

The technologies that comprise data analytics pipelines have changed over the past few decades, which has had a massive effect on the infrastructure required to support them. Newer technologies include support for File and Object Store protocols, which enables the use of centralized storage instead of D DAS (Distributed Direct Attached Storage), avoiding the difficulties of scaling, tuning, and maintaining infrastructure.
Traditional Analytics
Relational databases have been around for many decades as the norm across many companies. They have evolved to be easy to create, maintain, and manage with reliable performance directly proportional to the number of queries and amount of data they store. However, relational databases have two main limitations
- They only work for highly normalized data, leaving them unable to ingest and analyze semi-structured and unstructured data.
- They are notoriously difficult to scale out.
The infrastructure to support a relational database model frequently looks something like this:
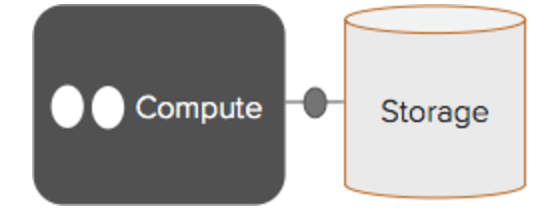
You have a large cluster of compute to run queries on top of your Relational Database, and this compute cluster is attached to a centralized storage platform over the network. As long as your storage can keep up with bandwidth and latency requirements, you can add more compute nodes in order to make your queries run faster (up to a point). Conversely, if you just need more capacity, you can add more storage to your SAN array.
Modern Analytics in DAS
Storage is relatively inexpensive, so enterprises are saving larger and larger amounts of semi-structured “data exhaust” from logs, devices, and dozens of other IoT sources. But it’s not just about storing the data for archival/backup any more – companies want to extract insights from their data to gain competitive advantages. New software apps have been created that can analyze all these data: HDFS, Elastic, Kafka, S3, Spark. With these open source building blocks in place, the challenge for enterprises becomes how best to architect their modern data warehouses to serve their needs, while still meeting strict performance and cost requirements.
The most common deployment of infrastructure to support modern data analytic pipelines is the DDAS model – this is mostly for historical reasons. At the time that modern data analytics technologies were being developed, there wasn’t a storage platform big enough for such large amounts of data nor fast enough to meet the high bandwidth requirements from big data software.

When Hadoop, the most commonly used big data analytics platform, was created, its distributed filesystem (HDFS) was modeled after Google File System – which was based on a DDAS model. HDFS and the use of DDAS allowed data scientists to use commodity off-the-shelf systems/components for their analytics pipeline, like X86 processors and standard hard disk drives. While the entry point for big data analytic pipelines was lowered through DDAS and HDFS, it also created a list of significant management problems:
- Data Accessibility: multiple SW tool chains have access to the same data – all the data. The nature of big data analytics use cases requires the flexibility to try new things using your data sources to try to gain new insights from it. This is hard and slow with DDAS – the systems that support it often have custom protocols to access the data – as you would need to migrate the data off of it to a centralized storage platform. This leaves you with data duplication and management of another migration tool to keep it in sync!
- Provisioning: nobody has 20/20 vision into their pipeline’s infrastructure needs over the next few months, let alone years. New software tool chains are being developed all the time. You don’t know which future questions you’ll ask or which future SW applications you’ll use. The homogenous nature of most DDAS deployments force users into a fixed compute:storage ratio. As your compute and storage needs evolve, users will end up with either wasted resources or poor performance due to bottlenecked components.
- Scaling storage: If you ever need to store more data (either because your data ingest increases or you need to retain data for longer), you’ll need to add more storage capacity for your DDAS cluster. You have 2 options:
- 1) Add more nodes, which involves paying for compute that you don’t need and dealing with data rebalancing.
- 2) Take downtime to re-configure your compute-to-storage ratio.
- DAS scaling compute: When you add more nodes to your DDAS deployment, you better have the exact same ratio of compute-to-storage as all your other nodes in your cluster or you’ll be in unknown territory from the performance point of view. The homogeneous model does not allow you to evolve infrastructure to keep up with newer and better components.
- Heterogeneous silos of infrastructure: Big Data initiatives commonly start in isolated business groups. Even from within a single business group, one may need to deploy separate pipelines to isolate production from testing and R&D to provide separation for important jobs. Multiple pipelines plus separate clusters of infrastructure per application result in inefficient silos of DDAS clusters across business groups that are hard to manage and maintain in aggregate.
- DAS monitoring: Because of these silos of infrastructure, a super simple questions like “Am I going to run out of storage soon?” is hard to answer. You now have to subscribe to monitoring software to manage multiple DDAS deployments.
- Ad-hoc or bursty analysis: The Hadoop ecosystem on DDAS is not built for ad-hoc or on-demand analytics; it only works for pre-defined workflows. However, the decoupling of compute and storage allows you to dynamically bring up and tear down clusters of compute to answer your ad-hoc or bursty analytics questions in a distributed manner.
- Software upgrades: Upgrading DDAS is painful. It takes multiple days of planning, testing, and deployment. Most people end up scheduling a large window of downtime to perform an upgrade.
- Data Access management: Kerberos is the only way to get single sign-on.
- Security management: Are all of your infrastructure clusters correctly encrypting their data?
- DAS Backups/Restores: Are all of your infrastructure clusters correctly backing up their data? Why should it take multiple days to restore your data if someone accidentally deletes the production data?
Conclusion on DAS
At Pure Engineering, we have developed a big data analytics pipeline that processes over 18TB of data per day to triage failures from our automated testing. Since we are part of the team that built the FlashBlade™, we decided to use it as the centralized storage solution for all the steps in our pipeline (rsyslog servers, Kafka, Spark, and ElasticSearch). Having a fast, dense, and simple-to-manage centralized storage eliminates all of the above infrastructure headaches that traditionally come with this ecosystem. Reach out to us if you want to learn more about what the FlashBlade can do for your data analytics pipelines!



