
Summary
Pure annonce la mise sur le marché de la toute première plateforme de stockage en mode bloc et fichier réellement unifiée. Dans cet article, découvrez les trois nouveaux domaines d’innovation et notre approche moderne.
Summary
Chaque nouvelle ère est souvent le théâtre de nouvelles révolutions. Découvrez FlashBlade//E, une nouvelle plateforme de stockage des données non structurées, 100 % flash et économique.


Le 26 avril, Pure Storage a annoncé la mise à disposition généralisée de la toute première plateforme de stockage en mode bloc et fichier réellement unifiée. La société innove dans trois nouveaux domaines :
- Stockage natif en mode bloc et fichier : FlashArray™ introduit une architecture en mode bloc et fichier basée sur un seul pool global de stockage, qui simplifie l’administration et permet de traiter les deux services sur un pied d’égalité. C’est la toute première plateforme en mode bloc et fichier réellement unifiée sur le marché.
- Datastore NFS : cette solution certifiée par VMware prend en charge les datastores NFS, s’intègre directement dans l’écosystème VMware pour l’automatisation et étend la consolidation des charges de travail au marché des systèmes de fichiers.
- Administration avec reconnaissance des MV : ce nouveau modèle permet une gestion granulaire des charges de travail pour les applications virtualisées basées sur des datastores NFS.
L’approche unifiée de FlashArray repose sur une architecture radicalement différente qui accroît la flexibilité et élimine la nécessité de pré-planification du déploiement. Vous pouvez ainsi configurer et consommer des ressources de manière dynamique sans avoir à anticiper l’impact potentiel. L’ensemble global de ressources élimine les diverses couches d’abstraction que l’on trouve généralement dans les baies multiprotocoles. Cette approche moderne du stockage unifié en mode bloc et fichier simplifie considérablement la consolidation des charges de travail.
Les fournisseurs traditionnels ne tiennent pas leurs promesses en matière de stockage unifié
Les fournisseurs traditionnels ont fait de nombreuses promesses concernant le stockage en mode bloc et fichier « unifié ». Ils se sont notamment engagés à consolider les charges de travail en mode bloc et fichier sur un nombre réduit de systèmes de stockage, afin d’améliorer l’utilisation (pour diminuer les dépenses d’investissement) et de simplifier les opérations ainsi que l’administration en limitant les points de terminaison de stockage (pour diminuer les dépenses d’exploitation).
Cependant, ils se sont contentés de reprendre les architectures existantes conçues pour un type de service (bloc ou fichier) et d’y ajouter un deuxième ensemble de protocoles de stockage. Cela a eu pour effet de créer un château de cartes.
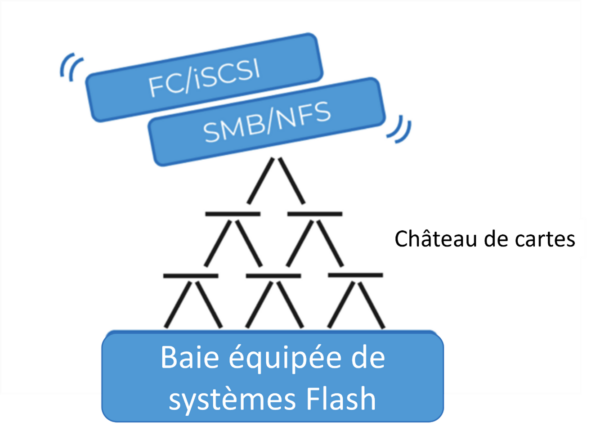
À première vue, ces systèmes multi-protocoles ont pour objectif de consolider les architectures disparates, mais cela ne permet pas de réduire les dépenses d’exploitation, contrairement à ce qui était annoncé. Face à une complexité accrue, les clients n’ont d’autre choix que de s’en tenir à un stockage dédié en mode bloc ou fichier pour la plupart de leurs charges de travail.
Problèmes liés à l’ajout de services de stockage
Dans les systèmes multi-protocoles traditionnels, l’architecture est conçue pour un seul type de service de stockage et les autres services sont ajoutés par-dessus. Prenez l’exemple des LUN mis en œuvre au sommet d’un système de fichier. En agissant ainsi, les fournisseurs privilégient un service de stockage (fichier) par rapport à un autre (bloc). Lorsque plusieurs couches d’abstraction sont nécessaires pour prendre en charge plusieurs protocoles, une administration est requise à tous ces niveaux. Cela rend la pile incohérente et complexe, on parle alors de gestion asymétrique. Si on veut modifier quoi que ce soit dans une pile multicouche, on se heurte souvent à des limitations et il faut faire des compromis entre les services, car ils ne peuvent pas être exploités indépendamment les uns des autres. L’architecture manque foncièrement de flexibilité.
Dans la plupart des cas, cela limite l’évolutivité, la capacité ne peut pas être utilisée efficacement ou les charges de travail doivent être copiées/déplacées vers d’autres volumes. Cela demande une planification minutieuse et continue, sans quoi il est impossible d’exploiter tout le potentiel des dépenses d’exploitation d’un système unifié.
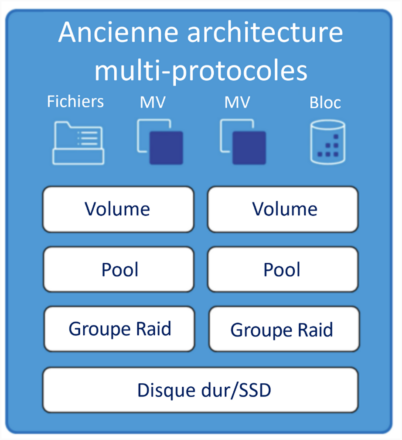
L’ajout de services de stockage limite encore l’évolutivité. Prenons l’exemple de l’architecture décrite dans la Figure 2. Les disques durs ou SSD (première couche) sont regroupés dans plusieurs groupes RAID (deuxième couche), eux-mêmes répartis dans des pools de stockage (troisième couche), qui ont leurs propres limites. Les pools de stockage sont ensuite divisés en volumes plus petits (quatrième couche) dont la taille est traditionnellement limitée (100 To). Enfin, les partages et LUN peuvent être créés (cinquième couche) et les données stockées.
Cette architecture multicouche est fondamentalement complexe, et la gestion répartie sur plusieurs couches accentue la complexité. Le principal problème réside dans le fait que la taille des structures de stockage, des pools et des volumes est traditionnellement limitée. Une planification importante à long terme est donc nécessaire si l’on veut éviter que les partages, des LUN ou des MV n’évoluent au-delà de la capacité du volume.
Une plateforme réellement unifiée dépend avant tout d’un pool global de stockage
Pour être véritablement unifiés, les services de stockage en mode bloc et fichier doivent être natifs et déployés à partir d’un pool global unique. Les services de fichiers FlashArray ont été conçus spécialement pour une plateforme de stockage 100 % flash, au même niveau que les protocoles en mode bloc. Chaque baie FlashArray dispose d’un pool global de stockage partagé avec les protocoles en mode bloc et fichier, ce qui élimine la complexité et la rigidité inhérentes aux solutions multiprotocoles traditionnelles. Les clients peuvent ainsi faire évoluer leurs données de fichiers de manière simple et flexible, sans les risques importants associés à la pré-planification ou à la post-production.
Cette approche sans couches multiples permet de tirer pleinement parti de tous les avantages de FlashArray, notamment de la déduplication globale, du chiffrement des données stockées, des mises à niveau matérielles et logicielles sans interruption et d’Evergreen®.
Les services de fichiers FlashArray remplacent le contrôle traditionnel des données au niveau du système de fichiers par des contrôles et une surveillance au niveau des répertoires pour permettre aux clients de gérer plus directement les charges de travail/applications. L’administration au niveau du répertoire et les configurations basées sur des règles permettent aux clients de gérer des fichiers à n’importe quelle échelle, et des politiques avec des opérations symétriques assurent la supervision de toutes les fonctions de gestion. Une fois que vous avez appris une politique, vous les connaissez toutes.
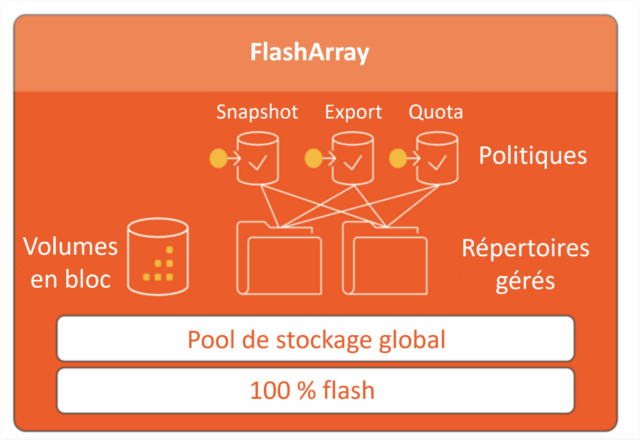
Les répertoires gérés peuvent avoir des politiques de snapshot, d’exportation et de quota séparées. Les administrateurs de stockage ont la possibilité de consulter les indicateurs de performance et l’espace de chaque répertoire. Chacun d’entre eux bénéficie d’un Thin Provisioning et se trouve dans le même pool de stockage global. De plus, les volumes en mode bloc peuvent occuper l’ensemble de l’espace utilisable sur la baie si nécessaire.
Une nouvelle approche des datastores NFS pour éviter la surcharge
Les clients doivent également pouvoir résoudre les problèmes de surcharge au niveau des snapshots. Certaines des plus grandes implémentations de machines virtuelles au monde utilisent des datastore NFS. Lorsqu’elles évoluent, elles subissent les conséquences de la mauvaise utilisation des ressources de stockage, car les politiques de snapshot n’ont qu’un accès restreint aux datastores NFS sous-jacents. Cela limite l’automatisation de la configuration et de la gestion, la taille des systèmes de fichiers et la protection des données au niveau du datastore.
Aujourd’hui, Pure annonce la prise en charge des datastores NFS VMware sur FlashArray. L’administration des datastore NFS est intégrée dans son plugin de pointe vSphere. Les clients peuvent désormais déployer un datastore NFS sans toucher à la baie. Des fonctionnalités de snapshots et de restauration de MV ont également été intégrées dans le plugin pour permettre aux administrateurs d’utiliser rapidement et facilement les snapshots natifs au niveau des MV, ce qui réduit considérablement la capacité nécessaire par rapport aux snapshots effectués au niveau du datastore qui encombrent les systèmes traditionnels.
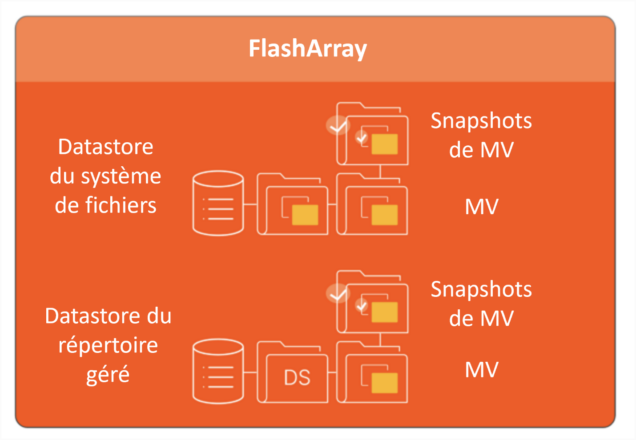
Les clients ne sont plus obligés d’effectuer des snapshots au niveau du datastore et peuvent désormais configurer des programmes de snapshot granulaires par MV ainsi que la rétention (les snapshots de datastore sont toujours disponibles si nécessaire, mais ne sont pas obligatoires). Les datastores ne sont pas non plus limités aux systèmes de fichiers et peuvent être créés dans n’importe quel répertoire géré, jusqu’au huitième niveau d’un système de fichiers.
Stockage avec reconnaissance des MV : une visibilité approfondie sur le niveau de granularité de la machine virtuelle, inédite dans le secteur
La prise en charge des datastores NFS nous a également permis d’offrir le même niveau de gestion et de maîtrise granulaire qu’avec le stockage en mode bloc. Le système de fichiers n’est plus une « boîte noire ». Les datastores NFS avec reconnaissance des MV offrent une meilleure visibilité sur la granularité de la machine virtuelle. Tout cela est possible grâce aux répertoires gérés. En appliquant une nouvelle politique à un répertoire du datastore appelé AutoMD, chaque MV créée dans ce datastore devient automatiquement un répertoire géré visible par FlashArray.
Les administrateurs peuvent désormais gérer les machines virtuelles de manière native sur FlashArray, y compris les statistiques au niveau des MV, les snapshots, les quotas et les politiques. Pour ce faire, les machines virtuelles et les répertoires gérés sont mappés automatiquement un par un lors de la création de la MV. Grâce aux statistiques avec reconnaissance des MV, vous pouvez explorer n’importe quel répertoire géré et comprendre ce qui se passe. Avec les quotas, vous pouvez assurer le contrôle granulaire de chaque MV, quel que soit l’emplacement, et les snapshots vous permettent de définir des politiques de protection des données granulaires pour chaque MV. Cette granularité vous donne plus de flexibilité, avec toujours autant de simplicité.
Le stockage réellement unifié enfin synonyme de réduction du TCO
Les services de fichiers FlashArray font entrer la toute première plateforme de stockage en mode bloc et fichier réellement unifiée sur le marché, éliminant la nécessité de prendre en charge plusieurs systèmes de stockage dédiés ou des systèmes multi-protocoles complexes. La consolidation et l’efficacité des données annoncent une diminution des dépenses d’investissement, tandis que l’architecture simple, les services natifs associés à un pool de stockage global et l’automatisation granulaire simplifiant la gestion promettent une réduction des dépenses d’exploitation.
Dans une récente étude sur la valeur économique, l’Enterprise Strategy Group (ESG) a démontré que la plateforme unifiée FlashArray réduisait les efforts de gestion de 62 %, ce qui se traduit par une réduction de 58 % du coût total de possession. Avec la perspective de telles économies, le moment n’est-il pas venu de passer à un système réellement unifié ?
Découvrez les avantages d’une plateforme de stockage en mode bloc et fichier réellement unifiée.
Written By:

