

概要
This article shows how to seed a database from a SQL instance that is in a Windows availability group into a SQL instance running in a pod in a Kubernetes cluster using a distributed availability group.


本文介紹了最初出現在 Andrew Pruski 部落格上的 SQL Server 分散式可用性群組。經作者的認可與同意,重新發表。
稍早,我寫了一篇文章,內容是關於如何使用跨平台(或無叢集)的可用性群組,將 Windows SQL 執行個體中的資料庫植入 Kubernetes 中的 Pod。
我上週在跟同事談話,他們問:「如果現有的 Windows 執行個體已經在可用性群組中呢?」
這是一個公平的問題,因為在生產環境中運行獨立的 SQL 實例相當罕見(就我的經驗而言)…大多數實例都是以某種形式進行 HA 設定,無論是容錯移轉叢集實例還是可用性群組。
容錯移轉叢集執行個體將與無叢集可用性群組搭配使用,但對於現有可用性群組而言,這卻是不同的故事。
Linux 節點無法新增至現有的 Windows 可用性群組(信任我,我嘗試了比我願意承認的時間更長的時間),因此唯一方法就是使用分散式可用性群組。
讓我們一起來看看這個過程!
以下是現有的 Windows 可用性群組:
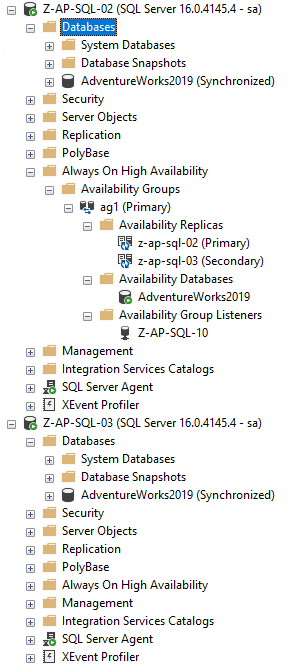
只需一個標準的雙節點 AG,一個資料庫已跨節點同步。這就是我們要使用分散式可用性群組,在 Kubernetes 叢集上執行的 Pod 資料庫。
以下是 Kubernetes 叢集:
kubectl 取得節點
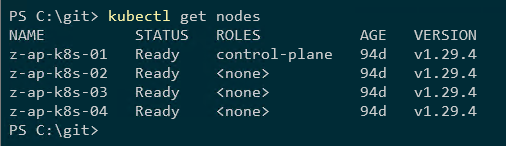
四個節點、一個控制平面節點和三個工人節點。
好的,所以要做的第一件事是部署一個執行 SQL Server pod 的狀態集 (使用稱為 sqlserver-statefulset.yaml 的檔案):
使用 kubectl -f 。\sqlserver-statefulset.yaml
以下是狀態集的體現:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465
api版本:應用程式/v1kind:StatefulSetmetadata: name: mssql-statefulsetspec: serviceName: "mssql" 複本: 1 podManagement政策:平行選取器: matchLabels: name: mssql-pod 範本:中繼資料:標籤:名稱: mssql-pod 附註:stork.libopenstorage.org/disableHyperconvergence: "true" 規格:SecurityContext:fsGroup: 10001 hostAliases: - ip: "10.225.115.129" 主機名稱: - "z-ap-sql-10" 容器: - name: mssql-container 影像: mcr.microsoft.com/mssql/server:2022-CU15-ubuntu-20.04ports: - containerPort: 1433 名稱: mssql-port env: -名稱: MSSQL_PID value:"開發人員" - 名稱: ACCEPT_EULA value:"Y" - name: MSSQL_AGENT_ENABLED value: "1" - name: MSSQL_ENABLE_HADR value: "1" - name: MSSQL_SA_PASSWORD value:"Testing1122" 磁碟區Mounts: - name:sqlsystem mountPath: /var/opt/mssql - name: sqldata mountPath: /var/opt/sqlserver/data volumeClaimTemplates: -中繼資料: name:sqlsystem spec: accessModes: - ReadWriteOnce 資源: 請求: 儲存:1GistorageClassName:mssql-sc - 中繼資料:名稱:sqldata 規格:AccessModes:- ReadWriteOnce 資源:要求:儲存:25GistorageClassName:mssql-sc
就像我上一篇文章一樣,這很棒。無資源限制、容錯等。它有兩個持久性磁碟區:一個是系統資料庫,另一個是叢集中設定儲存類別的使用者資料庫。
請注意:
1234 hostAliases:- ip: "10.225.115.129" 主機名稱: - "z-ap-sql-10"
在這裡,正在為 Windows 可用性群組的聆聽者建立 Pod 主機檔案中的項目。
接下來要做的是部署兩種服務:一種是我們可以連接到 SQL 執行個體(在連接埠 1433 上),另一種是 AG(連接埠 5022):
適用 -f 的 kubectl。\sqlserver-services.yaml
以下是服務清單:
12345678910111213141516171819202122232425 api版本:版本 1 親筆:服務中繼資料:名稱:mssql-servicespec:連接埠:-名稱:mssql-連接埠:1433 targetPort:1433 選擇器:名稱:mssql-pod 類型:LoadBalancer---apiVersion: v1kind:服務中繼資料:名稱:mssql-ha-servicespec:連接埠:-名稱:mssql-ha-ports 連接埠:5022 targetPort:5022 選擇器:名稱:mssql-pod 類型:負載平衡器
注意:我們可以只使用一個服務,設定多個連接埠,但我會把它們分開來,盡量讓事情保持清晰。
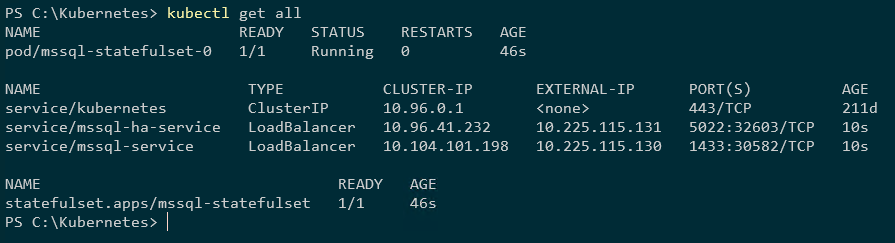
檢查一切是否正常:
kubectl 全部
現在,我們需要在所有情況下建立主金鑰、登入和使用者:
123 以密碼建立主金鑰加密 = '
然後,在 Pod 的 SQL 實例中建立憑證:
建立主旨 = 'Mirroring_certificate', EXPIRY_DATE = '20301031' dbm_certificate的證書
備份該憑證:
123456 備份認證dbm_certificate至檔案 = 使用'/var/opt/mssql/data/dbm_certificate.cer'私密金鑰(檔案 = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION 依密碼 = '
在本地複製憑證:
12 kubectl cp mssql-statefulset-0:var/opt/mssql/data/dbm_certificate.cer ./dbm_certificate.cer -n prodkubectl cp mssql-statefulset-0:var/opt/mssql/data/dbm_certificate.pvk ./dbm_certificate.pvk -n prod
然後將檔案複製到 Windows 方塊中:
1234 Copy-Item dbm_certificate.cer \\z-ap-sql-02\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.pvk \\z-ap-sql-02\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.cer \\z-ap-sql-03\E$\SQLBackup1\ -ForceCopy-Item dbm_certificate.pvk \\z-ap-sql-03\E$\SQLBackup1\ -Force
檔案放在 Windows 方塊後,我們就可以在每個 Windows SQL 實例中建立憑證:
1234567 dbm_user 從檔案建立憑證dbm_certificate 授權 = 'E:\SQLBackup1\dbm_certificate.cer' 使用私密金鑰 (檔案 = 'E:\SQLBackup1\dbm_certificate.pvk', DECRYPTION 密碼 = '')
好的,太好了!現在我們需要在 Pod 的 SQL 實例中建立鏡像端點:
123456789101112 建立端點[Hadr_endpoint]狀態 = 開始為 TCP ( LISTENER_PORT 5022, LISTENER_IP = 全部)針對 DATA_MIRRORING( 角色 = 全部,驗證 = WINDOWS 認證[dbm_certificate],加密 = 所需的演算法 AES);變更端點[Hadr_endpoint]狀態 = 已開始;在端點上建立連線:[Hadr_endpoint]至[dbm_login];
Windows 執行個體中已有端點,但我們需要更新這些端點,才能使用憑證進行驗證:
12345678910 變更端點[Hadr_endpoint]狀態 = 啟動狀態 TCP ( LISTENER_PORT 5022, LISTENER_IP = 全部)DATABASE_MIRRORING( 驗證 = WINDOWS 憑證[dbm_certificate],加密 = 所需的演算法 AES);在端點上允許連線:[Hadr_endpoint]至[dbm_login];
現在,我們可以在 Pod 的 SQL 實例中建立單節點無叢集可用性群組:
12345678910111213 建立可用群組[AG2],FORREPLICA(CLUSTER_TYPE=NONE) ON'mssql-statefulset-0',其中 ( ENDPOINT_URL = 'TCP://mssql-statefulset-0.com:5022', FAILOVER_MODE = MANUAL ,AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ,BACKUP_PRIORITY = 50 ,SEEDING_MODE = AUTOMATIC ,SECONDARY_ROLE(ALLOW_CONNECTIONS = = 否))
這裡沒有聽眾;我們將使用 mssql-ha-service 作為分散式可用性群組的端點。
好的,在 Windows 可用性群組的主要節點上,我們可以建立分散式可用性群組:
1234567891011121314151617 建立可用群組 [DistributedAG](分散式) 可用群組 ON'AG1' with ( LISTENER_URL = 'tcp://Z-AP-SQL-10:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE MANUAL, SEEDING_MODE = 自動 ), 'AG2' with ( LISTENER_URL 'tcp://10.225.115.131:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE MANUAL, SEEDING_MODE = 自動 );
我們可以為 AG2 中的 URL 使用主機檔案輸入(我在上一篇文章中做過),但在這裡,我們只會使用 mssql-ha-service 的 IP 位址。
好的,快到了!我們現在必須在 Pod 的 SQL 實例中加入可用性群組:
1234567891011121314151617 ALTER 可用性 GROUP ON'AG1' 加入 ( LISTENER_URL[DistributedAG]可用性 GROUP ON= 'tcp://Z-AP-SQL-10:5022', AVAILABILITY_MODE ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = 自動 ), 'AG2' WITH ( LISTENER_URL 'tcp://10.225.115.131:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE MANUAL, SEEDING_MODE = 自動 );
就應該如此!如果我們現在連線到 Pod 中的 SQL 執行個體,資料庫就在這裡!
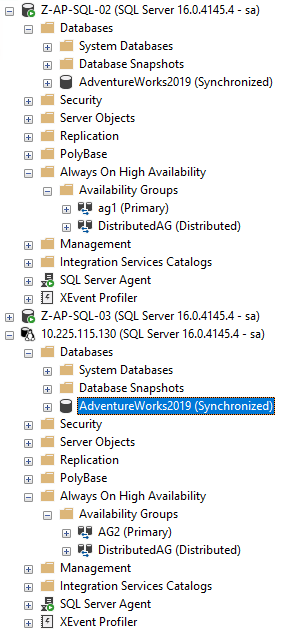
就在這裡!好的,我還沒經歷過這一件事,就是如何將 Windows 的自動搜尋功能變成 Linux SQL 執行個體。我在上一篇文章中探討了如何運作,但 gist 就是,只要資料庫資料和日誌檔案位於 Windows SQL 執行個體的預設資料和日誌路徑下,它們就會自動鎖定到 Linux SQL 執行個體的預設資料和日誌路徑。
這就是如何將 Windows 可用性群組中的 SQL 執行個體資料庫,植入使用分散式可用性群組的 Kubernetes 叢集中的 pod 中執行的 SQL 執行個體。

Stellar Storage
Boost performance for SQL Server with Pure Storage.



