

SAP HANA system copy can be a time-consuming process for SAP Basis system administrators. Admins spend a considerable amount of time and effort preparing the software environment and going through complicated procedures to ensure that the backup and recovery process is carried out with minimum disruption to the business and in accordance with best practices.
This white paper (link at end of the blog) describes the speed and efficiency of performing a homogeneous system copy of an SAP® HANA environment using Pure Storage FlashArray:
- SAP HANA SPS 11 (Single tenant)
- SUSE® Linux Enterprise 12 Service Pack 1
- Pure Storage snapshots and copy methods to move source system data to the target system
Pure Storage snapshots are instantaneous and do not depend on the capacity of the volume. Therefore, the entire process of an SAP HANA system copy refresh is accelerated. This saves SAP Basis consultants a great deal of time – so they can immediately start working on pre-refresh and post-refresh activities for the SAP application. Another great advantage that system copy offers is that the SAP HANA source system does not go offline.
At a high level, these are the steps for performing a HANA system copy:
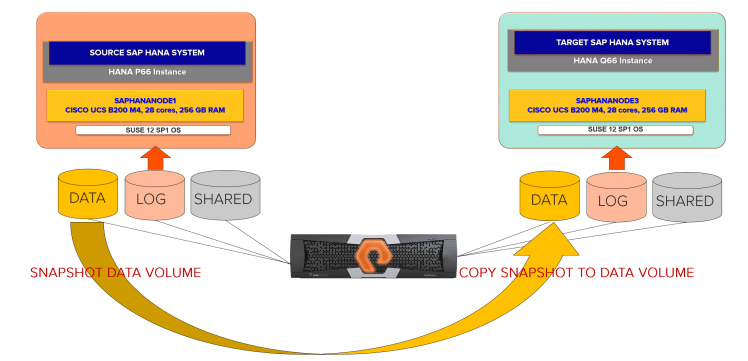
- Prepare the source HANA database: This creates an internal snapshot of the source SAP HANA database, which can take a few minutes as it depends on the change rate between SAP HANA savepoints.
- Take the storage snapshots of the SAP HANA data area. Apply this snapshot to the target SAP HANA data area.
- Confirm the snapshot in the source system, which clears the internal states of the SAP HANA source system and enters an external backup ID in the backup catalog.
- Recover the target HANA system by initializing the logs.
This white paper on HANA system copy covers in detail for a Scale-up SAP HANA system, where you have an environment like below with source and target SAP HANA scale up systems.
Check 0ut FlashBlade
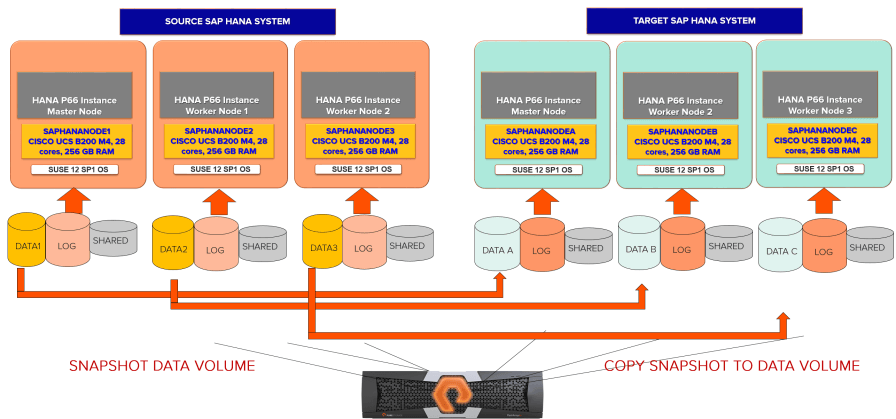
And also, this white paper on SAP HANA system copy covers in detail for a Scale-out SAP HANA system, where you have an environment like below with source and target SAP HANA scale-out systems. The source and target should have the same number of nodes otherwise snapshots cannot be used.
Here are some of the most important points regarding the SAP HANA storage snapshots methodology.
Let’s start with the advantages of using storage snapshots
- Storage snapshots are useful as they provide very fast data backups and perform system copies for huge amounts of data with a negligible impact on the network, overall I/O performance, and the SAP HANA database itself.
- Also, storage snapshots are most suitable for fast database recovery (recovery-time-objective; RTO). If your RTO requirement is very low storage snapshots are the best way to recover an SAP HANA database.
Some of the disadvantages of storage snapshots in the HANA database
- In contrast to file-based or backint-based data backups, no database internal integrity check (checksum calculation) on page resp. block level is performed while a storage snapshot is created, meaning storage snapshots could contain damaged data pages.
- Compared to file-based or backint-based data backups, a storage snapshot will consider the entire data area of all HANA database services and not only the payload of each service specific data volume.
Storage snapshots are not supported for HANA dynamic tiering at present, nor are multi-tenant database containers.
HANA system copies are done to set up a test system, demo system, or training system.
Here is the link to the white paper:
https://www.purestorage.com/resources.htmltype-a/scale-up-out-sap-hana-using-snapshots.html
I have also automated the entire system copy process using a shell script. This script needs to be placed on the target system which talks to the HANA source system and Pure Storage FlashArray//m as explained below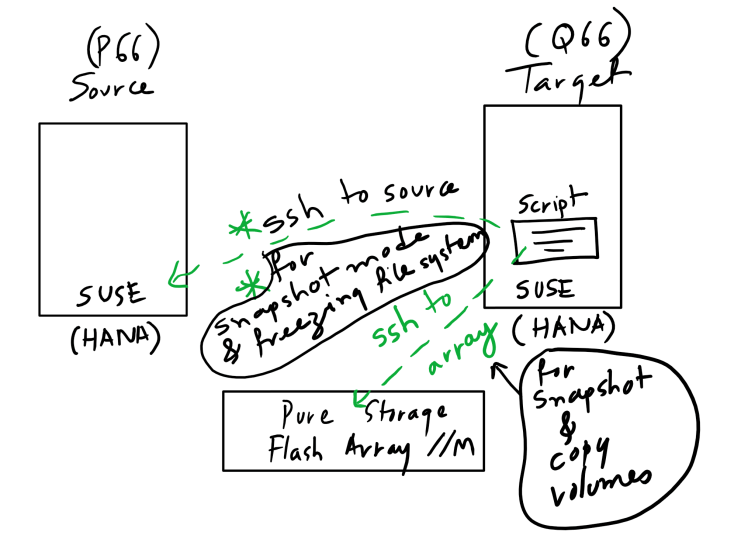
Here is the link to the master script:
https://github.com/krishnasatyavarapu/SAP_HANA/blob/master/saphanasnapcopy.sh
and the helper script:
https://github.com/krishnasatyavarapu/SAP_HANA/blob/master/snapcopydatavolume.sh



