


Whether it’s banks predicting unusual risk in the stock market or web companies personalizing shopping experience for each user, It’s becoming universally clear that there is enormous value in data processing and analysis for modern businesses. This is where data scientists step into the spotlight.
Data scientists are today’s superheroes. While the era of software 1.0 was powered by software developers and programmers, software 2.0 is driven by data scientists – building the next AI-powered solution with ConvNets or regression trees. They build predictive models that find hidden meaning out of the data through parameter optimization, model exploration, training, evaluation, and visualization. Hence the last thing we want data scientists to do is anything but build innovative machine learning (ML) algorithms.
Yet data scientists spend about 80% of their work on data preparation and management of the pipeline, rather than focusing on algorithms. It’s a slow, serial and manual process that forces data scientists to spend most of their time sitting idle and waiting.
The Wait Is Now Over
Today at GTC Europe, NVIDIA announced RAPIDS open-source software for accelerating data science and analytics on GPUs. RAPIDS brings the power of the massively parallel GPU to where the data scientists spend 80% of their time, empowering them to be more productive by accelerating the entire AI pipeline from data preparation to machine learning model training with no new tools to learn. This, in turn, increases the model accuracy by allowing them to iterate on models faster and deploying them more frequently.
Here are some highlights of RAPIDS open-source software:
- Increase machine learning model accuracy by iterating on models faster and deploying them more frequently
- Easily scale from workstation to multi-GPU servers to multi-node cluster.
- Built on Apache Arrow, it is customizable, extensible and interoperable with the data science toolchain.
RAPIDS represents a huge boost for the data science community, and we are pleased to support NVIDIA and their work to deliver ever-increasing value to our joint customers.
FlashBlade™: Data Hub for the AI Pipeline
The key to fastest-time-to-insight is to keep your GPUs busy. One of our customers, ElementAI underutilized their GPUs often running at 20% utilization with a legacy storage solution. By leveraging FlashBlade as their data hub, the GPU usage jumped close to 100% and hence enabled data scientists to train on the models faster.
A modern high-performance scale-out shared storage platform is not only important – it is essential for customers looking to build their AI workflow with RAPIDS. Firstly, shared storage avoids the need to manually copy subsets of the data for each pipeline stage, saving the engineering time as well as improving the GPU usage. Shared storage empowers the data scientists to collaborate by sharing their workflow easily and integrating the models developed to the application seamlessly in a DevOps environment. Secondly, with multiple data scientists exploring datasets and models, it is critical to store data in its native format to provide flexibility for each user to transform, clean, and uniquely use the data. It’s this experience that yields more powerful models. Finally, the importance of high performance shared storage is critical for the entire AI pipeline not just to store the ever-growing datasets.
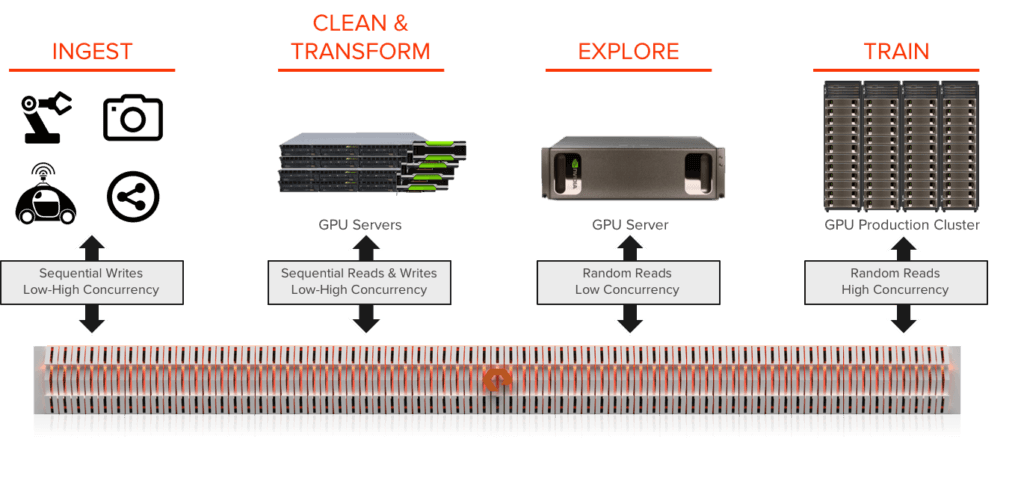
FlashBlade’s data hub architecture delivers an ideal storage platform to power analytics and AI. A data hub takes four qualities of the AI pipeline and integrates them into a single unified platform: high throughput file & object, native scale-out, multi-dimensional performance, and massively parallel architecture. A data hub integrated with RAPIDS enables enterprises to share data rapidly across the data science teams and tremendously increases their productivity and empowers them to collaborate and develop models faster with greater agility.
To learn more, please visit www.RAPIDS.ai or contact us with any questions. We’d love for you to see how FlashBlade and AIRI will enable new possibilities for your organization as you explore AI’s capabilities.



