

SQL servers and snapshots. How do these relate to Pure. This post came to be from a meeting with a customer here in Seattle, who uses transactional replication in their environment heavily. One thing I remember from the meeting is hearing how subscribers would go out of sync (causing problems to downstream systems) and then noticing the reaction to this question: “How much would your business benefit from the ability to initialize replication subscribers in seconds?”
You might relate to this. Initializing subscribers can be a tedious, painful process. Especially when it comes to large databases. Snapshots? Transfer time? Time to catch up? Not a great experience.
One of the few techniques available for initializing subscribers on VLDBs is to initialize from backup. There are tricks that you can use so you don’t have to restore the whole database at the subscriber, like using partial database restores with filegroups. This is obviously not an option for those databases with single (default) filegroups – which most DBAs out there live with.
Among the things that make Pure Storage a great solution for databases is the ability to easily create copies of your data without incurring tons of additional space consumption. In this post, I will demonstrate how it is possible to initialize a transactional replication subscriber in seconds. This use case extends to the other kinds of replication that SQL Server offers.
Before I go into details, I must remind you that while a full copy of a volume might seem like a waste, you need to remember that you’re actually not paying any space penalties in using a full copy of your data in our arrays: it’s only when you start modifying a particular copy that we actually need to start tracking additional space consumption.
We start with a test database, called DemoDB, with a set of tables and a new table that we want to replicate to a subscriber, called dbo.GuineaPig.
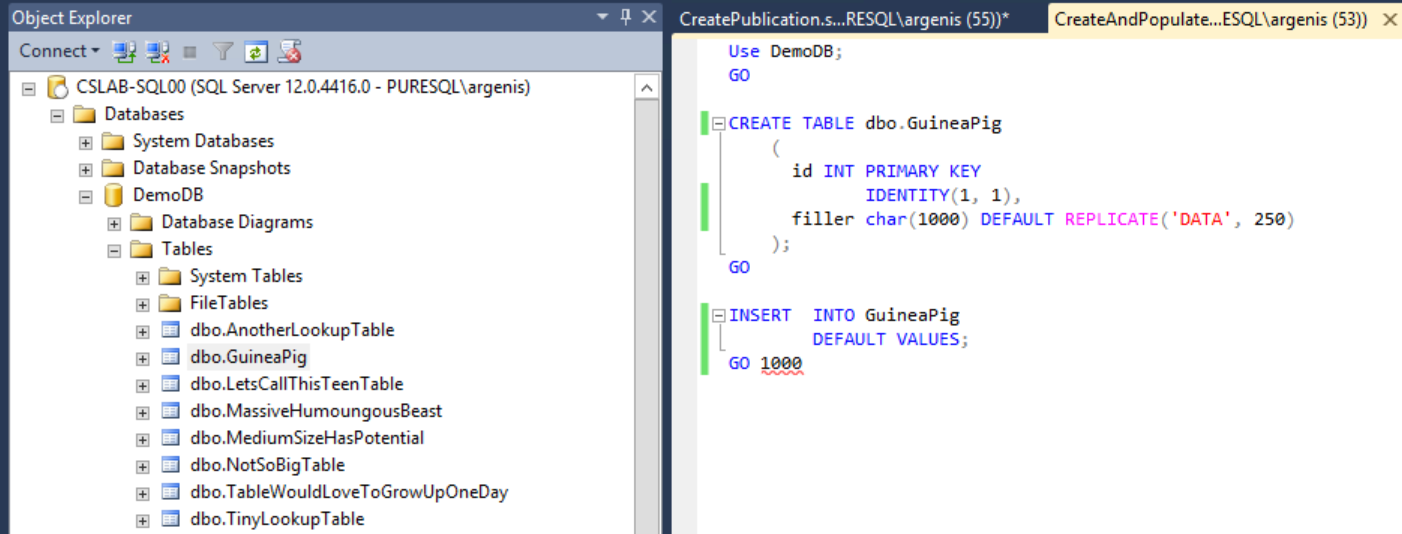
I created this table, and inserted 1000 rows. Then I said “…that’s boring.” and I changed the GO 1000 statement to GO 10000000. While those 10 million rows were being inserted into the table I went ahead and created a publication for it:
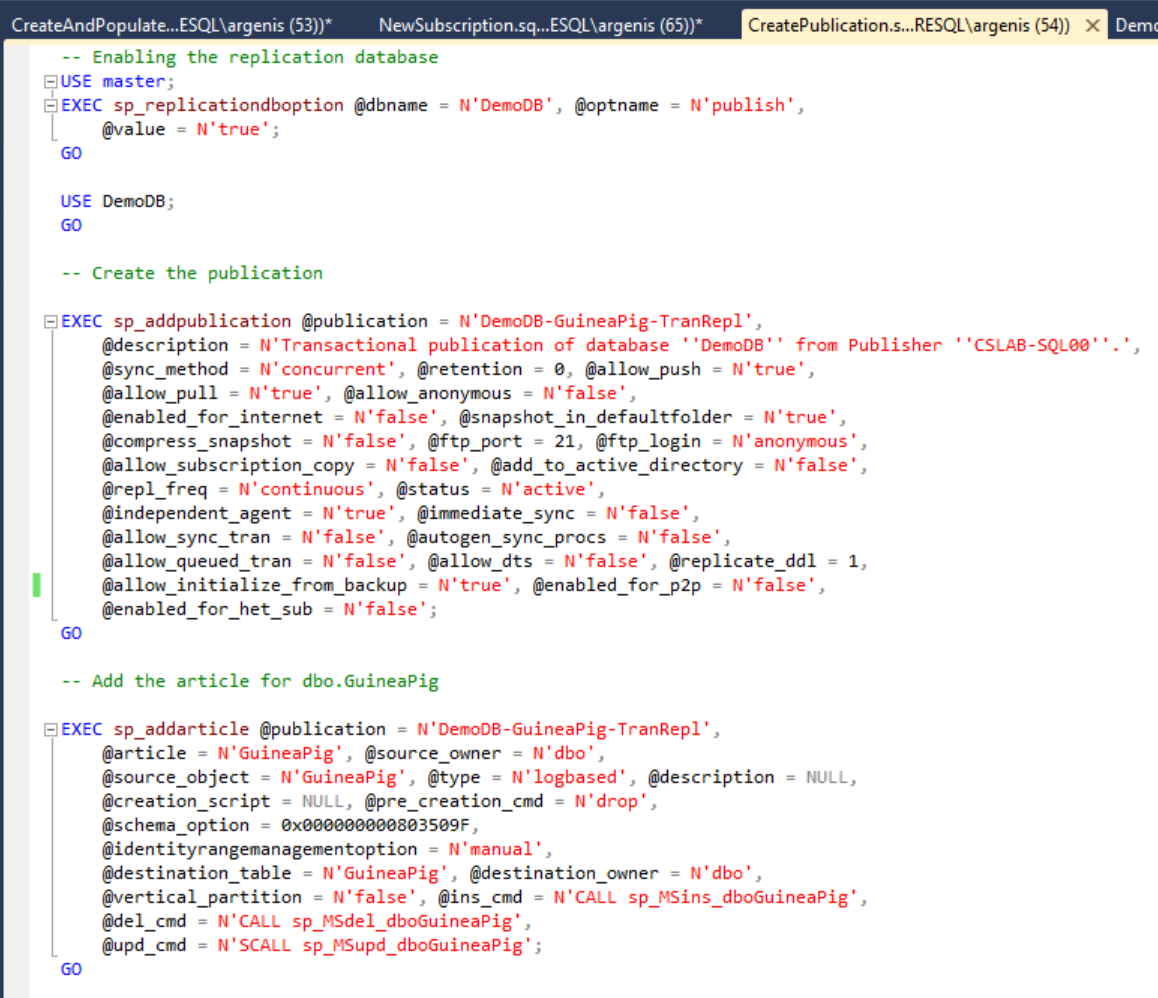
One thing that I want you to note from above is the fact that in the call to sp_addpublication I specified @allow_initialize_from_backup = N’true’. This is key here – I am not intending to initialize from backup, but I want replication to track the Log Sequence Number (LSN) for this publication so I can later perform an initialization of a subscriber from LSN – an extremely underrated feature of replication that goes hand in hand with our snapshots and clones capabilities in the FlashArray.
I then proceeded to query dbo.syspublications on the database:

Now I know where the publisher stands in terms of tracking. I’ll use this later as a guide.
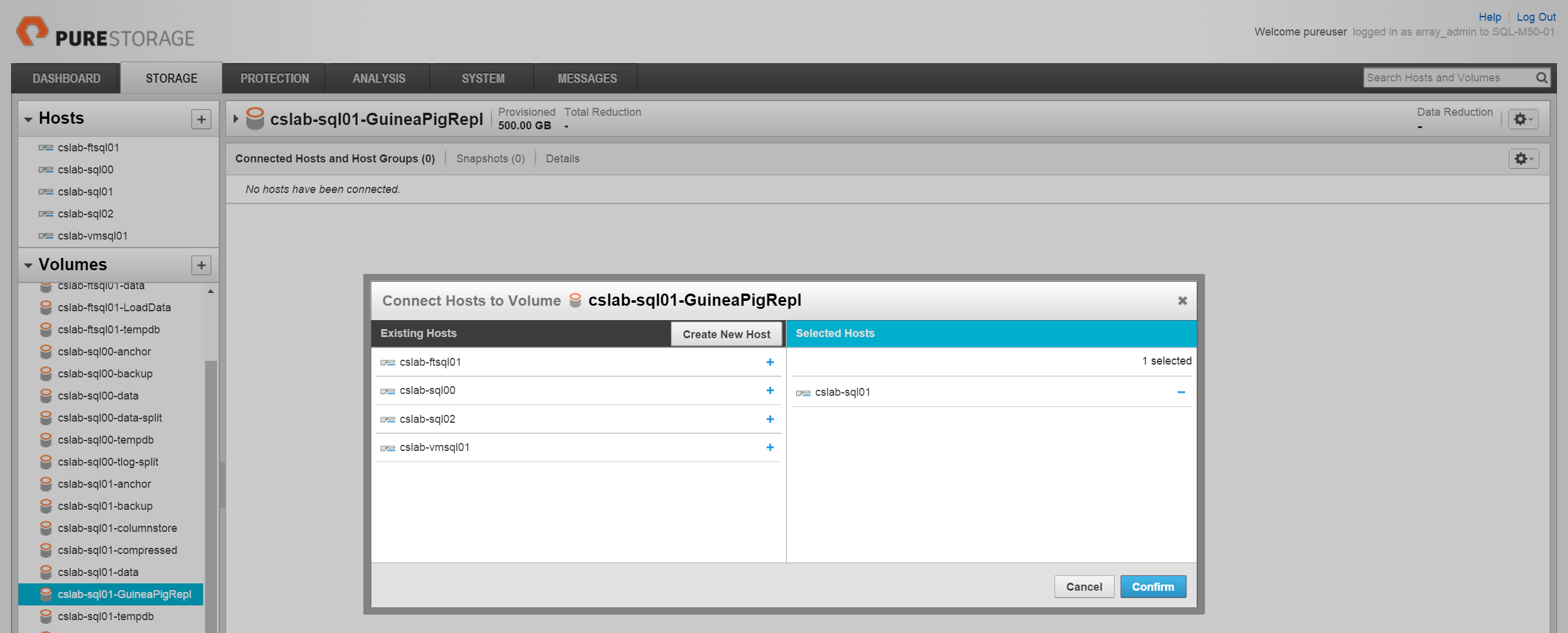
Time to copy the data volume where the publisher database lives into a new volume. This will be our subscriber database’s data volume now.

Then present it to the host – a very simple task in our GUI:
And now that I have a volume presented, I rescan disks in Disk Management and assign a drive letter:
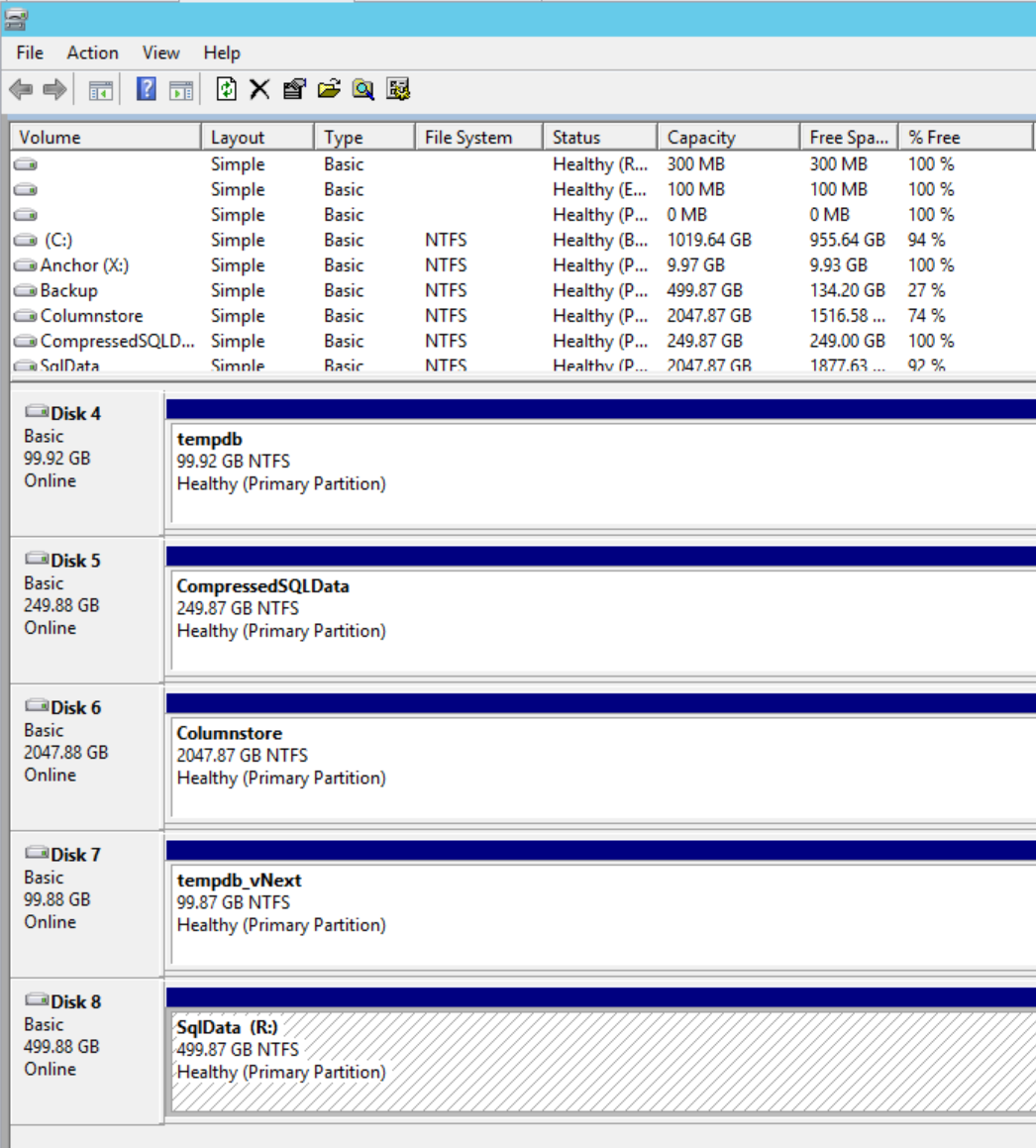
Then browse to the main data file for the database I care about. Note that everything else in this volume is a copy of the original server, and there is no daisy chaining of any sort taking place – so you’re free to delete the extra files/folders in a copied volume you don’t need – it won’t impact a single thing.
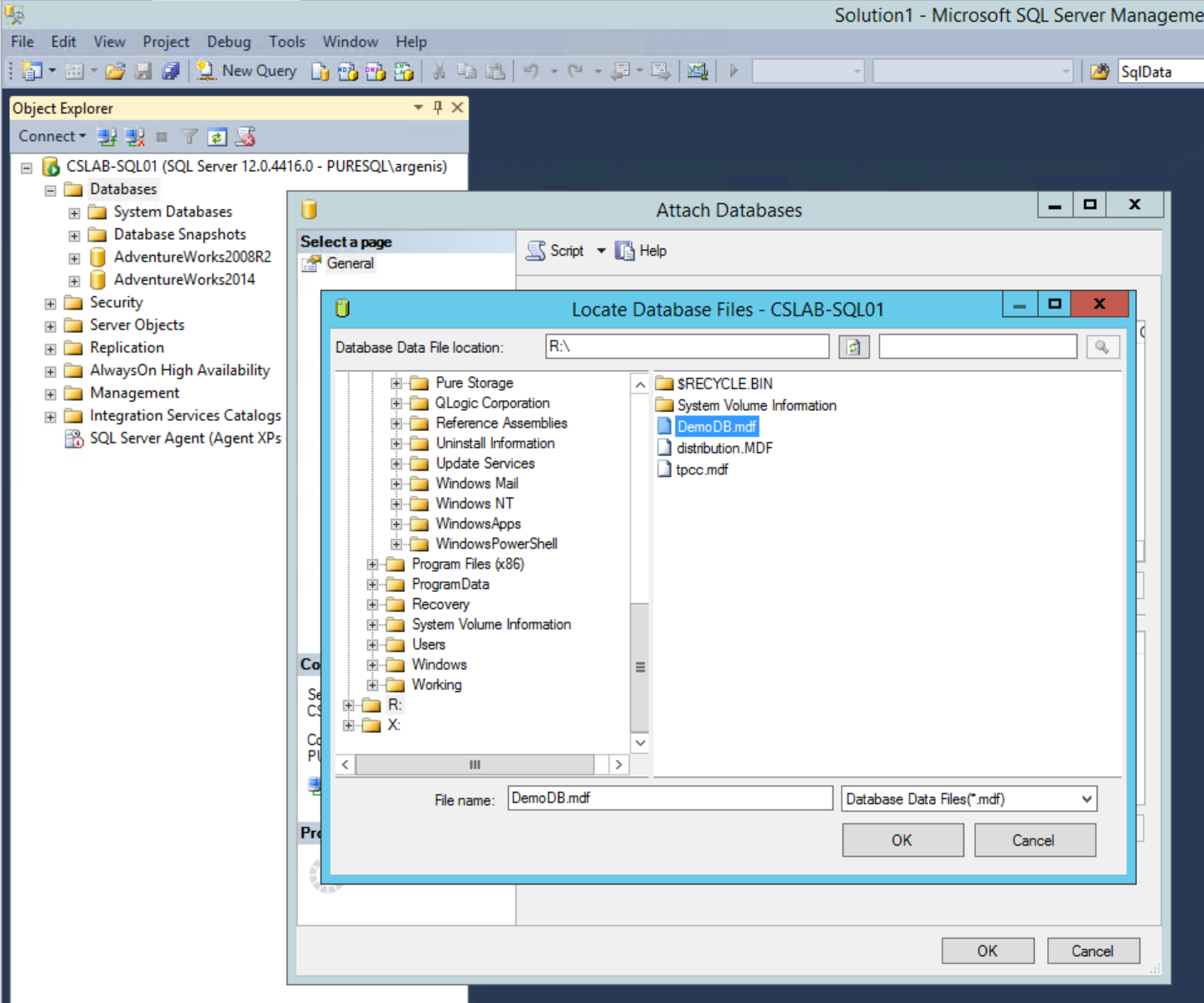
Now that we pick the main data file, everything else populates in the Attach Databases dialog. Double check everything is okay.

All along, INSERTs have been taking place in the publisher database.
Here is where we talk more about SQL.
Now here comes the (only) tricky part. We need to find out what LSN we’re going to tell the publisher we’re going to be syncing from. No, that LSN that I got last time from dbo.syspublications is not helpful, because in the time that I copy and then paste the LSN number into the sp_addsubscription statement and run it, thousands of rows have been inserted at the publisher – hence I need to find out what’s truly a good LSN to start from. dbo.syspublications only gives me an idea – it should be a value higher than it.
I’m going to use this as a query to find out a good LSN – it looks for the commit record on the last transaction that touches the allocation unit belonging to the dbo.GuineaPig table (make sure you run this on the subscriber database!):
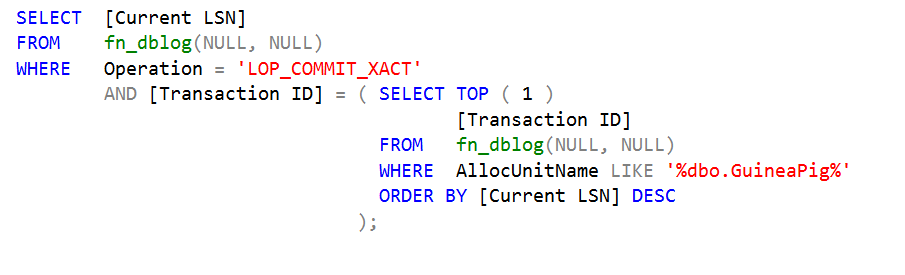
And that gets me a hexadecimal number (in this case, 0x000003e500167e9003)that I can handily pass to sp_addsubscription on the publisher instance:
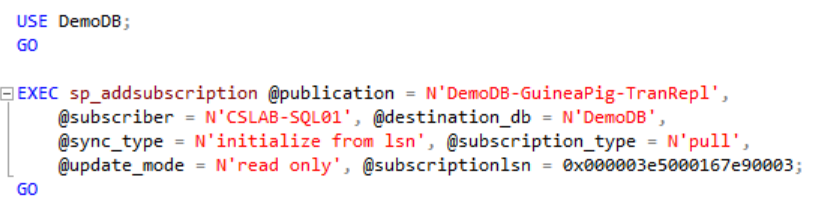
Now all that’s left is create an actual subscription with its accompanying jobs on the subscriber instance, with the following (I chose pull in this case):

And voilà! My jobs kicked off just fine, and my subscription became up to date a few seconds after this. Did you think about how this stuff can be fully automated with our Powershell SDK? Certainly. End to end.
Conclusion on SQL
Now you might be thinking that there’s a lot of remnants from the publisher database in the subscriber copy. You would be totally right about that. You are free to go ahead and drop those objects you don’t want.
This is one of the many, many use cases for snapshots and clones. Pairing this with our replication features, you could initialize from a replicated snapshot on a different datacenter, for example. Very, very handy!
Thanks for reading,
-A



