Pure Storage announces the launch of Cloud Block Store for Amazon Web Services (AWS), which offers a way for Pure Storage platforms to be extended into the cloud. I would like to demonstrate how easily we can migrate your on-premises SAP HANA single node instance to AWS, using Pure Storage FlashArray™ data services and Cloud Block Store for AWS.
The complete demo can be seen in this video.
SAP HANA, once migrated to AWS, can be used as a Dev/Test system or for running Analytics. This is due to the unique nature of SAP HANA’s column tables, which are fine-tuned for OLTP workloads as well as for OLAP or Analytics workloads.
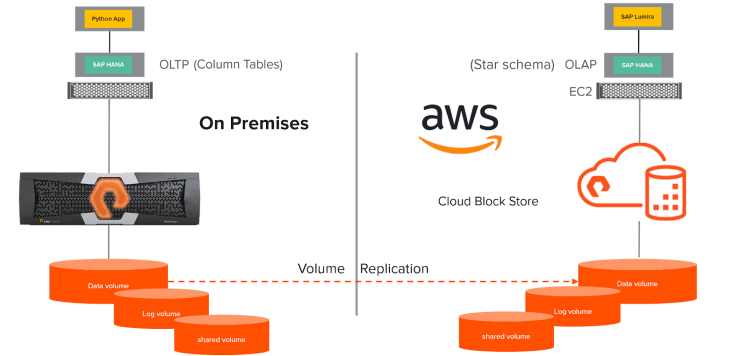
The demo involves using FlashArray data services (asynchronous replication) from an on-premises SAP HANA database running on a Pure Storage FlashArray//M20 host in Equinix, to Cloud Block Store. Once the database volume is replicated, we can bring up an SAP HANA instance running on an Amazon EC2 instance.
Below is the architecture diagram of the demo.
Here we have an SAP HANA system running on-premises which we are planning to migrate to AWS. One of the column tables in the SAP HANA on-prem system is updated by a Python application connected using a python database API. This python application is inserting new records to the SAP HANA.
The following steps are performed on-premises:
- The Cloud Block Store on AWS is connected to the on-premises FlashArray as an asynchronous-replication target.
- We have a protection group for this on-premises SAP HANA’s data volume. This protection group is configured to replicate to Cloud Block Store.
- Now we take an application-consistent snapshot of the on-premises SAP HANA system. We put SAP HANA in create snapshot mode (Back up mode) and then we freeze the data volume’s file system to an application-consistent snapshot. Then we unfreeze the file system and close the SAP HANA backup mode.
- This asynchronously replicates the latest data to the Cloud Block Store. Let us now begin the recovery process for the SAP HANA instance on AWS.
The following steps are performed on AWS:
- Now use the latest snapshot which was replicated from the on-premises FlashArray. We apply this latest snapshot on to the SAP HANA data volume.
- After we apply the snapshot, we start the recovery process for the SAP HANA instance on EC2.
- Once the recovery is completed, we can use the SAP HANA system as a Dev/Test instance or build star schemas on these column stores for Analytics.
- Here in the demo, we used the SAP Lumira dashboard to connect with the SAP HANA instance on AWS to perform analytics on the latest data from the on-premises SAP HANA system.



