概要
Storage is the backbone of AI, but as model complexity and data intensity increase, traditional storage systems can’t keep pace. Agile, high-performance storage platforms are critical to support AI’s unique and evolving demands.


在邁向人工智慧 (AGI) 的競爭中,儲存技術正在加快腳步。雖然演算法和運算是焦點,但儲存裝置仍推動 AI 的突破。在快閃革命期間,每兩年 15K 磁碟停滯一倍的運算效能,但啟用了快閃技術的虛擬化,如今,GPU 驅動的工作負載正在推動儲存創新,同時需要效率、永續性和可靠性。
早期的 AI 工作受到演算法複雜性和資料不足的限制,但隨著演算法的進步,記憶體和儲存的瓶頸也隨之出現。高效能儲存技術,如 ImageNet,推動了視覺模型,以及 GPT-3,需要 PB 儲存空間。儲存設備每天產生 4 億 TB 的資料,必須以毫秒以下的延遲管理 exabyte 級工作負載,以推動 AGI 和量子機器學習。隨著 AI 的發展,每波創新都對儲存設備提出了新的需求,推動容量、速度和可擴充性的進步,以適應日益複雜的模型和更大的資料集。
- 經典機器學習 (1980s-2015):語音辨識和監督式學習模式將資料集從百萬位元組成長到百萬位元組,使資料擷取和組織變得越來越重要。
- 深度學習革命 (2012-2017): 像 AlexNet 和 ResNet 這樣的模型推動了儲存需求,而 Word2Vec 和 GloVe 則進階了自然語言處理,改用適用於 TB 級資料集的高速 NVMe 儲存。
- 基礎模型 (2018-現在): BERT 推出了 PB 級資料集,其中 GPT-3 和 Llama 3 需要可擴充的低延遲系統,如 Meta 的 Tectonic,以處理數兆令牌並維持每秒 7TB 的輸送量。
- Chinchilla 擴展法 (2022): Chinchilla 強調,與 LLM 模型大小相比,資料集不斷增長,需要並行存取儲存來優化效能。
儲存設備不僅支援 AI,更透過有效且大規模地管理全球不斷增長的資料,引領業界,塑造創新的未來。舉例來說,自動駕駛中的 AI 應用程式仰賴能夠即時處理 PB 級感應器資料的儲存平台,而基因體學研究則需要快速存取大量資料集,以加速發現。隨著 AI 持續突破資料管理的界限,傳統儲存系統面臨著與這些不斷演進的需求同步的挑戰,突顯出對專用解決方案的需求。
AI 工作負載如何拉傷傳統儲存系統
資料合併與磁碟區管理
AI 應用程式可管理從 TB 到數百 PB 的資料集,遠遠超過 NAS、SAN 和傳統直連式儲存等傳統儲存系統的功能。這些系統專為產生報告或檢索特定記錄等精確的交易工作負載而設計,難以應對資料科學的繁重整合需求,以及 AI/ML 工作負載的掃瞄、高速存取模式。模型訓練需要整個資料集大規模批次資料擷取,並強調這種不一致之處。傳統基礎架構的剛性架構、容量限制和輸送量不足,使其不適合 AI 的規模和速度,凸顯了對專用儲存平台的需求。
高速資料存取的效能瓶頸
即時分析和決策對於 AI 工作負載而言至關重要,但傳統的儲存架構通常會造成 IOPS 不足的瓶頸,因為它們是針對中等交易任務而非 AI 密集的平行讀取/寫入需求所打造。此外,旋轉磁碟或過時的快取機制所產生的高延遲,會延遲資料存取,增加取得深度資訊的時間,並降低 AI 流程的效率。
處理各種資料類型和工作負載
AI 系統可處理結構化和非結構化資料,包括文字、影像、音訊和影片,但傳統儲存解決方案卻難以應付這種多樣性。它們通常針對結構化資料進行優化,導致擷取速度緩慢,處理非結構化格式效率低下。此外,索引和中繼資料管理不佳,使得難以有效組織和搜尋各種資料集。傳統系統也面臨小檔案的效能問題,在訓練語言模型中很常見,因為高中繼資料負荷會導致延遲和處理時間延長。
傳統架構限制
這些挑戰的累積效應是傳統儲存架構無法跟上現代 AI 工作負載的需求。他們缺乏所需的靈活性、效能和可擴充性,以支援 AI 的多樣化和大容量資料需求。這些限制突顯出對進階儲存解決方案的需求,這些解決方案的設計是為了處理 AI 應用程式的獨特挑戰,例如快速擴充性、高傳輸量、低延遲和多樣化的資料處理。
AI 面臨的主要儲存挑戰
AI 工作負載對儲存系統有獨特的需求,而解決這些挑戰需要以下領域的進階功能:
- 整合式資料整合:資料孤島會分散寶貴的資訊,需要整合到支援各種 AI 工作負載的整合式平台,以進行流暢的處理和訓練。
- 可擴充的效能與容量:一個強大的儲存平台必須管理各種 I/O 設定檔,並擴展至 TB 到 exabyte,確保低延遲、高傳輸量的存取。該平台能夠實現不中斷的擴展,使 AI 工作負載能夠隨著資料需求的增長而無縫擴展,並保持順暢、不間斷的作業。
- 橫向擴充彈性: 為訓練和推論處理向量資料庫和高並行工作負載的低延遲交易存取,需要同時提供兩種功能的平台。
- 可靠性與持續運作時間:隨著 AI 對企業至關重要,99.9999% 的正常運行時間至關重要。儲存平台必須支援不中斷的升級和硬體更新,確保持續運作,終端使用者不會看到停機時間。
跨 AI 管道優化儲存
有效的儲存解決方案在 AI 流程的每個階段都至關重要,從資料整理到訓練和推論,因為它們能夠使 AI 工作負載高效且大規模地運行。AI 管線需要能夠順暢處理延遲敏感任務的儲存裝置,可擴充以滿足高並行性需求,支援各種資料類型,並在分散式環境中維持效能。
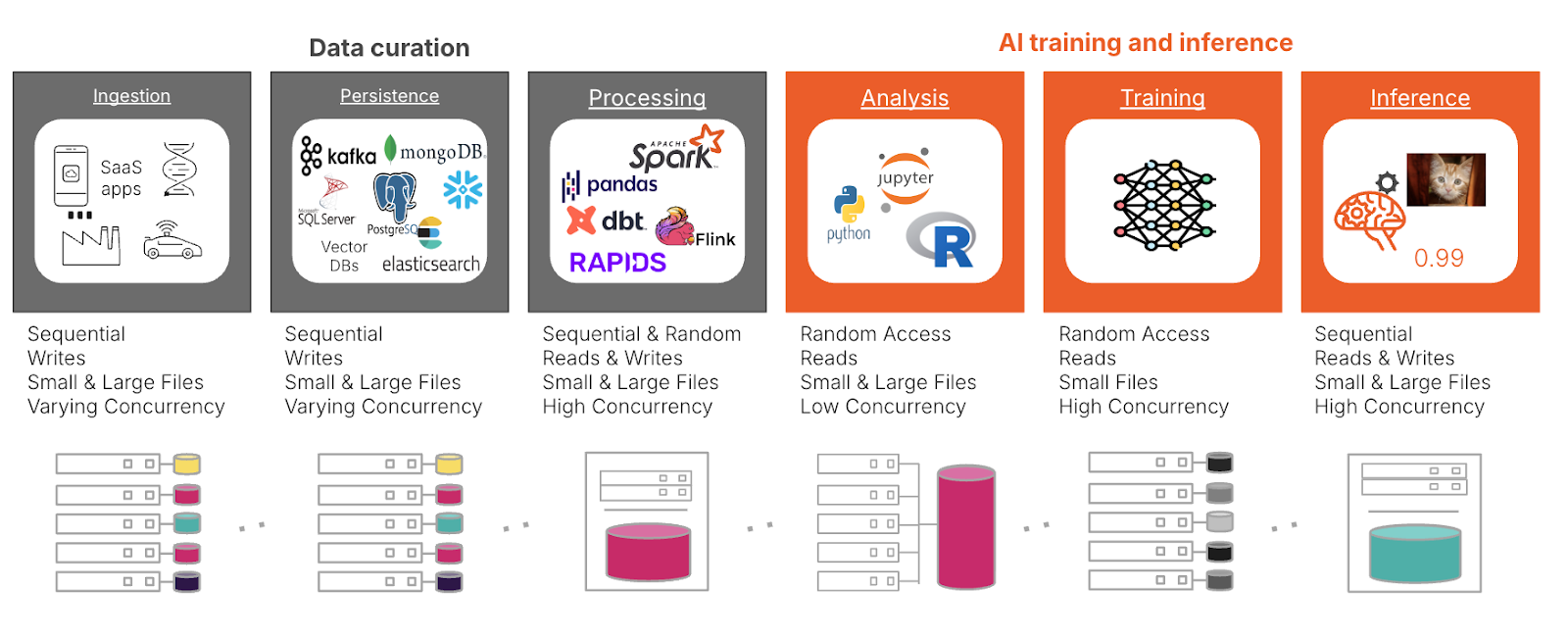
圖 1:AI 的儲存模式各不相同,需要一個專為多維效能打造的平台。
在資料固化階段,管理 PB 到 EB 規模的資料集從擷取開始,儲存裝置必須無縫擴展,以處理大量資料,同時確保高傳輸量。自動駕駛等即時應用程式需要低延遲儲存,才能立即處理傳入的資料。DirectFlash® 模組 (DFM) 在這些情境中表現優異,繞過傳統的 SSD 架構直接存取 NAND 快閃記憶體,提供更快速、更一致的效能,並大幅降低延遲。與舊版 SSD 和 SCM 相比,DFM 也提供更高的能源效率,使組織能夠滿足大規模 AI 工作負載的需求,同時優化功耗,並在高並行性下維持可預測的效能。
資料雲端資料儲存方案:必須支援經常存取的資料的長期保留和快速存取。處理步驟是準備訓練資料的關鍵,儲存裝置必須有效管理各種資料類型與大小,以 NFS、SMB 與物件等格式處理結構化與非結構化資料。
在 AI 訓練和推論階段,模型訓練會產生密集的讀取/寫入需求,需要橫向擴充的架構,以確保多個節點的效能。高效的檢查點和版本控制系統是避免資料遺失的關鍵。除了檢查點之外,新興的基礎架構如擷取擴增世代(RAG),也為儲存系統帶來了獨特的挑戰。RAG 在推論過程中仰賴有效擷取外部知識庫,要求低延遲、高傳輸量的儲存裝置,能夠處理並行、平行的查詢。這增加了中繼資料管理和可擴展索引的壓力,需要先進的儲存架構來優化效能,而不會遇到瓶頸。
透過讓儲存解決方案與每個管道階段的特定需求保持一致,組織可以最佳化 AI 效能,並維持所需的彈性,以支援不斷演進的 AI 需求。
結論
儲存是 AI 的骨幹,模型複雜度和資料密集度不斷增加,導致對基礎架構的需求呈指數級。傳統的儲存架構無法滿足這些需求,因此必須採用靈活、高效能的儲存解決方案。
AI AI 與儲存平台之間的共生關係,不僅代表儲存裝置的進步,更代表著儲存裝置的支援,以及加速 AI 的進展。對於剛開始探索 AI 的公司而言,彈性至關重要:他們需要能夠隨著資料和運算需求成長而擴展的儲存裝置,並支援多種格式(例如檔案、物件),以及輕鬆與現有工具整合。
投資於現代化儲存平台的組織,將自己定位在創新的最前線。這需要:
- 評估基礎架構:找出目前的限制和需要立即改善的領域。
- 採用可擴充的解決方案:實施能提供彈性、高效能和無縫成長的平台。
- 規劃未來需求: 隨時掌握新興趨勢,確保平台隨 AI 發展而進化。
透過將儲存平台列為 AI 策略的核心要素,組織可以釋放新商機、推動持續創新,並在資料驅動的未來維持競爭優勢。
想要了解更多?
造訪 AI 解決方案頁面
觀看網路研討會重播:”加速策略企業 AI 基礎架構的考量“
下載白皮書:Pure Pure Storage AI 平台 AI

A Game-changer for AI
Accelerate your AI initiatives with the Pure Storage platform.