

概要
FlashBlade//EXA is the newest member of the FlashBlade family. Optimized for AI workloads, this ultra-scale data storage platform provides massive storage throughput and operates at extreme levels of performance and scale.


賽車手,發動引擎!Pure Storage 很高興地宣布 FlashBlade//EXAza-一個超大規模的資料儲存平台,它針對 AI 工作負載進行了優化,可提供龐大的儲存輸送量,並在極高的效能和規模下運行。
高效能汽車製造商和 Pure Storage 有什麼共同點? FlashBlade FlashBlade//EXA 與頂尖的汽車製造商設計尖端的賽車模式一樣,能夠突破速度與效率的限制,專為 AI 與 HPC 工作負載提供更上一層的效能。FlashBlade//EXA 與這些範例相似,因為其為 FlashBlade® 系統,並經過 Purity//FB 高度優化,可為最嚴苛的 AI 工作負載提供更上一層的效能。它補充了高效能 FlashBlade//SCOR 和高密度 FlashBlade//ECOR 模型,這些模型在企業市場中得到了驗證,並連續四年被 Gartner® Magic Quadrant 認證為檔案暨物件式儲存平台的領導者。
快速 AI 發展的商業挑戰
隨著 AI 創新不斷擴展,許多企業正在迅速發現運用模型訓練和推論來增強或革新現有營運的價值。這樣的加速成長讓前置處理、訓練、測試、微調和部署的 AI 工作流程更加普及,這些都受益於更強大的 GPU 和更大的多模式資料集。
此次擴展也帶來了新的基礎架構挑戰。傳統的儲存可擴充性、檢查點、管理和大規模中繼資料效能限制正在造成瓶頸,阻礙了昂貴的 GPU 導向基礎架構的充分利用,並減慢進度和創新。這大大影響了 AI 積極的 ROI 財務壓力,任何專用於它的基礎架構都必須以最高效能運行,以確保模型訓練和推論能有最快的價值。時間損失就是金錢損失。
大規模 AI 工作流程能強化業務挑戰
閒置 GPU 等同損失時間與金錢的商業挑戰,會因為兩個理由而大規模擴大,例如 GPU 雲端供應商與 AI 實驗室。首先,大規模的營運效率是其獲利能力的核心,其範圍遠遠超過大多數就地部署/內部資料中心的營運所管理的範圍。我們在去年發表了一篇部落格文章,探討了服務供應商的想法,以及自動化和嚴格標準化對其營運的重要性。其次,服務供應商訂閱了避免任何資源閒置的核心原則。對於他們而言,任何 AI 模型中的閒置 GPU 都是一個損失營收的機會,因為儲存效率低落的營運層級可能會帶來損害。
傳統高效能儲存架構建立在平行檔案系統之上,並針對傳統專用高效能運算 (HPC) 環境進行設計與最佳化。HPC 工作負載是可預測的,因此平行儲存系統可以針對特定的效能擴充進行最佳化。大規模的 AI 工作流程和模型與傳統 HPC 不同,因為它們比較複雜,涉及更多參數,這些參數也包含文字檔案、影像、影片等,所有這些都需要由數萬個 GPU 同時處理。這些全新動態正迅速證明傳統 HPC 式儲存方法難以達到更大規模的效能。更具體地說,傳統並行儲存系統的效能對於從同一儲存控制器平面服務中繼資料和相關資料變得相當滿意。
這種新興的瓶頸需要對中繼資料管理和資料存取最佳化進行新的思考,才能以服務供應商的規模,有效率地管理各種資料類型和 AI AI 工作負載的高並行性。
AI AI 工作負載演進帶來的極致儲存擴展需求
隨著資料量的激增,中繼資料的管理成為一個關鍵的瓶頸。傳統儲存裝置難以有效率地擴充中繼資料,導致延遲和效能降低,尤其是需要極端平行處理的 AI 和 HPC 工作負載。傳統基礎架構,專為循序存取而打造,無法跟上腳步。它們經常受到韌性和複雜性的影響,因而限制了擴展性。克服這些挑戰需要以中繼資料為優先的基礎架構,才能順暢擴展、支援大規模平行處理,並消除瓶頸。隨著 AI 和 HPC 機會的演進,挑戰只會變得複雜。

FlashBlade//S 中經驗證的中繼資料核心,已協助企業客戶克服中繼資料的挑戰,以因應 AI AI 訓練、調校和推論等需求,例如:
- 並行管理: 有效處理多個節點的大量中繼資料請求
- 熱點預防: 避免單一中繼資料伺服器瓶頸,這些瓶頸會降低效能,並需要持續進行調校和最佳化
- 大規模一致性: 確保分散式中繼資料副本之間的同步
- 高效率的階層管理: 優化複雜的檔案系統操作,同時維持效能
- 擴充性和彈性: 隨著資料量呈指數增長,維持高效能
- 營運效率:確保管理與開銷最小化並自動化,以支援大規模的效率
FlashBlade//EXA 解決大規模的 AI 效能挑戰
Pure Storage 在各種高效能使用案例以及 AI 旅程中每個階段,皆擁有為客戶提供支援的經驗。自 2018 年推出 AIRI®(AI-Ready 基礎架構)以來,我們持續引領創新,如 NVIDIA DGX SuperPOD 認證和 NVIDIA DGX BasePOD 認證,以及 GenAI Pods 等統包解決方案。FlashBlade 贏得企業 AI 和 HPC 市場的信任,協助 Meta 這類組織有效率地擴展 AI 工作負載。我們的中繼資料核心建立在大規模分散式交易資料庫之上,而關鍵價值儲存技術可確保高度中繼資料可用性與高效率擴充。Pure Storage 運用超大規模用戶的深度資訊,並運用經 FlashBlade//S 認證的進階中繼資料核心,提供獨特的高效能儲存能力,克服大規模 AI 和 HPC 的中繼資料挑戰。
進入 FlashBlade//EXA。
隨著極端的端到端 AI 工作流程突破了基礎架構的極限,對符合此規模的資料儲存平台的需求變得前所未有的大。FlashBlade//EXA 擴展 FlashBlade 系列,確保大規模 AI 和 HPC 環境不再受傳統儲存限制的限制。
FlashBlade//EXA 專為 AI 工廠設計,並提供大規模平行處理基礎架構,可分解資料和中繼資料,消除與傳統平行檔案系統相關的瓶頸和複雜性。以經實證的 FlashBlade 優勢為基礎,並採用 Purity//FB 的先進中繼資料基礎架構,在任何規模上都能提供無與倫比的吞吐量、可擴充性與簡易性。
無論是支援 AI 原生技術、科技整合、AI 驅動的企業、GPU 驅動的雲端供應商、HPC 實驗室或研究中心,FlashBlade//EXA 都能滿足資料密集型環境的需求。其次世代設計可實現流暢的生產、推論和訓練,即使是要求最嚴苛的 AI 工作負載也能提供全面的資料儲存平台。
我們在 Purity//FB 的修改過程中採用創新方法,將高速傳輸網路式 I/O 分為兩個獨立元素:
- FlashBlade 陣列透過領先業界的橫向擴充分散式金鑰/值資料庫儲存並管理中繼資料。
- 第三方資料節點叢集使用業界標準的網路協定,從 GPU 叢集以極高速儲存和存取資料區塊,透過遠端直接記憶體存取 (RDMA)。
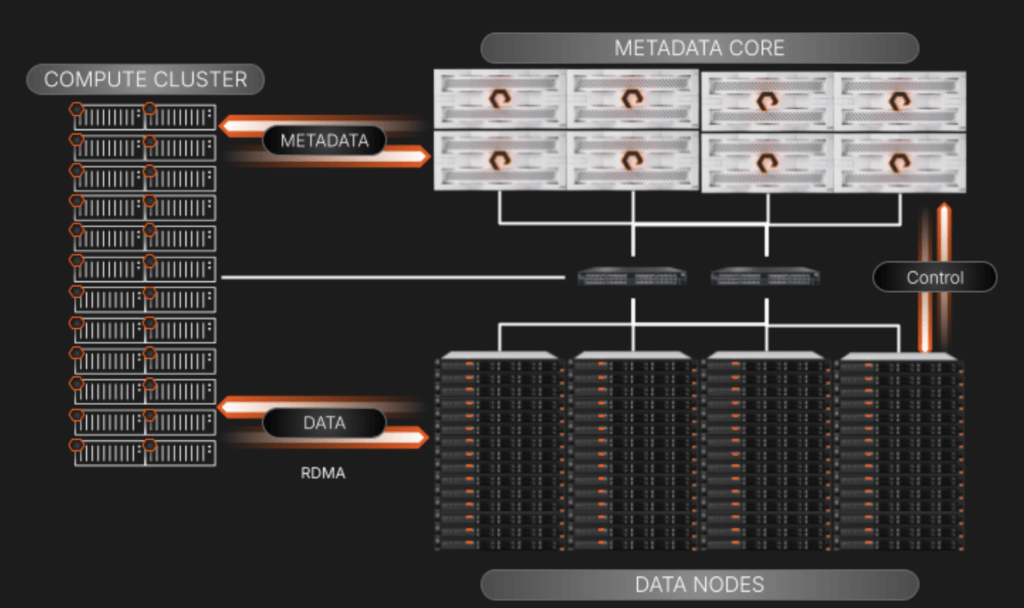
此隔離提供非封鎖資料存取功能,在高效能運算情境中,中繼資料請求可能等於資料 I/O 作業,如果不超出數字,則其將呈指數級增加。
為何選擇資料節點專用的現成伺服器和 SSD?
大規模的 AI 環境可以建立 1U 和 2U 伺服器的投資,並以 SSD 作為基礎架構的基石。FlashBlade//EXA 為資料平面運用現成的伺服器,讓適應目標客戶的基礎架構變得更容易(在這種情況下是大規模環境)。重點在於我們的資料儲存平台:
*Purity 作為我們平台的核心,其優勢在於能夠進行修改,以解決新的使用案例,即使這意味著要延伸到我們自己的硬體之外操作。透過我們的軟體解決挑戰是我們的核心原則,因為它是一種更優雅的方法,並為客戶提供更快的價值。
這些現成的資料節點讓客戶有彈性地適應時間變化,並可由客戶在其資料中心如何利用 NAND 快閃記憶體的演變所驅動。
FlashBlade FlashBlade//EXA 元件與 I/O 的高階視圖
將中繼資料和資料服務平面分開時,我們專注於使上圖中的元素易於擴展和管理:
- Metadata核心: 此服務可處理運算叢集中的所有中繼資料查詢。查詢服務完成後,請求的運算節點將導向特定資料節點以執行其工作。陣列也會透過其網路區段的幕後控制平面連線,監督資料節點與中繼資料之間的關係。
- 第三方資料節點:這些是標準的現成伺服器,可確保廣泛的相容性與彈性。 資料區塊位於這些伺服器的 NVMe 硬碟上。他們將運行以 Linux 為基礎的薄型OS和內核,並具有容量管理和 RDMA 目標服務,這些服務是為與 FlashBlade FlashBlade//EXA 陣列上的中繼資料配合而自訂的。我們將包含 Ansible 教戰手冊,以管理節點的部署和升級,並消除任何大規模複雜度的問題。
- 使用現有網路環境並行存取資料: FlashBlade//EXA 採用一種優雅的方法,利用高可用性的單核心網路,利用 BGP 來路由和管理中繼資料、資料和工作負載用戶端之間的流量。這種設計能夠無縫整合現有客戶網路,簡化高度並行儲存環境的部署。重要的是,所有使用過的網路協定都是業界標準;通訊堆疊不包含專有元素。
運用平行檔案系統與分解式模型,解決傳統高效能儲存的挑戰
許多針對大型 AI 工作負載高效能性質的儲存供應商,只能解決一半的平行處理問題,為客戶提供最寬的網路頻寬,以達成資料目標。它們無法解決中繼資料和資料如何以龐大的傳輸量提供服務,這就是大規模瓶頸出現之處。之所以如此合理,是因為當 Sun Microsystems 於 1984 年重新建立 NFS 設計時,其目的就是單純彌補本地和遠端檔案存取之間的差距,因為設計焦點在於功能與速度的關聯。
使用傳統 NAS 擴展的挑戰
傳統 NAS 的設計和規模,由於其單一用途設計能夠服務作業檔案共用,且無法隨著增加控制器而線性擴展 I/O,因此無法支援平行儲存。
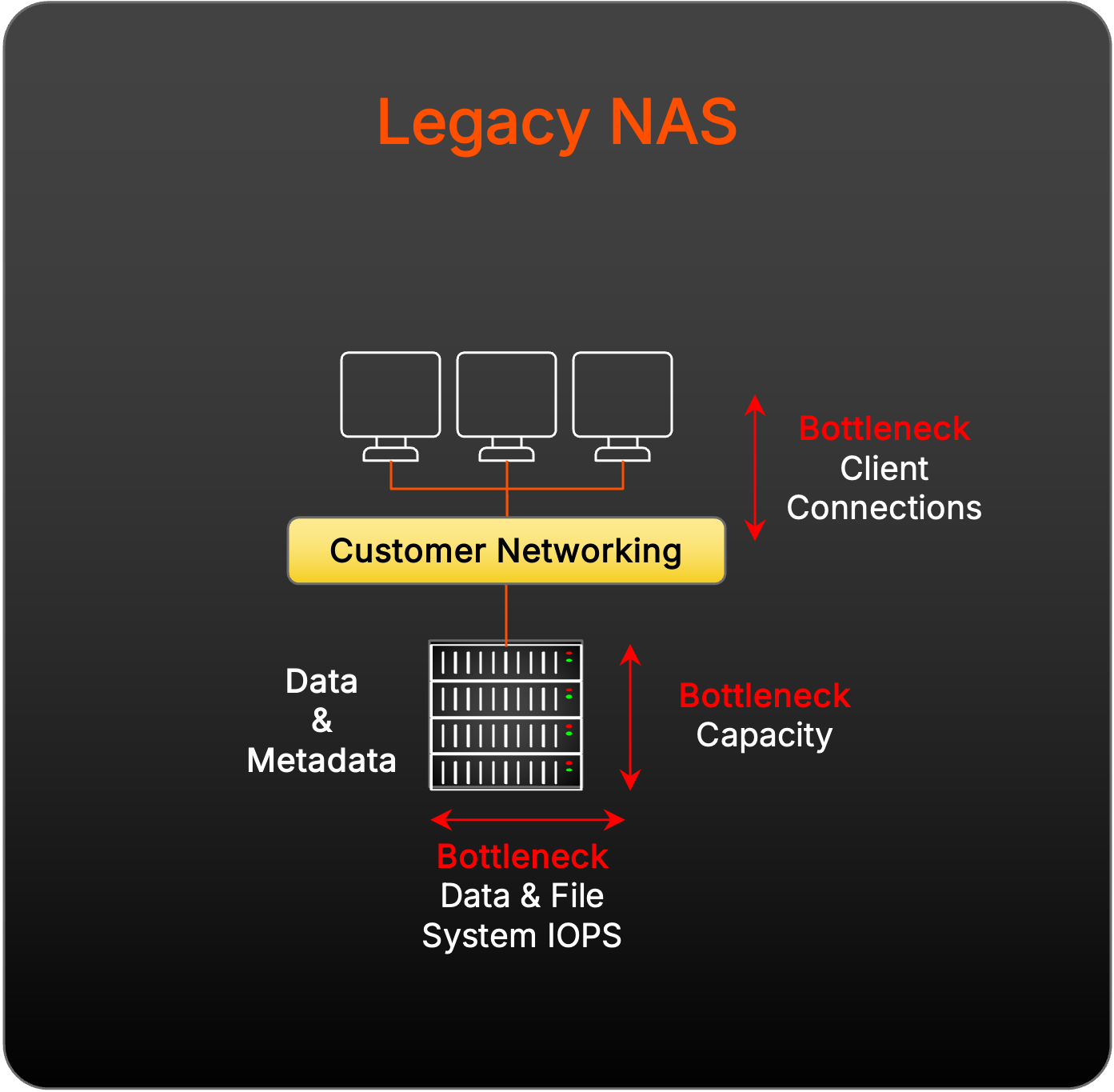
使用傳統平行檔案系統擴展的挑戰
即使在目前 AI 崛起之前,一些傳統儲存供應商利用 Lustre 等專門的平行檔案系統,為高效能運算需求提供高傳輸量平行處理。雖然這適用於數個大型和小型環境,但容易出現中繼資料延遲、極其複雜的網路和管理複雜性,通常轉交給負責監督 HPC 架構和相關軟成本的博士,以因應更大的需求。
分解資料與運算解決方案的挑戰
其他儲存供應商已將其解決方案建構成不僅仰賴於專用並行檔案系統,也在工作負載用戶端與中繼資料和資料目標之間新增運算彙總層:
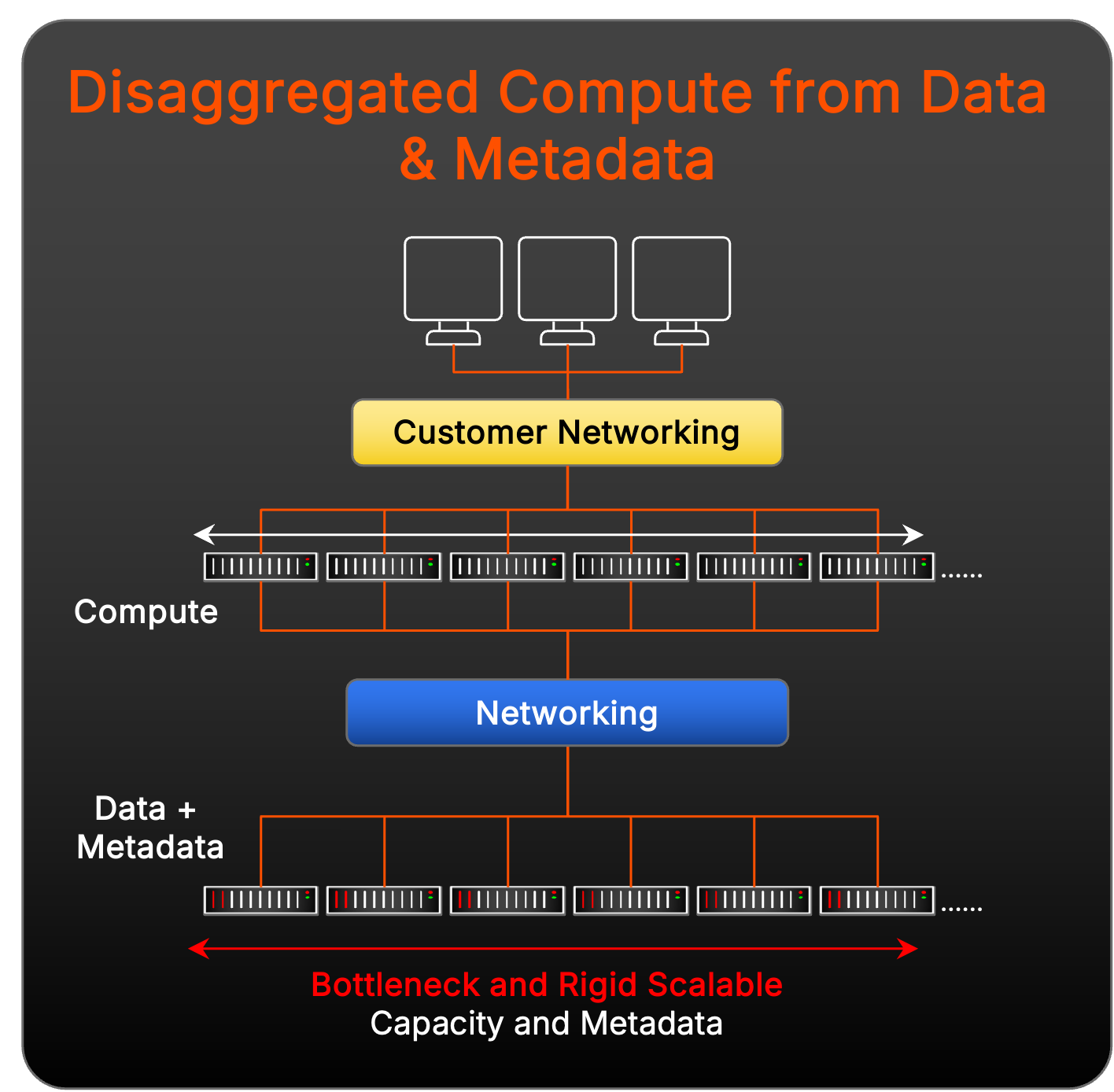
這種模型在擴展大量效能時,比 pNFS 面臨擴展韌性與管理複雜度挑戰,因為它涉及使用運算彙總節點增加更多活動零件。還有另一個潛在的挑戰,在這個模型中部署分解的資料存取功能,會面臨堆疊中意外延遲的風險,因為相較於 pNFS 的需求,其網路在管理三個離散層的定址、佈線和連接方面變得更加複雜。
此外,每個資料和中繼資料節點都會被指派固定數量的快取,永遠儲存中繼資料。這種剛性迫使資料和中繼資料在鎖定階段擴展,從而為多模式和動態工作負載創造低效率。而且,隨著工作負載需求的變化,這種線性擴展方法可能導致效能瓶頸和不必要的基礎架構超額配置,進一步使資源管理變得複雜,並限制靈活性。
我們才剛開始
我們的 FlashBlade//EXA 公告徹底改變了大規模 AI 工作負載的效能、可擴充性和簡易性。我們才剛開始。
請聯絡您的 Pure Storage 團隊,以深入了解我們如何再次顛覆業界快速成長的產業傳統思維!
3 月 17 日至 21 日,歡迎參加 NVIDIA GTC 2025。 預訂會議。
深入了解 pure.ai 和我們的 AI 解決方案頁面。

FlashBlade//EXA
Experience the World’s Most Powerful Data Storage Platform for AI
Join the Webinar
Discover the power of FlashBlade//EXA for AI workloads. April 24, 2005.



