
Wir freuen uns sehr, DirectFlash™ Fabric vorzustellen, das die DirectFlashTM-Familie mittels RDMA over converged Ethernet (auch bekannt als RoCEv2) über das Array hinaus und in die Fabrics bringt. DirectFlash Fabric revolutioniert die Art und Weise, wie Anwendungen auf ein FlashArray zugreifen, und erfüllt die Anforderungen für die Disaggregation von Direct-Attached Storage. DirectFlash Fabric ist ab dem 16. Januar 2019 mit einem unterbrechungsfreien Firmware-Upgrade und der Installation eines RDMA-fähigen NICs in den Storage-Controllern allgemein erhältlich.
Um mehr zu erfahren, lesen Sie bitte unten weiter.

WARUM UNTERNEHMEN IN KÜRZESTER ZEIT ERGEBNISSE LIEFERN MÜSSEN
In dieser digitalen, mobilen, modernen Welt sind unsere Erwartungen stark gestiegen und steigen von Tag zu Tag weiter an. Als Gesellschaft erwarten wir „Ergebnisse in kürzester Zeit“. Das war nicht immer so. Die früheren Anwendungen waren seriell. Die Daten wurden eingegeben, danach verarbeitet und eventuell wurden später Berichte dazu geliefert. Die heutigen Anwendungen bieten Parallelverarbeitung, maschinelles Lernen und künstliche Intelligenz. In modernen Anwendungen werden die Daten parallel zur Eingabe verarbeitet (z.B. bei der Google-Suche), so dass wir Ergebnisse in Echtzeit erhalten. Dieser Anwendungswechsel erfordert eine neue Art von Infrastruktur, die eine gleichzeitige und parallele Verarbeitung bei extrem niedriger Latenz und hoher Performance bietet. Bei Storage ist das der Wechsel von SCSI (oder Small Computer System Interface), das in den 90er Jahren für Festplatten entwickelt wurde, zu NVMe (oder Non-Volatile Memory Express), das für Flash entwickelt wurde. Dieser Wechsel hat die Daten näher an die Verarbeitungseinheit und damit näher an die Anwendung gebracht und ermöglicht den Echtzeitzugriff auf Daten. Leider handelt es sich jedoch bei den meisten heute verfügbaren Storage-Arrays für Unternehmen um ältere SCSI-Lösungen, die auf Festplattentechnologie für serielle Anwendungen basieren. Das macht die Bereitstellung eines sofortigen Echtzeitzugriffs auf Daten zu einer großen Herausforderung für das Unternehmen.
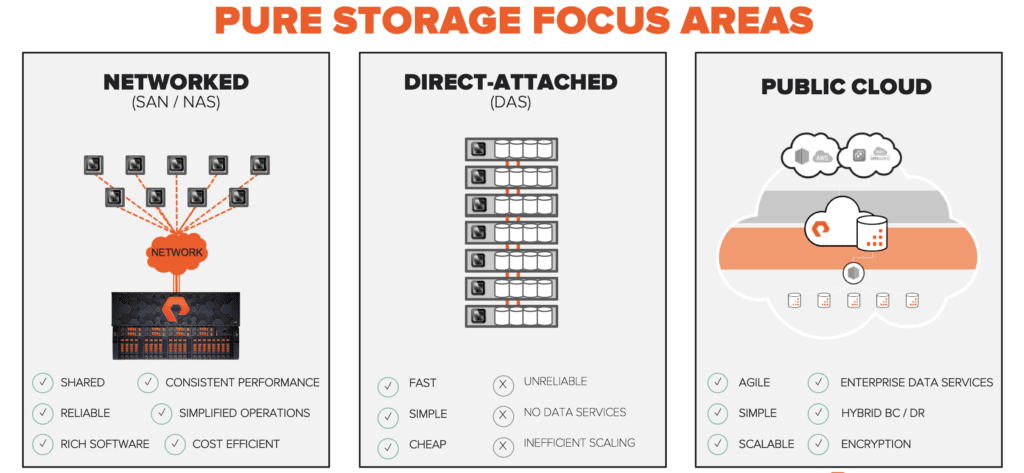
Dazu kommt, dass Anwendungen, die diese Daten verarbeiten, sehr unterschiedliche Anforderungen stellen, was zur Entstehung von Silos geführt hat. Jede Anwendung erforderte eine eigene, maßgeschneiderte Storage-Architektur, was zu unterschiedlichen Benutzererfahrungen führte. Bei Pure haben wir uns darauf konzentriert, die Herausforderungen des vernetzten Storage (SAN und NAS) mit FlashArray™ und FlashBlade™ zu bewältigen, indem wir ein Produkt von Grund auf Basis von Flash und nicht von Festplatten erstellt haben. Wir haben vor kurzem mit Cloud Block Store eine neue Reihe von Cloud-Datenservices zur Verbesserung der Public Cloud vorgestellt. Wir haben uns dabei jedoch weniger auf DAS konzentriert, das viele der analytischen Anwendungen mit hoher Gleichzeitigkeit von heute ausführt.
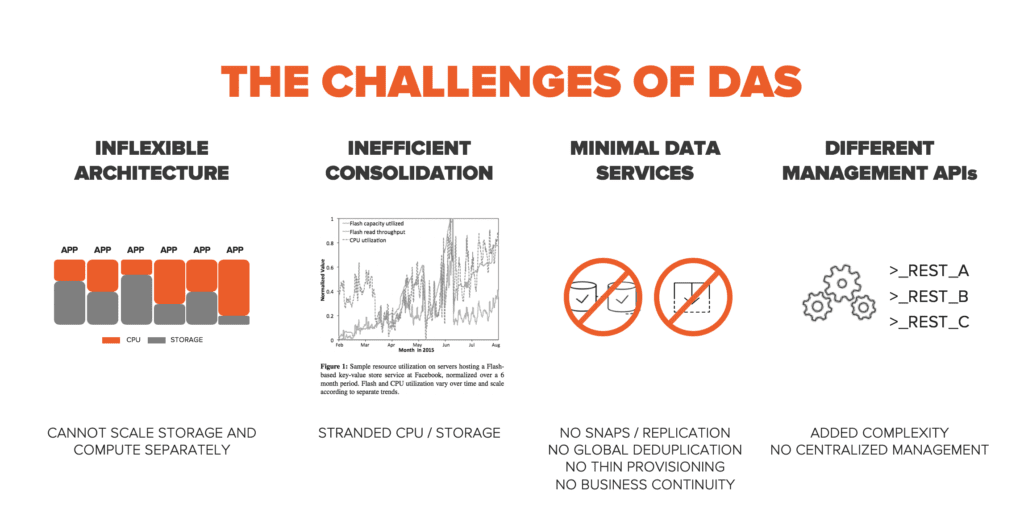
DAS STELLT VIELE HERAUSFORDERUNGEN, SODASS HYPERSCALE-BENUTZER ZUR DISAGGREGATION ÜBERGEGANGEN SIND
DAS wird typischerweise auf standardisierten Servern webbasiert eingesetzt. Die Standardisierung macht die Bereitstellung zwar einfach, die Anwendungen weisen jedoch verschiedene Bereiche und Größen bezüglich Berechnung und Storage auf, was überall zum Verlust von Kapazitäten und von CPU führt. Stanford und Facebook haben 2015 eine Studie zur Flash-Disaggregation basierend auf der Infrastruktur von Facebook produziert. Diese Studie hat detailliert die Auslastung der Flash-Kapazität, des Lesedurchsatzes und der CPU in der gesamten Infrastruktur gezeigt und eine enorme Ineffizienz aufgedeckt. Datenservices wie Snapshots, Replikation, globale Deduplizierung und Thin Provisioning sind in der DAS-Architektur nicht vorhanden, was zu weiterer Ineffizienz bezüglich Kapazität und Betrieb führt.

Beim Hyperscale ist Effizienz eine wichtige Voraussetzung. Am Anfang gab es die „webbasierte“ Lösung. Das war der einfache und unkomplizierte Weg zur Skalierung. Unsere hyperkonvergenten Freunde befinden sich immer noch in dieser frühen Entwicklungsphase. Wie Sie bei der Stanford-Studie zur Disaggregation von Flash-Storage sehen konnten, war diese Art von Architektur unreif und wies ein verhältnismäßig hohes Maß an Ineffizienz auf. Um eine unabhängige Skalierung von Berechnung und Storage zu ermöglichen, wurden viele Hyperscale-Umgebungen auf „Rack-Scale-Disaggregation“ umgestellt. Dadurch war es weiterhin möglich, bei gesteigerter Effizienz ein Standard-Rack für die Skalierung zu erhalten. Die vollständige Disaggregation verschiebt Storage und Berechnung auf vollständig getrennte Racks, auf die über hochoptimierte Protokolle zugegriffen wird, und verleiht ihnen die besten Wirkungsgrade im Ultrascale-Bereich.
Während die Disaggregation heute nach einem nahe liegenden Schritt klingen mag, gab es immer eine große Hürde für den gemeinsamen Storage:
- Liefern der gleichen Performance-Ergebnisse wie Direct Attached Storage (unter 300 Mikrosekunden)
- Erreichen von geringer Latenz über Fast Ethernet, da Fibre Channel in den meisten dieser Hyperscale-Lösungen keine Option ist.
DIRECT FLASH FABRIC OPTIMIERT DEN ZUGRIFF AUF DIE ANWENDUNG
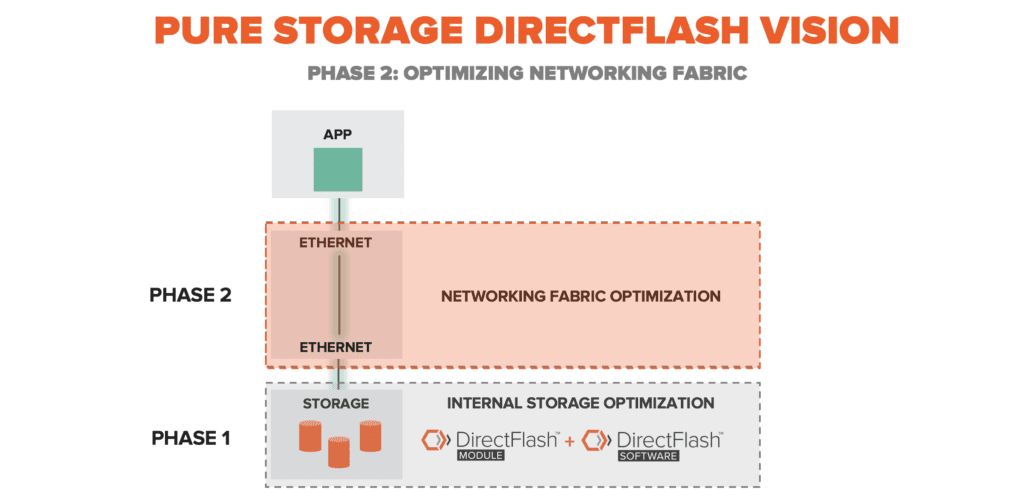
Mit Datenservices der Enterprise-Klasse ist eine extrem niedrige Latenz nur schwer erreichbar. Bei Pure war es unsere Vision, zuerst alle älteren Protokolle aus dem Array zu entfernen, da diese den größten Engpass darstellten. Wir haben zwei neue Produkte entwickelt, um dies zu unterstützen: das DirectFlash™-Modul (unser eigenes, benutzerdefiniertes, NVMe-basiertes SSD) und unsere DirectFlash-Software (eine softwaredefinierte Schnittstelle direkt zu NAND). Diese Neuerungen haben enorme Performance-Steigerungen innerhalb des Arrays und große Vorteile für Anwendungen mit sich gebracht. Weitere Informationen zu DirectFlash finden Sie unter DirectFlash – ermöglicht Software und Flash die direkte Kommunikation und DirectFlash Deep Dive. Nun trennt uns nur noch die Netzwerkstruktur von der Anwendung.

Wir freuen uns sehr, DirectFlash™ Fabric vorzustellen, das die DirectFlash™ -Familie mittels RDMA over converged Ethernet (auch bekannt als RoCEv2) über das Array hinaus und in die Fabrics bringt. Damit werden die Anforderungen von Flash-Disaggregation mit extrem niedriger Latenz (Zugriff in 200 – 300 Mikrosekunden) und End-to-End-NVMe erfüllt, was den Zugriff von Anwendungen auf ein FlashArray umfassend revolutioniert. DirectFlash Fabric ist ab dem 16. Januar 2019 mit einem Firmware-Upgrade und der Installation eines RDMA-fähigen NICs in den Storage-Controllern allgemein verfügbar. All dies kann auf einem bestehenden FlashArray unterbrechungsfrei und ohne Auswirkungen auf die Performance oder Wartungsfenster durchgeführt werden. Die Ergebnisse weisen im Vergleich zu iSCSI eine bis zu 50 % geringere Latenz und eine bis zu 20 % höhere Geschwindigkeit auf als Fibre Channel, das als schnellster Fabric für Enterprise-Anwendungen bekannt ist. Die RMDA-Auslagerung führt zu 25 % CPU-Entlastung, was der Anwendung mehr CPU für mehr Ergebnisse zur Verfügung stellt.

DirectFlash Fabric ist die Fortsetzung der branchenführenden NVMe-Innovation von Pure. Wir haben 2015 als Erste auf dem Markt auf unserer Plattform mit unseren NVRAM-Geräten die Grundlage für NVMe geschaffen, um unsere Stateless-Architektur zu ermöglichen. 2017 waren wir die Ersten, die einen 100-prozentigen NVMe-All-Flash-Array lieferten. 2018 waren wir die Ersten, die ein Erweiterungs-Shelf mit NVMe over Fabrics sowie ein 100-prozentiges NVMe-Portfolio von Produkten zu den gleichen Kosten wie unsere Nicht-NVMe-Produktlinie lieferten. Heute liefern wir das erste Array der Enterprise-Klasse mit NVMe over Fabrics über RDMA over converged Ethernet mit vollständigen Datenservices.

Die Optimierung der Netzwerk-Fabric mit NVMe over Fabric ist eine Weiterentwicklung. Heute hat Linux einen soliden, ratifizierten Treiber für NVMe over Fabric. Native Cloud-Anwendungen, wie z. B. MongoBD, Cassandra, MariaDB, Hadoop und Splunk, haben die folgenden Eigenschaften:
- Werden normalerweise unter Linux eingesetzt
- Nutzen hauptsächlich Direct Attached Storage (DAS)
- Werden in einem schnellen Ethernet-Netzwerk ausgeführt
- Weisen viele Ineffizienzen auf
Diese Apps sind gute erste Kandidaten für NVMe over Fabrics. Daher haben wir bei Pure beschlossen, uns zunächst auf RDMA over Converged Ethernet zu konzentrieren. Im Moment profitieren die Kunden hier am meisten und der Markt ist bereit dafür. Fibre Channel wird als Nächstes folgen, sobald Unternehmensanwendungen und Betriebssysteme vollständig unterstützt werden. Derzeit gibt es leider nur minimale Unterstützung, sodass dies weniger relevant ist. Wir planen, NVMe over Fibre Channel Ende 2019 bereitzustellen, wenn VMware und andere Unternehmensanwendungen bereit dafür sind. NVMe over TCP wird als Letztes bereitgestellt und soll 2020 ausgeliefert werden, um NVMe allen anderen zur Verfügung zu stellen.
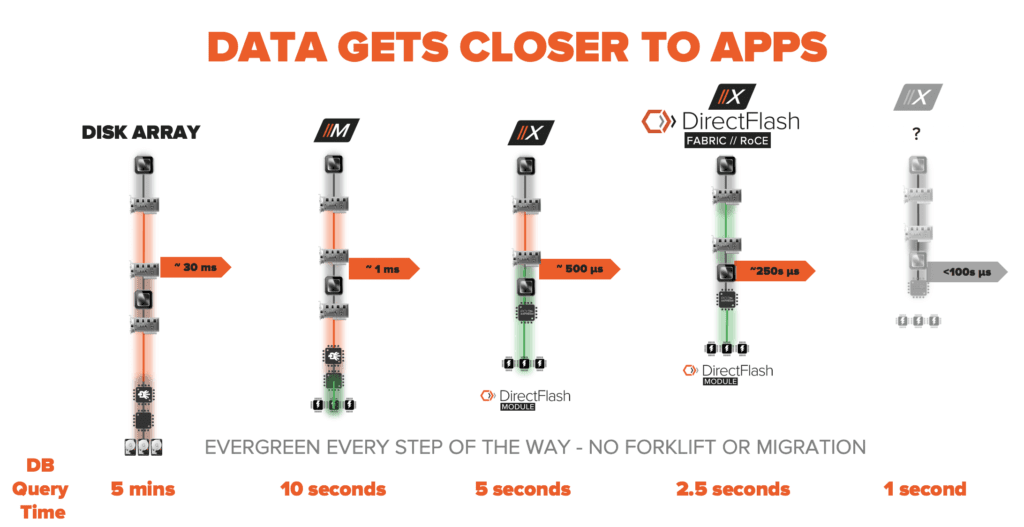
DIRECTFLASH-FABRIC BIETET VORTEILE FÜR ANWENDUNGEN UND BETRIEB
Um Ergebnisse in kürzester Zeit zu liefern, müssen die Daten näher an die Anwendung herangebracht werden. Betrachten wir die Ergebnisse der technologischen Revolution von Pure, bei der der veraltete SCSI-Zugriff vollständig entfernt und der gesamte Stack mit der NVMe-Technologie der nächsten Generation optimiert wurde. Stellen Sie sich vor, Sie verfügen über eine Datenbank, mit der Ihre Back-end-Anwendung ausgeführt wird. Sehen Sie sich die Entwicklung der Reaktionszeit bei Abfragen an.
- Festplatten-Array = 5 Minuten bei 30 Millisekunden Latenzzeit
- All-Flash-Arrays = 10 Sekunden bei 1 Millisekunde Latenzzeit
- Internes DirectFlash (Modul/Software) = 5 Sekunden bei 500 Mikrosekunden Latenzzeit
- Externe DirectFlash-Fabric = 2,5 Sekunden bei 250 Mikrosekunden Latenzzeit
Damit ist die Entwicklung aber noch nicht abgeschlossen. Wir erwarten, dass wir dieses Ergebnis im kommenden Jahr mit einem umfassenden und ständig laufenden Datenservice der Enterprise-Klasse auf 1 Sekunde (in Echtzeit) reduzieren können. Das Beste daran ist, dass unsere Kunden alle Vorteile dieser Entwicklung ohne umfassendes Upgrade oder Migration nutzen konnten. Durch unser Evergreen™-Storage-Verbrauchsmodell erhalten Kunden diese neuen Funktionen durch ein Firmware-Upgrade oder einen Controller-Austausch (nur mit Inkrementalkosten).

Native Cloud-Anwendungen können mit End-to-End-NVMe-over-Fabric auch im Vergleich zu SAS-DAS-Lösungen eine erhebliche Verbesserung der Performance leisten. In unseren Tests verzeichnen wir:
- Bis zu 50 % Verbesserung der Operationen pro Sekunde auf MongoDB
- Bis zu 30 % Verbesserung der Latenz und 30 % Verbesserung der Operationen pro Sekunde auf Cassandra
- Bis zu 33 % mehr maximale Transaktionen auf MariaDB

Es geht nicht nur um Performance. Die operative Effizienz des gemeinsamen Storage der Enterprise-Klasse ermöglicht neue Prozesse, die mit DAS nie möglich waren. Stellen Sie sich vor, Sie benötigen mehr Lese-Performance und schalten zusätzliche Knoten für zusätzliche Performance während einer Spitzenzeit dazu. Mit DAS haben Sie nur die Option, ein paar weitere Knoten hinzuzufügen, neue Replikate zu erstellen und dann stundenlang zu warten, bis sie synchronisiert sind. Mit DirectFlash Fabric können Sie sofortige Snapshots nutzen, sie auf den zusätzlichen Knoten mounten und sofort skalieren. Es wird keine zusätzliche Kapazität benötigt, da die Snapshots platzsparend sind und Änderungen am Snapshot dedupliziert und in die globale Datenpopulation auf dem Array komprimiert werden.

Wie wäre es mit der Entwicklung einer neuen Test- oder Entwicklungsumgebung auf Basis der aktuellen MongoDB-Produktionsdaten? Mit DAS müssten Sie die Daten kopieren oder aus einer Sicherung wiederherstellen. Mit DirectFlash Fabric können Sie Instanzen sofort aus einem Snapshot heraus erstellen, ohne die Produktion zu beeinträchtigen und ohne zusätzliche Kapazitäten zu benötigen. All dies kann über unsere REST-API automatisiert werden.

Mit der Disaggregation von DAS mit DirectFlash Fabric können Sie verlorene CPU und Kapazität, die typischerweise bei DAS auftreten, konsolidieren und wieder nutzen. Zu diesen Effizienzgewinnen gehören:
- 2- bis 4-fache CPU-Dichte mit Verschieben von 2 bis 4 Servern mit Rack-Einheiten in 1 Rack-Einheit oder Blade-Server. Dies erhöht die Rechendichte für mehr Ergebnisse in kürzerer Zeit.
- 4- bis 10-fache Kapazitätsdichte pro Rack. FlashArray kann 3 PB an Kapazität in 6 Rack-Einheiten packen.
- Mit einer 25-prozentigen CPU-Entlastung wird die Rechendichte immer effizienter, da ein Großteil der Storage-IO-Vorgänge auf die Hardware ausgelagert wird.
All dies wird mit Datenservices der Enterprise-Klasse geliefert, um Datensätze auf die effizienteste Form zu reduzieren und Kosten zu senken.

Für Kunden, die Anwendungen über eine konvergente Infrastruktur bereitstellen möchten, können wir End-to-End-NVMe über Fabric FlashStack™ ankündigen. Dazu gehören Cisco Nexus-Switching, FlashArray///X-Storage und Cisco UCS C-Series-Server. Das macht die Bereitstellung einer Hyperscale-Architektur in Ihrer privaten Cloud einfach und unkompliziert.

UNTERNEHMEN SIND NUN BEREIT FÜR HYPERSCALE
Jetzt können alle Anwendungen die Vorteile von FlashArray nutzen und Unternehmen dabei unterstützen, Ergebnisse in kürzester Zeit zu liefern. Für herkömmliche Unternehmensanwendungen bringt unsere Back-end-NVMe-Optimierung enorme Vorteile. Bei nativen Cloud-Anwendungen führen unsere End-to-End NVMe-Optimierungen nicht nur zu erheblichen Verbesserungen der Performance, sondern führen auch die Hyperscale-Architektur in das Unternehmen ein.
Um mehr über DirectFlash Fabric, unser Partner-Ökosystem und die Vorteile für Anwendungen zu erfahren, lesen Sie die folgenden Blogs:
- Pure liefert DirectFlash Fabric: NVMe-oF für FlashArray
- Analyse der Möglichkeiten von MariaDB und DirectFlash Fabric
- Jenseits von DAS: MongoDB auf FlashArray mit NVMe-oF RoCE
- Hallo Big Data!!! Pure Storage FlashArray mit DirectFlash ist jetzt zertifiziert mit Hortonworks Data Platform v3.0.0.0
- Vorteile des Einsatzes von Cassandra auf FlashArray mit DirectFlash Fabric
- NVMe-oF-Support ist jetzt verfügbar!
- Konstante Performance mit FlashArray NVMe-oF und SQL Server Linux
- Oracle 18c läuft schneller auf Pure DirectFlash Fabric
- DirectFlash Fabric im Vergleich zu iSCSI mit Epic-Workload


