigabytes of data in our testing. It took nearly 18 minutes to recover Kafka using directly attached NVMe devices. That’s an 83% decrease for rebuild times. These operations will also occur without manual administration, which leads to an overall more durable Kafka cluster.
Kubernetes-Aware Data Management for Kafka
Portworx Autopilot offers Kubernetes-aware data management and capacity automation. In addition, using PX-Autopilot with Apache Kafka means fewer headaches and touchpoints for administrators. This operational efficiency is vital to DevOps teams today.
Autopilot is a rule-based engine that responds to changes in the Kubernetes environment and acts on them based on a set of rules. For Kafka, we can set up Autopilot to automatically grow the underlying storage for brokers if ingest data exceeds original expectations. Autopilot also enables Kubernetes admins to rebalance or expand entire backend storage pools on certain platforms, allowing them to rightsize capacity, consumption, and spend, leading to a better overall TCO.
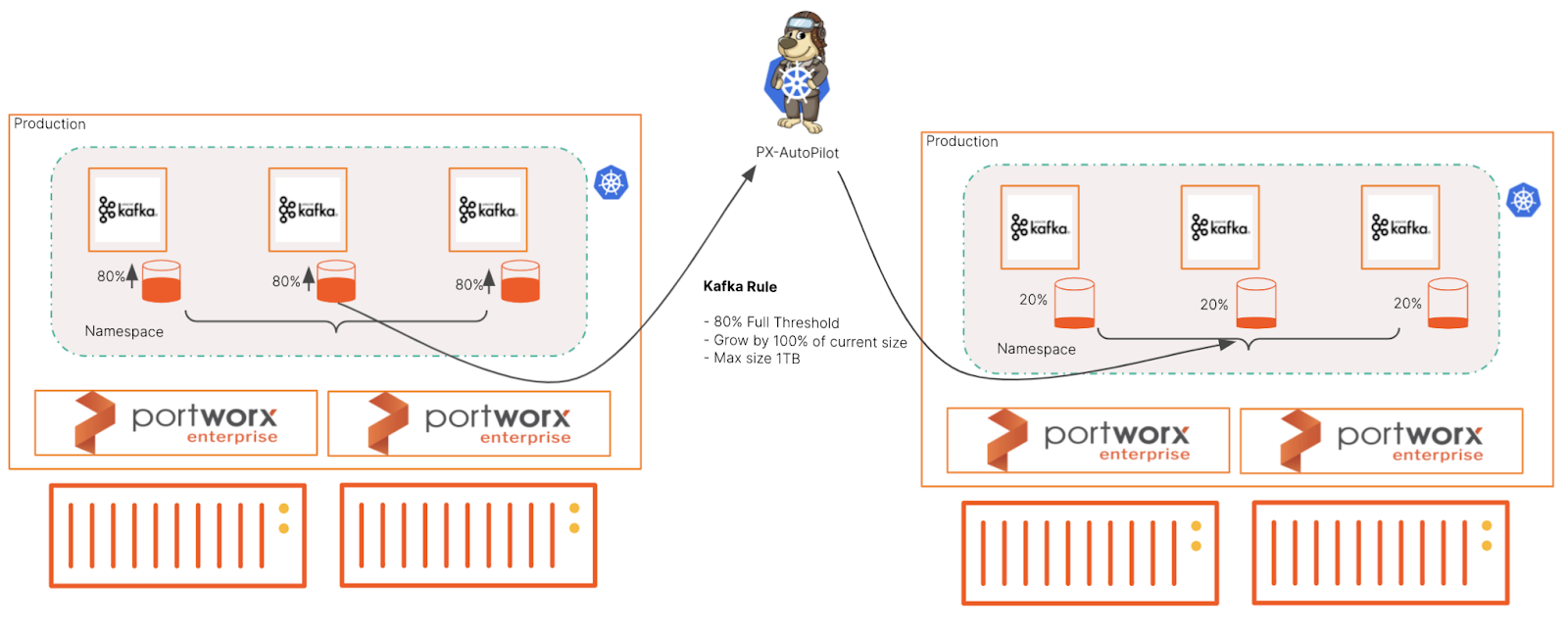
Figure 5: Autopilot can detect when Kafka broker PVCs are almost full and automatically perform a resize action based on the usage metrics from the PVCs.
By architecting Kafka with Autopilot, we can set up rules to expand the broker’s available disk space if the ingest reaches a particular percentage. For example, it could be 80% of the available broker disk capacity. Autopilot can then automatically expand the volume to the specified amount and monitor the volume for further thresholds. In addition, autopilot allows admins to set a maximum size to which a volume can grow, which helps with overall capacity planning and allowances.
Test Real Production Data in Kafka With PX-Migrate
Portworx creates a globally available virtual storage pool for Kubernetes applications. As a result, Portworx enables both applications and their data to be portable across any infrastructure or cloud. This means that you can create an application-aware copy of your Kafka services in real time and move them to another environment. PX-Migrate can enable these capabilities for Kubernetes applications like Kafka.
How might you use this?
PX-Migrate is the essential technology behind PX-DR. If you’re looking for a site-to-site, synchronous, or asynchronous disaster recovery scenario, you’ll want to use this. However, we’re not going to cover DR in this post. Instead, we’ll look at using PX-Migrate to provide single migration copies of Kafka and its data from production to test.
For example, you may want to move the data to an environment that can scrub PII out of it. And then move it to a test Kubernetes cluster to enable developers to test this real data. PX-Migrate gives you the exact copy of what was running in production, from application configuration (spec files and metadata) to the data in the brokers.
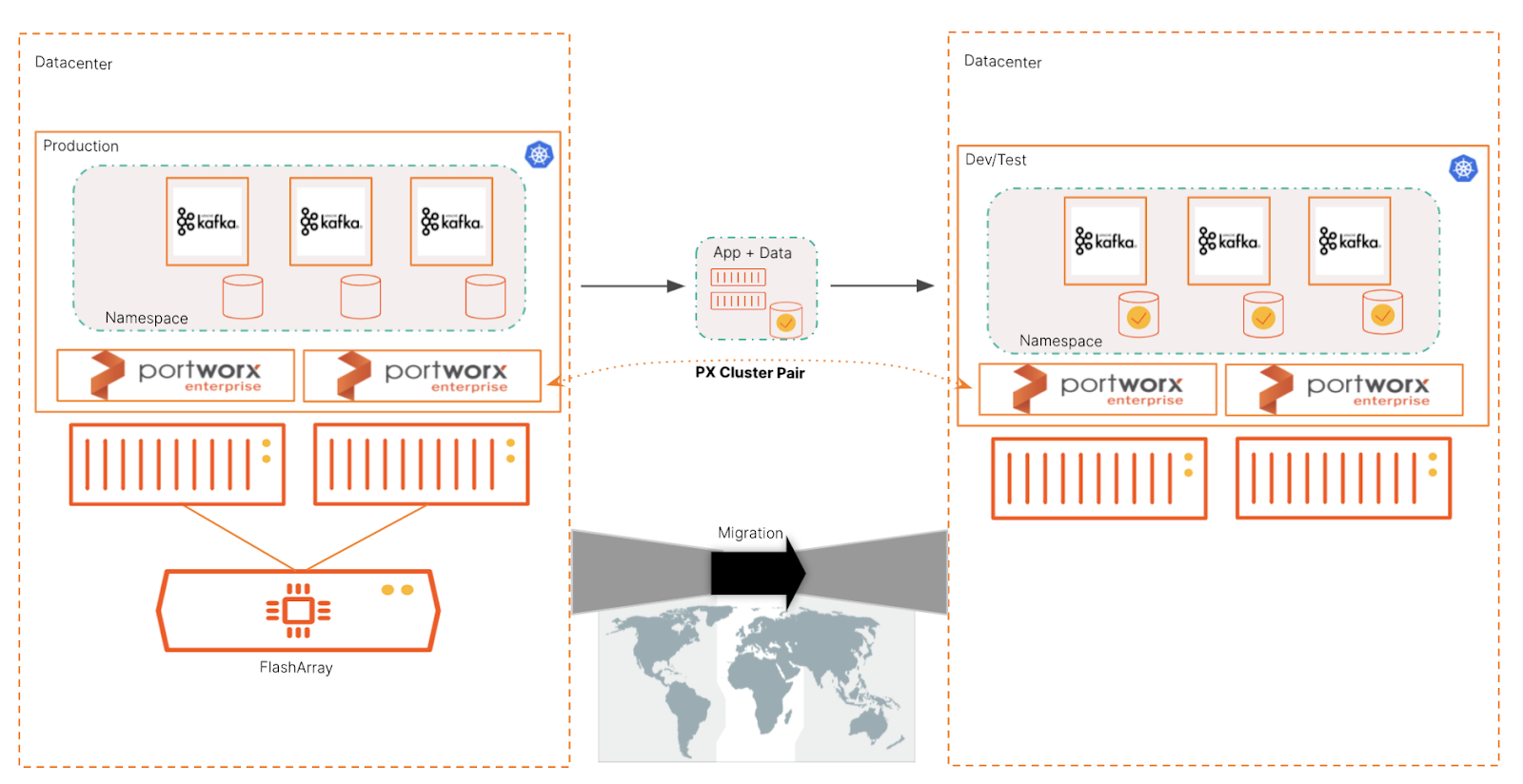
Figure 6: This illustration shows how PX-Migrate can pair two independent clusters and allow Kafka metadata and volume data to be moved as a single unit.
PX-Migrate enables migrations that can provide application-aware rules for consistency. It allows you to move the Kafka-application metadata (deployment and StatefulSet) along with its data to another Kubernetes environment.
Conclusion
Running data services on Kubernetes is becoming the standard in enterprise environments now that Kubernetes is the clear winner in container orchestration. In addition, the combination of Portworx and Kubernetes enables clear architectural benefits that are critical to today’s DevOps teams. In the next part of this series, we’ll dive into security, deduplication of Kafka with Portworx on FlashArray, and overall performance.
Learn more about Portworx and sign up for a free 30-day trial. You can also watch a Portworx Lightboard session recapping the key advantages of running Apache Kafka with Portworx.
![]()



