


What’s the problem with backups? Throughput.
Microsoft SQL Server is one of the most widely used relational database management systems by volume of installations. Its global footprint across all customers is likely in the range of exabytes (thousands of petabytes). Or perhaps even zettabytes (thousands to millions of exabytes). That amount of data needs to be protected, and when it needs to be restored it needs to be done quickly.
With this large, ever-increasing global footprint of data (data gravity), database administrators continually face the challenge of accommodating backups of these databases during a set timeframe. Computationally, this becomes purely a storage throughput (bandwidth) problem.
For a backup, you need throughput on your source storage device to read your database files into memory buffers that will then be written to backup files on the target device. Conversely, for a restore operation, you need throughput on your source backup device to read your backup files. Then you need throughput on your primary storage device that holds your database files to write them at acceptable speeds. In short, it’s all about the throughput.
What is considered an acceptable backup/restore speed these days? You likely have a phone in your pocket that can handle at least a gigabyte per second of throughput. So why should you accept anything less for something as important as production database backups?
Test Your SQL Server Backup Speed
If you don’t know what kind of throughput you’re achieving while backing up your SQL Server databases, you can run a simple query on any instance that will provide throughput stats for your backups. This query is similar to one on SQLBackupRestore.com. (The site is a great resource if you want a deep dive on how SQL Server backups work.)
|
1 2 3 4 5 6 7 |
SELECT database_name, backup_start_date, CAST(CAST((backup_size / (DATEDIFF(ss, backup_start_date, backup_finish_date))) / (1024 * 1024) AS numeric(12, 3)) AS varchar(16)) + ' MB/sec' speed FROM msdb..backupset ORDER BY database_name, backup_start_date |
If your backup speed is measured in less than a 1,000 megabytes per second, your backups are slow by today’s standards.
Make Your SQL Server Backups Screaming Fast
If you need better throughput for your backups and restores so they complete faster, look no further than Pure Storage® FlashBlade® unified fast file and object (UFFO) storage. FlashBlade is a highly parallel, massive throughput device. It can handle entire farms of SQL Server instances backing up to it at the same time. And it breaks through a fundamental metric of backup performance. Data backed up with FlashBlade is measured in terabytes per minute, not terabytes per hour.
So how does FlashBlade achieve that kind of throughput? With threads. Tons of threads.
In the simplest scenario, a SQL Server database sitting on a single logical disk (as seen by Windows) on FlashArray™ backing up against a single .BAK file on FlashBlade will generate throughput, over a GB/sec.
You can only increase parallelism for backup/restore (more threads) on the SQL Server side by placing your database on multiple logical disks on Windows. It doesn’t matter if these are virtual disks sitting within the same VMFS datastore on VMware vSphere or the same CSV on Microsoft Hyper-V. All that matters is that the Windows volumes where your database files sit are different. A backup operation will have one reader thread per logical disk. A restore operation will have one writer thread per logical disk.
When performing a backup operation, SQL Server will generate one writer thread per .BAK file in the backup set. If your target backup device benefits from parallelism and multiple threads, then striping your backup across multiple .BAK files will yield faster performance.
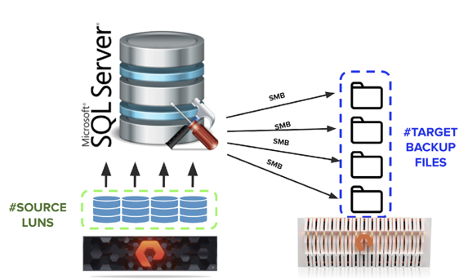
Figure 1: SQL Server Backup/Restore Operations and Read/Write Threads
On FlashBlade, you can turn up the volume all the way to 11 by creating multiple SMB shares and enjoy even more parallelism from the system.
Follow the recipe above for your backups across multiple instances and watch how you can achieve an aggregate throughput of over a terabyte per minute.
There are tons of other knobs to consider for backup performance. Fine-tuning them can help speed up your backups even more. Two important ones to consider are:
- MAXTRANSFERSIZE: Specifies the IO request size to be used for your database and backup files.
- BUFFERCOUNT: Establishes how many memory buffers will be available to the backup or restore operation. These buffers will be equal in size to MAXTRANSFERSIZE, which defaults at 1MB.
Will Restores Also Be as Fast?
You bet. FlashBlade isn’t like other backup appliances that ingest data quickly and then slowly drip bytes back to your database for a restore. What’s the point of fast backups if you can’t restore equally as fast?
Just as we adjust our expectations with backups we need to with restores. We should frame the expectation of performance for restores in the following way: FlashBlade will restore your databases so fast that you’ll be reaching the ceiling of your primary database storage write ingest limit.
In other words, you’ll be bound by how fast your storage device can write data to it. Recovering from a data event should never be slowed by the speed of the storage. It is imperative that business continuity happens as quickly as possible. What use are fast backups if restores are slow.



