
Splunk è la piattaforma leader di mercato per la gestione dei Machine Data, ovvero di tutte quelle informazioni generate da sistemi, server, apparati e sensori, applicazioni, tipicamente sotto forma di log file. 90 aziende su 100 della lista Fortune100 usano Splunk.
Con questo articolo mi propongo di analizzare i vantaggi dell’utilizzo combinato di Splunk SmartStore con Pure Storage FlashBlade. Nei paragrafi successivi capiremo il perché di questa intersezione fra il recente modello architetturale di Splunk (SmartStore, appunto) e il nostro storage all-flash scale out ad alte prestazioni (FlashBlade).
Ripercorreremo assieme le sfide causate dall’esplosione dei dati generati all’edge, le necessità moderne di volerli analizzare e le complessità di far scalare architetture tecnologiche disegnate lustri fa. Vedremo anche quali sono i vantaggi dei paradigmi architetturali moderni che realizzano in pieno una “Modern Data Experience”.
L’analisi dei “Machine Data”
L’aumento esponenziale dei Machine Data associato alla capacità di poterli analizzare e ricercare, offrono alle aziende una maggiore capacità di interpretare fenomeni di business e comprendere indicatori di performance interne.

Tramite la raccolta e correlazione di questi dati, ad esempio, è possibile identificare in maniera efficace minacce alla sicurezza informatica oppure generare alerting intelligente e anche analizzare in maniera proattiva la propria infrastruttura alla ricerca di problemi prestazionali end-to-end.
In molti casi la visibilità sui dati di applicazioni di business si traduce anche in una grande opportunità di poter sviluppare più rapidamente nuovi prodotti o individuare più facilmente opportunità di business o di efficienza operativa.
Proprio per questi motivi, in molte aziende, Splunk è diventato una risorsa mission-critical.
Il modello tradizionale distribuito scale-out
Il modello architetturale e di deployment in modalità “indexer cluster” della versione tradizionale Enterprise, noto anche come modello distribuito scale-out, garantisce alta affidabilità ma presenta anche delle sfide significative in termini di costo, soprattutto al crescere dei volumi dei dati da gestire.
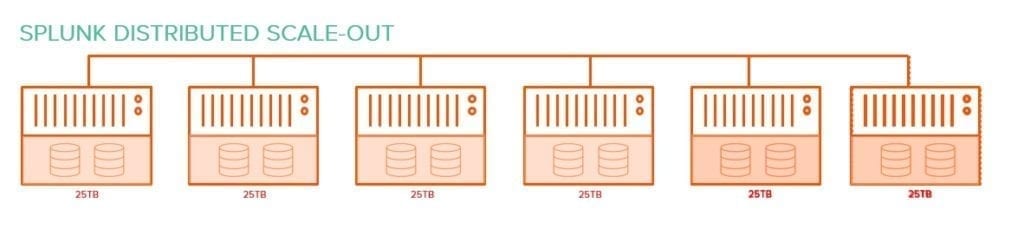
Questo modello prevede una architettura connotata da un forte accoppiamento delle risorse di compute e di storage. Con l’esplosione del volume dei dati da trattare, in realtà, potrebbe essere necessario far crescere esclusivamente il volume di storage, lasciando invariata la componente di compute.
Su larga scala, infatti, l’approccio di aggiungere compute e storage accoppiati in risposta al solo aumento della domanda di storage è subottimale e altamente proibitivo. Pertanto, è indispensabile disaccoppiare queste risorse per fornire una soluzione più efficiente ed economica.
Si sta affermando un consenso sia fra gli analisti sia nel mercato che il paradigma del disaccoppiamento sia la scelta ottimale.
“Decoupling compute and storage is proving to be useful in Big Data deployments. It provides increased resource utilization, increased flexibility, and lower costs.” – Ritu Jyoti, research director, IDC’s Enterprise Storage, Server, and Infrastructure Software team
Le carenze del modello tradizionale distribuito scale-out
Approfondiamo questo tema analizzando tre sfide delle implementazioni del modello distribuito scale-out. Queste sono le sfide che tipicamente gli utilizzatori di Splunk Enterprise si trovano a dover gestire nel momento in cui desiderano far scalare la piattaforma. Vedremo poi i vantaggi di usare l’architettura SmartStore che è stata progettata ad-hoc proprio per minimizzare o eliminare queste problematiche.
Aumento dei costi di infrastruttura
Il modello tradizionale garantisce alta affidabilità del dato attraverso meccanismi di replica che necessariamente richiedono maggiore capacità storage. Inoltre, essendo le risorse di compute e storage aggregate, se si necessita di scalare, aumentando lo storage, è necessario approvvigionare entrambe perché sono co-locate sulla stessa infrastruttura. Se pensiamo che la maggior parte delle ricerche vengono eseguite su dati degli ultimi sette giorni (secondo Splunk oltre il 95% delle ricerche raramente superano i 7 giorni di aging) dunque su un sottoinsieme più piccolo di dati e molto raramente sull’intero set di dati. Questo significa che nella maggior parte dei casi le risorse di compute aggiunte sono fortemente sottoutilizzate.
Degrado delle prestazioni di ricerca
Nel modello tradizionale scale-out distribuito, le ricerche sono associate ad un significativo degrado delle prestazioni con l’aging del dato. A mano a mano che il dato diventa meno recente, viene suddiviso in livelli di archiviazione più economici e con prestazioni inferiori in bucket “warm” e “cold”. I bucket “cold” riducono drasticamente lo spazio di archiviazione, ma questo ha un impatto significativo sulle prestazioni di ricerca.
Questa politica di archiviazione non è pratica per tutte quelle casistiche in cui invece è necessario accedere a dati meno recenti, sto pensando a tutte le ricerche relative a normative o requisiti di compliance, cybersecurity e legali, tutti elementi che richiedono informazioni che hanno un orizzonte temporale che va aldilà dei dati più recenti, si può andare da un minimo di un mese fino diversi semestri.
Complessità infrastrutturale e overhead operativo
L’elevata disponibilità del dato tramite replica nell’architettura tradizionale richiede, inoltre, che tutte le repliche siano sempre online. Ciò significa che la manutenzione dei server e gli aggiornamenti software dei server degli index cluster debbano essere programmate e serializzate. Questo comporta procedure di evacuation dei dati, aggiornamento del software di base / applicativo e la reidratazione dei dati.
In secondo luogo, l’espansione del cluster e gli eventuali hardware refresh richiedono attività di ribilanciamento dei dati (a volte più di una). Infine, in caso di guasto di un nodo indexer, è necessario ricostruire i dati nel nodo stesso.
Tali limitazioni dell’architettura aggiungono complessità, tempi e costi significativi, riducendo al contempo le prestazioni di ricerca e ingestion a causa della perdita di risorse compute e/o del processo di migrazione o ricostruzione dei dati.
I vantaggi di Splunk SmartStore con FlashBlade
Splunk SmartStore, l’ultima evoluzione di questo modello, offre maggiore flessibilità nelle risorse di compute e storage insieme a un’infrastruttura di gestione dei dati più semplice e flessibile. Tutto questo può aiutare sia a ridurre i costi sia ad aumentare i livelli di efficienza operativa.

Il nuovo modello si basa su uno storage a oggetti che può essere posizionato anche su storage remoto. Poiché la disponibilità e l’affidabilità del dato è affidata a storage remoto centralizzato, la scelta della piattaforma di object store è fondamentale. Ecco dove entra in campo FlashBlade con tutte le sue caratteristiche descritte in un mio post precedente.
Splunk SmartStore colloca dinamicamente il dato sia su storage locale o su storage remoto o su entrambi a seconda dei pattern di accesso, longevità del dato e priorità dato/indice. Usa API S3 per interagire con FlashBlade.
Disaccoppiando compute da storage, Splunk SmartStore offre anche un elevato grado di elasticità. A mano a mano che vengono caricati e conservati più dati, lo storage può essere ridimensionato in modo indipendente da compute.
A mano a mano che il volume di ricerca aumenta o si aggiungono più utenti, è possibile aumentare le prestazioni aggiungendo ulteriori risorse di compute. L’intero set di indexer nel cluster può anche essere arrestato / sostituito e successivamente ripristinato facendo un bootstrap dei dati dallo storage remoto, fornendo un elevato grado di flessibilità e controllo per gestire i costi dell’infrastruttura.
I vantaggi di una architettura SmartStore con FlashBlade
Analizziamo ora, uno ad uno, i benefici di questa architettura moderna.
Analisi più performanti indipendentemente dall’aging del dato
L’architettura di SmartStore elimina i bucket “cold” e aggiunge una nuova cache locale, ideale per la ricerca di dati recenti e/o cercati di recente. Tuttavia, l’utilizzo di soluzioni di storage a oggetti a basso costo e basse prestazioni con SmartStore limita le prestazioni di ricerca. Una soluzione SmartStore con FlashBlade offre prestazioni all-flash con ampiezza di banda e parallelismo elevati per operazioni su dati e ricerche anche all’esterno della cache di SmartStore. Assicura inoltre la possibilità di completare in modo efficiente attività critiche e non ripetitive relative a requisiti normativi o di conformità, violazioni della sicurezza informatica e legali. Inoltre, la larghezza di banda di FlashBlade è ideale per supportare le prestazioni di picco degli indexer SmartStore.
Minore costo totale di gestione
L’utilizzo di SmartStore con FlashBlade ottimizza l’utilizzo dell’infrastruttura e riduce i requisiti di storage e di compute rispetto all’architettura tradizionale di Splunk su risorse compute e Direct-Attached-Storage. Con questo approccio, è possibile dimensionare gli indexer in base al tasso di ingestion e ai volumi di ricerca anziché preoccuparsi dello storage. Inoltre, SmartStore richiede l’archiviazione di una singola copia dei dati “warm” e sfrutta l’efficienza del dato fornita dalla soluzione di storage. FlashBlade riduce i requisiti di storage a oggetti dal 30% al 40% grazie alla compressione dei dati.
Maggiore disponibilità e affidabilità
FlashBlade offre una protezione dei dati con codifica di cancellazione N + 2 altamente efficiente. La crittografia dei dati “at rest” consente a SmartStore di fornire una soluzione altamente disponibile e sicura. Splunk SmartStore non richiede di ricostruire dati “warm” se un indexer si arresta. Per soddisfare i parametri di replica e fattore di ricerca di Splunk, è solo necessario replicare i metadati tra i nodi nel cluster. Test interni di Pure hanno dimostrato che, in caso di failure di un nodo, nella soluzione SmartStore con FlashBlade, il nodo è rimasto offline per il 94% in meno di tempo rispetto a una classica architettura Splunk con un set di dati simile.
Gestione semplificata dei cluster Splunk su qualsiasi scala
SmartStore semplifica la gestione dei dati per soddisfare le crescenti esigenze attraverso: aggiunta di nodi a indexer, ribilanciamento dei dati e rimozione di indexer. Richiede solo la replica dei metadati tra i nodi nel cluster invece di richiedere la migrazione dei dati. Test interni di Pure testimoniamo come l’aggiunta di nodi e il ribilanciamento dei dati sono circa il 99,7% più veloci su SmartStore con FlashBlade rispetto a Splunk classico.
Gli aggiornamenti degli indexer vengono eseguiti in parallelo. Una soluzione SmartStore con FlashBlade può espandersi senza problemi sia per quanto riguarda il clustering dell’indexer sia la capacità e le prestazioni dello storage ad oggetti di FlashBlade. Questa ridotta complessità operativa consente agli amministratori di Splunk di concentrarsi sul monitoraggio dell’ingestion e dell’indicizzazione delle prestazioni senza perdere tempo a gestire l’infrastruttura.
Conclusioni
L’uso di Splunk SmartStore con Pure Flashblade, accelera le ricerche con un’architettura all-flash, cloud native, riducendo al contempo costi generali, incremento della disponibilità e miglioramento dell’efficienza operativa.
Vi invito a scaricare il solution brief che spiega come usare Pure Storage con Splunk SmartStore e ad approfondire la soluzione FlashBlade alla pagina principale.
Contattatemi per ulteriori informazioni, sarò felice di aiutarvi.
Luca Rossetti Systems Engineer
T @lucaR055



